
Бесплатный фрагмент - Основы программирования в СУБД Oracle
SQL+PL/SQL.
Предисловие
Почему и для чего написана эта книга? Этот вопрос я задаю сам себе, и его может задать потенциальный читатель, для того чтобы принять решение — стоит ли тратить деньги на ее приобретение и время на ее изучение.
Я преподаю дисциплину «Базы данных» в Московском авиационном институте уже почти 30 лет. Начинал в 90-х с использования СУБД dBase III, которая работала под управлением операционной системы DOS.
В начале 2000-х было принято решение использовать в учебном процессе СУБД с архитектурой «клиент — сервер» и уделять больше внимания вопросам программирования.
Выбор осуществлялся между СУБД Microsoft SQL Server и СУБД Oracle. Предпочтение было отдано продукту фирмы Microsoft по следующим причинам:
• Существовала официально бесплатная версия этой СУБД, также в то время мы могли бесплатно использовать в учебном процессе промышленные версии этой программы.
• СУБД Microsoft SQL Server позволяла использовать кириллицу в названиях таблиц и столбцов, и в ней была локализована среда разработки программ Management Studio. В СУБД Oracle в то время использовался режим командной строки, который менее эффективен.
• Имелось много книг на русском языке, в которых рассматривались принципы работы с СУБД Microsoft SQL Server и разработка программ с ее использованием. Здесь я имею в виду SQL и его расширение Transact SQL. Подобной литературы на русском языке для СУБД Oracle практически не было.
Но тем не менее в 2015 году было принято решение перейти на использование в учебном процессе СУБД Oracle. Одной из причин такого перехода стало то, что знание и умение работать с СУБД Oracle на рынке труда оценивается выше. Также к этому времени появилась бесплатная версия Oracle Database Express Edition и стала использоваться визуальная среда разработки программ Oracle SQL Developer.
Но положение с литературой на русском языке, которую можно использовать при изучении СУБД Oracle, существенным образом не изменилось. Особенно это касается изучения PL/SQL.
Правда, здесь нельзя не отметить великолепную книгу «Oracle PL/SQL. Для профессионалов», авторами которой являются Стивен Фейерштейн и Билл Прибыл. Эта книга неоднократно переиздавалась и пользуется всеобщим и заслуженным уважением в среде программистов. Но ее сложно использовать при первоначальном изучении этого языка, так как можно легко «захлебнуться» от обилия содержащейся в ней информации.
Положение с литературой, которую можно использовать для изучения SQL, не столь критично. Во-первых, потому что для этого языка созданы стандарты, которых придерживаются производители СУБД; во-вторых, есть книги на русском языке, в которых рассматривается Oracle-версия SQL. Данные об этих книгах содержатся в списке литературы.
Так что первая причина, по которой я решил написать эту книгу, состоит в том, чтобы в ограниченном объеме рассмотреть синтаксис всех основных элементов SQL и PL/SQL и проиллюстрировать правила их использования интересными и функциональными примерами. Функциональными я называю примеры, которые позволяют понять, при решении каких задач целесообразно использовать рассматриваемый элемент языка.
Вторая причина обусловлена следующими обстоятельствами. Корпорация Oracle широко использует систему сертификации специалистов. Сертификационный экзамен проходит в форме сдачи теста. Поэтому практически во всех книгах, посвященных изучению PL/SQL, проверка понимания пройденного материала осуществляется путем тестирования.
С помощью тестирования можно оценить уровень знаний, но решение интересных задач развивает творческие способности и готовит к практической работе. В реальной жизни нужно писать программы, а не отвечать на вопросы теста.
Но это не два взаимоисключающих подхода, а два этапа обучения. На первом этапе нужно научиться писать код, а на втором — систематизировать полученные знания и показать свой уровень подготовки путем сдачи тестов.
И если по SQL можно легко найти задачи, предлагаемые для самостоятельного решения, то по PL/SQL я не нашел ни одного источника, который можно было бы использовать в качестве задачника.
Поэтому в данной книге в конце каждого раздела предлагаются для самостоятельного решения задачи различной степени сложности. Решение этих задач позволит лучше понять правила использования рассматриваемого элемента языка и получить практические навыки программирования. Многие вопросы становятся понятнее, если они прошли через кончики пальцев.
Надеюсь, что освоение материала, изложенного в этой книге, заложит хорошие основы для дальнейшего изучения СУБД Oracle и ее практического пользования.
Введение
Одним из определяющих факторов успеха в любой сфере деятельности современного общества является наличие эффективных средств хранения и обработки данных. Для решения этой проблемы создаются информационные системы различного назначения. В подавляющем большинстве случаев для хранения информации в этих системах используются базы данных.
Концепция баз данных предполагает применение специального программного обеспечения для создания, манипулирования и управления объектами базы данных. Программное обеспечение, предназначенное для решения этих задач, получило название системы управления базами данных (СУБД).
Создание СУБД является великим изобретением в сфере обработки информации, которое позволило многократно повысить эффективность обработки данных.
Большинство современных СУБД используют реляционную модель данных. Однако известно, что автор реляционной модели, Эдгар Кодд, был недоволен использованием термина «реляционная модель» в названии существующих СУБД, так как считал, что правила хранения и обработки данных в этих СУБД не полностью соответствуют требованиям реляционной модели. Он называл такие СУБД псевдореляционными и считал, что нужно использовать более эффективные, истинно реляционные СУБД.
Но на практике этого не произошло, наоборот, в настоящее время считается общепризнанным факт, что только часть данных, которые необходимо обрабатывать, являются структурированными. Поэтому сейчас разрабатываются — и уже разработаны — СУБД, способные обрабатывать различные виды данных. Однако и в этих СУБД обработка структурированных данных играет важнейшую роль.
К настоящему времени создано и используется значительное количество СУБД. Однако ответить на вопрос, какая СУБД является наилучшей, вряд ли возможно. Для каждой области применения существует своя «оптимальная» СУБД, и выбор является многокритериальной задачей. При выборе СУБД следует в первую очередь учитывать следующие критерии: быстродействие, надежность, стоимость, сложность эксплуатации, наличие эффективных средств разработки приложений.
Почему была выбрана СУБД Oracle? Кроме уже упоминавшегося в предисловии хорошего соотношения спрос/предложение на рынке труда, изучение принципов обработки данных в среде этой СУБД актуально по следующим причинам. Во-первых, PL/SQL, используемый для обработки данных, имеет в своем составе широкий спектр конструкций, позволяющих эффективно решать эти задачи. К таким конструкциям, которые рассматриваются в этой книге, можно отнести курсоры, коллекции, динамические SQL и PL/SQL. Во-вторых, характерной особенностью СУБД Oracle является возможность хранения и обработки различных видов данных: структурированных, текстовых, графических, аудио и видео. В-третьих, корпорация Oracle в настоящее время активно развивает облачные технологии обработки данных и предоставляет доступ к этим технологиям. Поэтому освоение принципов обработки данных в среде СУБД Oracle облегчит изучение и использование этих технологий
Почти все современные СУБД используют для создания, управления и манипулирования данными язык структурированных запросов — Structured Query Language (SQL). Однако возможности, которые предоставляет SQL, недостаточны для решения ряда сложных задач. Поэтому большинство СУБД используют языковые расширения SQL, которые позволяют использовать средства процедурных языков программирования — переменные, условные операторы, операторы циклов — совместно с операторами SQL
В СУБД Oracle для этого используется процедурный язык программирования PL/SQL. Это сокращение от «Procedural Language extensions to the Structured Query Language», что в переводе с английского языка означает «процедурные языковые расширения для структурированного языка запросов».
Обработка данных, содержащихся в базе, может осуществляться как средствами самой СУБД, так и средствами приложений, взаимодействующих с базой данных. Основное назначение PL/SQL состоит в разработке хранимых процедур и функций, которые осуществляют обработку данных на сервере.
В процессе работы над книгой была использована Oracle Database 18c Express Edition. Эта версия бесплатна, но обладает широкими функциональными возможностями. Разработка, отладка и выполнение SQL-запросов и программ PL/SQL осуществлялись средствами визуальной среды Oracle SQL Developer версии 19.1.0.
ЧАСТЬ 1. ОПИСАНИЕ ИСПОЛЬЗУЕМОЙ БАЗЫ ДАННЫХ И СРЕДСТВ РАЗРАБОТКИ
Глава 1. Схема базы данных и среда разработки Oracle SQL Developer
Схема базы данных
Схема базы данных представляет собой графическое представление таблиц базы данных и связей, существующих между таблицами. По своему функциональному назначению схема базы данных является чем-то средним между блок-схемой алгоритма и чертежами архитектора. Они часто являются частью технического задания и элементом выходной документации. Поэтому программист, работающий с базой данных, должен понимать условные обозначения, используемые в этих схемах.
В этой книге для создания схемы базы данных использовалась программа Oracle SQL Developer Data Modeler. На рисунке 1.1 показан фрагмент схемы, созданной с помощью этой программы.
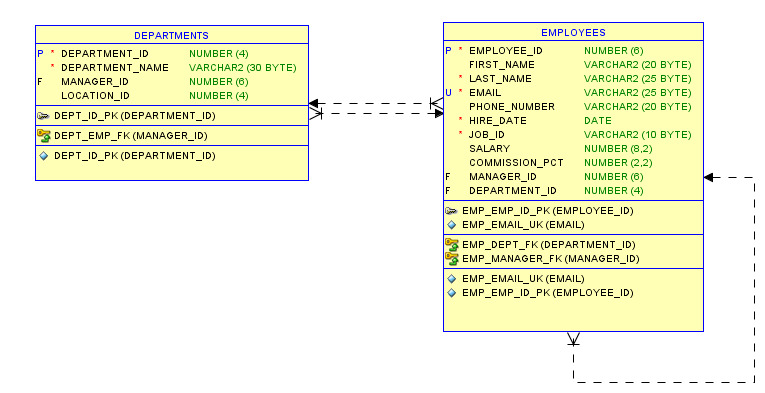
Рисунок 1.1. Фрагмент схемы базы данных
Буквой P отмечены столбцы, которые являются первичными ключами, а буквой F — столбцы, являющиеся внешними ключами. Связь между таблицами создается путем задания ограничения внешнего ключа.
Например, в приведенном фрагменте связь между таблицами Employees и Departments установлена путем определения ограничения внешнего ключа для столбца department_id в таблице Employees. Это означает что значение столбца department_id в таблице Employees должно совпадать с одним из значений одноименного столбца в таблице Departments или иметь значение NULL. За соблюдением этого ограничения будет следить СУБД и не допустит его нарушения. Буква U означает, что для этого столбца установлено ограничение уникальности значения. Это значит, что значение столбца не может повторяться. Символом * отмечены столбцы, которые не могут иметь значения NULL.
При создании SQL-запросов и программ PL/SQL нужно иметь четкое представление о структуре базы данных, с которой вы работаете, и знать бизнес-правила и ограничения, которые существуют в предметной области. Часть ограничений может быть реализована средствами языка определения данных, за их соблюдением будет следить СУБД и не допускать нарушения этих ограничений. Но существуют бизнес-правила и ограничения, которые должен отслеживать и обеспечивать программист.
Основу используемой в этой книге базы данных составляют таблицы демонстрационной базы СУБД Oracle Human Resources (HR). Human Resources — база данных, в которой хранятся данные отдела кадров некоторой компании. На рисунке 1.2 представлены основные таблицы этой базы данных и показаны связи между ними.
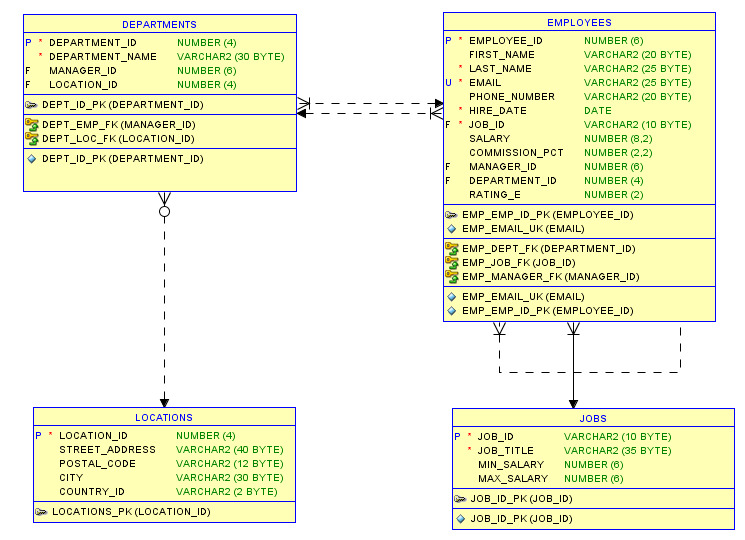
Рисунок 1.2. Основные таблицы базы данных Human Resources
Рассмотрим назначение этих таблиц и свойства некоторых столбцов. В таблице Employees содержатся данные о сотрудниках. Каждый сотрудник компании имеет уникальный идентификационный номер (employee_id), идентификационный номер должности (job_id), ставку заработной платы (salary) и менеджера (manager_id). Некоторые сотрудники в дополнение к зарплате получают комиссионные (commission_pct). Размер комиссионных определяется как часть от заработной платы. Столбец job_id используется для установления связи с таблицей Jobs, и для него определено ограничение внешнего ключа. Следствием этого является то, что значение данного столбца должно совпадать с одним из значений столбца job_id в таблице Jobs или иметь неопределенное значение NULL. Это ограничение обеспечивается средствами СУБД. Аналогичными свойствами обладает столбец department_id, который используется для установления связи с таблицей Departments.
В таблице Jobs содержится информация обо всех возможных должностях в организации. Каждая должность имеет уникальный идентификационный номер (job_id), наименование (job_title), минимальную (min_salary) и максимальную ставку заработной платы (max_salary).
Данные об отделах содержатся в таблице Departments. Каждый отдел имеет уникальный код (department_id), руководителя (manager_id), наименование (department_name), а также одно место расположения (location_id). Значение столбца manager_id должно совпадать со значением столбца employee_id в таблице Employees.
Эта компания имеет распределенную структуру, поэтому в таблице Locations хранятся данные о местонахождении отделов, которые состоят из адреса (street_address), почтового индекса (postal_code), названия города (city), названия штата (state_province) и кода страны (country_id). В таблице Locations также содержатся данные о населенных пунктах, в которых пока нет отделов.
Для того чтобы расширить спектр рассматриваемых задач, к уже рассмотренным таблицам были добавлены таблицы: Products, Orders, Customers Эти таблицы используются во многих демонстрационных базах. После добавления этих таблиц была получена схема базы данных HR_POC, используемая в этой книге, рисунок 1.3. Неиспользуемые таблицы были удалены. Ссылка для скачивания этой схемы: HR_POC (https://yadi.sk/d/_cFzi0CMazFIdg).
При решении некоторых задач, рассматриваемых в этой книге, в базу данных были добавлены вспомогательные таблицы. Ссылка для скачивания схемы, которая содержит вспомогательные таблицы:HR_POC_T (https://yadi.sk/d/a3XxApDuj2Ksxw).
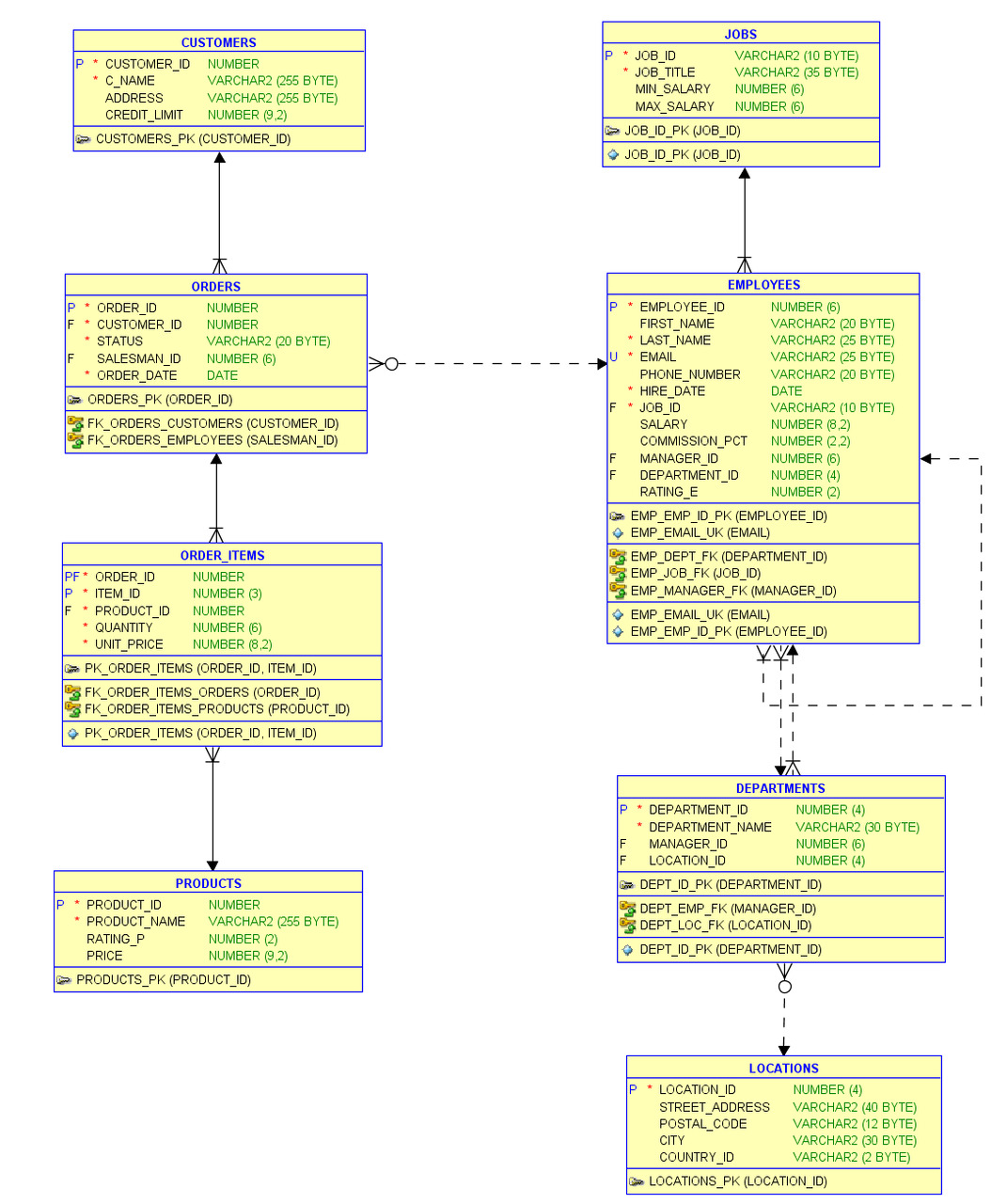
Рисунок 1.3. Схема базы данных HR_POC
Разберем назначение некоторых столбцов в таблицах Products, Orders, Customers и сформулируем бизнес-правила, которые могут быть определены с их использованием.
Столбец status в таблице Orders определяет состояние заказа и может принимать следующие значения: Pending — «в ожидании», Shipped — «отправлен», Canceled — «отменен». Используя этот столбец, сформулируем следующее бизнес-правило: можно изменить содержимое заказа, который находится в состоянии Pending, но нельзя изменить содержимое заказа, который находится в состоянии Shipped
Столбец credit_limit в таблице Customers содержит значение кредитного лимита клиента. Используя этот столбец можно сформулировать следующее правило: запретить оформление заказа, если общая сумма заказов клиента, находящихся в состоянии Pending, превышает его кредитный лимит. В этих таблицах отсутствуют данные об оплате заказов, поэтому будем считать, что заказы, находящиеся в состоянии Shipped, оплачены, а заказы, находящиеся в состоянии Pending, — нет.
Столбец price в таблице Products содержит текущую цену товара, а столбец unit_price в таблице Order_Items — цену, по которой он был продан. Разница между этими значениями может возникать из-за того, что клиенту предоставлена скидка. Также со временем значение price может измениться, а значение unit_price — нет.
В таблицу Employees был добавлен столбец rating_e. Значение элементов этого столбца целочисленные и должны лежать в диапазоне от 1 до 5. Будем считать, что значение столбца rating_e отражает квалификацию сотрудника.
В таблице Products содержится столбец rating_p. Значения элементов этого столбца также должны лежать в диапазоне от 1 до 5 и отражают сложность товара.
Используя эти столбцы, можно сформулировать следующее бизнес-правило: сотрудник имеет право продавать товары, рейтинг которых не превышает его рейтинга. Это бизнес-правило мы будем неоднократно использовать при решении задач.
Oracle SQL Developer
Oracle SQL Developer — это визуальная среда для создания, отладки и выполнения SQL-запросов и программ PL/SQL. Oracle SQL Developer позволяет создавать и редактировать объекты базы данных, управлять ими, импортировать и экспортировать данные, а также создавать всевозможные отчеты.
После запуска Oracle SQL Developer на экране появляется главное окно, представленное на рисунке 1.4.
Окно SQL Developer содержит три основные области:
— область Connections («Соединения») предназначена для создания соединений с базой данных;
— область Worksheet («Рабочее пространство») используется для ввода, редактирования и запуска запросов SQL и программ PL/SQL;
— область Reports («Отчеты») позволяет запускать предварительно определенные отчеты или создавать и добавлять собственные отчеты.
Рисунок 1.4. Главное окно Oracle SQL Developer
Для того чтобы приступить к работе с базой данных, необходимо создать соединение с ней. При запуске SQL Developer в области Connections отображаются все доступные соединения. Установить соединение можно только с существующей базой данных (схемой). Изначально после установки СУБД существует только схема администратора базы данных — system. Остальные схемы создает администратор. Имя схемы совпадает с именем пользователя. Команды создания пользователей и предоставления им привилегий будут рассмотрены позже.
Для создания нового соединения следует нажать кнопку New Connections, которая расположена на панели инструментов в области Connections. На экране появится диалоговое окно для создания подключений к базе данных (рисунок 1.5).
Имя соединения (Name) может быть произвольным, а имя пользователя и пароль должны быть предварительно заданы администратором. Имя пользователя должно начинаться с символов c##. Для одного пользователя (схемы базы данных) можно создать несколько соединений. При входе по любому из этих соединений вы будете работать с одной и той же базой данных. Значения Hostname и SID или Servce_name следует взять из файла tnsnames. ora в папке c:\app\user\product\18.0.0\dbhomexe\network\admin.
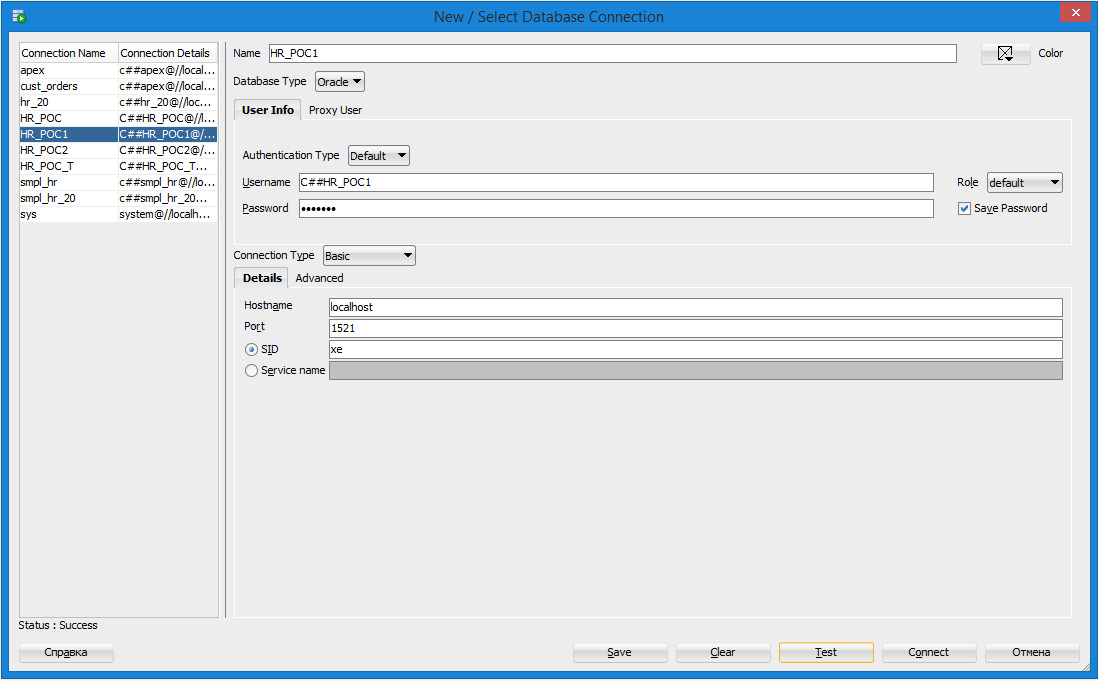
Рисунок 1.5. Окно для создания подключений к базе данных
После ввода всех параметров рекомендуется сначала нажать кнопку Test. Если проверка пройдет успешно, то в строке Status появится сообщение Success. В противном случае будет выведено сообщение об ошибке. Если ошибок не будет обнаружено, то следует нажать кнопку Connect и приступить к работе с базой данных.
После создания соединения с базой данных можно использовать область соединения для просмотра данных об объектах базы данных, включая таблицы, представления, индексы, пакеты, процедуры, триггеры.
Для того чтобы разорвать установленное соединение, следует щелкнуть на его имени правой кнопкой и в появившемся контекстном меню выбрать команду Disconnect.
Рассмотрим основные операции, которые можно выполнить, используя Oracle SQL Developer. Разберем случай, когда база данных уже создана, созданы таблицы и они заполнены данными. Нажав кнопку + рядом с именем соединения мы увидим объекты базы данных, для которой создано это соединение.
Самыми важными объектами базы данных являются таблицы. Для того чтобы увидеть список таблиц, существующих в базе данных, и получить возможность выполнять с таблицами различные действия, следует нажать кнопку + рядом с узлом Tables. Если после этого сделать двойной щелчок на имени таблицы, то в рабочей области появится окно, которое содержит несколько вкладок. Используя эти вкладки, можно просматривать данные о таблице и вносить в нее изменения.
На рисунке 1.6 показана вкладка Columns, в которой отображены столбцы таблицы Customers. Операции, которые вы можете выполнить с таблицей, содержатся в раскрывающемся списке Actions (рисунок 1.7).
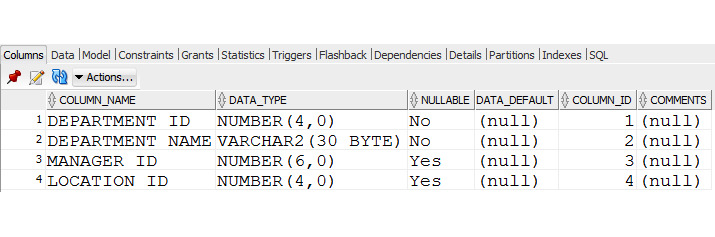
Рисунок 1.6. Вкладка Columns
Рисунок 1.7. Раскрывающийся список Actions
На вкладке Data (рисунок 1.9), где отображается содержимое таблицы, можно просматривать и редактировать данные, содержащиеся в таблице.
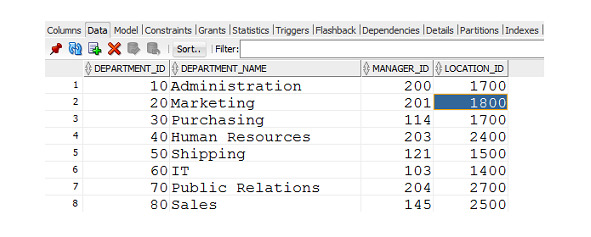
Рисунок 1.9. Вкладка Data
На вкладке Model (рисунок 1.10) в графическом виде отображаются структура таблицы и ее связи с другими таблицами.
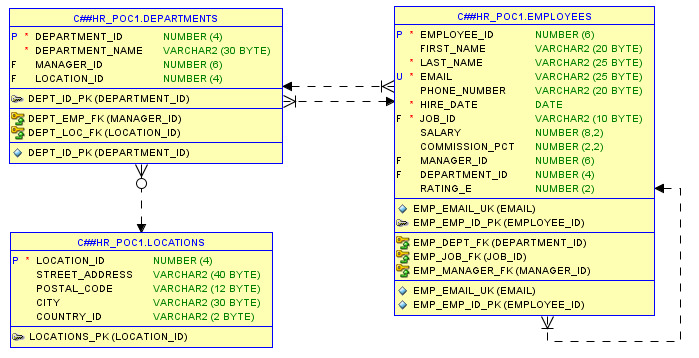
Рисунок 1.10. Вкладка Model
Использование рабочей области (SQL Worksheet)
При установлении соединения с базой данных автоматически открывается окно рабочей области (SQL Worksheet) для этого соединения. Это окно можно использовать для ввода, редактирования и выполнения операторов SQL и программ PL/SQL.
Для одного соединения можно создать несколько рабочих областей. Новую рабочую область можно создать, используя кнопку SQL Worksheet на панели инструментов или комбинацию клавиш Alt–F10. При создании новой рабочей области нужно выбрать соединение, для которого она будет использована. Рабочая область имеет собственную панель инструментов (рисунок 1.11).
Рисунок 1.11. Панель инструментов SQL Worksheet
Эта панель содержит значки, предназначенные для решения следующих задач:
— Run Statement: выполняет оператор, в котором находится курсор «переменные».
— Run Script: выполняет все операторы в рабочей области.
— Explain Plan: создает план выполнения. План выполнения — это последовательность операций, которые будут выполнены при выполнении оператора. План выполнения показывает исходное дерево строк с иерархией операций, составляющих оператор.
— Autotrace: генерирует информацию трассировки для оператора. Эта информация может помочь определить операторы SQL, которые выиграют от настройки.
— SQL Tuning Advisory: анализирует объемные операторы SQL и предлагает рекомендации по настройке.
— Commit: записывает любые изменения в базу данных и завершает транзакцию.
— Rollback: отменяет любые изменения в базе данных, не записывая их в базу данных, и завершает транзакцию.
— Unshared SQL Worksheet: создает новую рабочую область для соединения.
— To Upper / Lower / InitCap: изменяет выделенный текст на прописные, строчные или initcap соответственно.
— Clear: стирает оператор или операторы в поле «Ввести оператор SQL».
— SQL History: отображает диалоговое окно с информацией о выполненных операторах SQL.
Для выполнения оператора SQL, размещенного в рабочей обрасти, следует нажать кнопку Run Statement на панели инструментов, или функциональную клавишу F9. На рисунке 1.12 показан пример выполнения оператора SQL.
Если рабочая область содержит несколько операторов SQL или PL/SQL, то их можно выполнить, нажав кнопку Run Script на панели инструментов или функциональную клавишу F5. На рисунке 1.13 показан пример выполнения нескольких операторов SQL. Следует обратить внимание на то, что вешний вид результатов при использовании кнопки Run Script отличается от внешнего вида результатов при использовании кнопки Run Statement.
Примечание: кнопка Run Script обычно используется для запуска операторов PL/SQL.
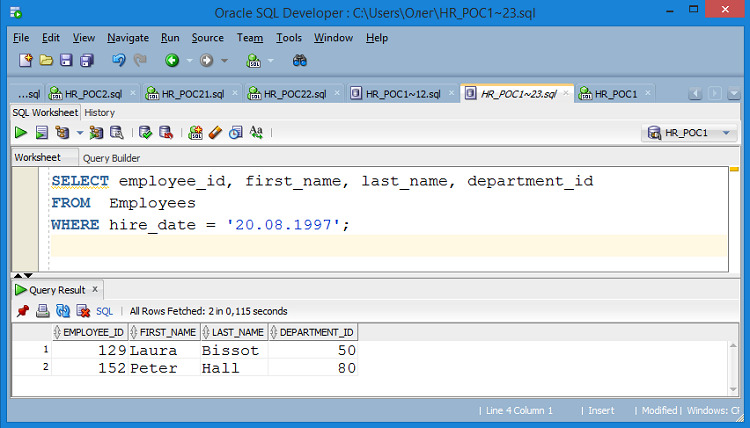
Рисунок 1.12. Пример выполнения одного оператора SQL
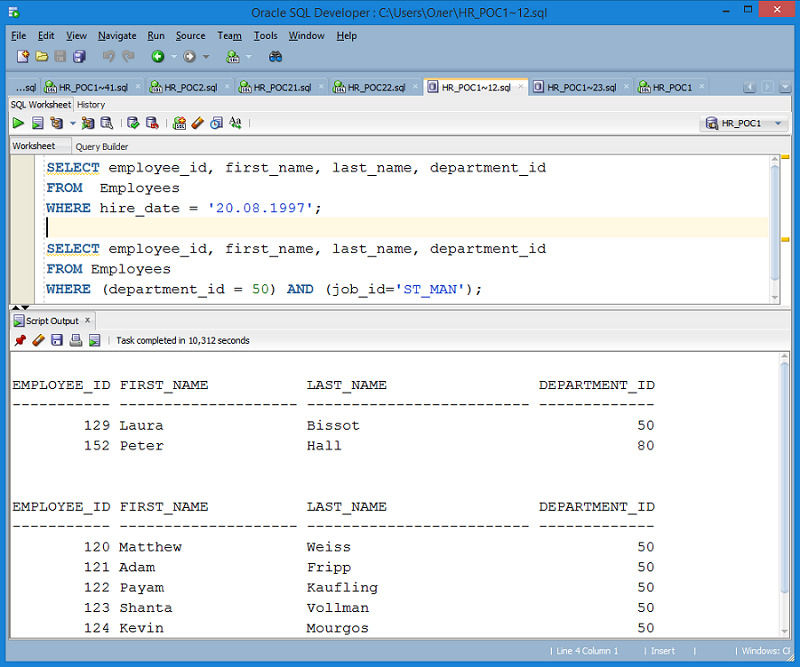
Рисунок 1.13. Пример выполнения нескольких операторов SQL
Экспорт и сохранение результатов выполнения запроса
Если для запуска оператора SQL использовалась кнопка Run Statement, то результаты выполнения запроса можно сохранить в определенном формате для дальнейшего использования и обработки. Для того чтобы выполнить эту операцию, нужно щелкнуть правой кнопкой и в появившемся контекстном меню (рисунок 1.14) выбрать команду Export.
В результате этих действий будет запушен мастер экспорта. В первом окне (рисунок 1.15) нужно выбрать формат, месторасположение и имя файла. На рисунке 1.16 показано содержимое файла export. xls, который содержит результат выполнения запроса.
Рисунок.1.14. Выбор команды Export
Рисунок 1.15. Выбор формата, месторасположения и имени файла
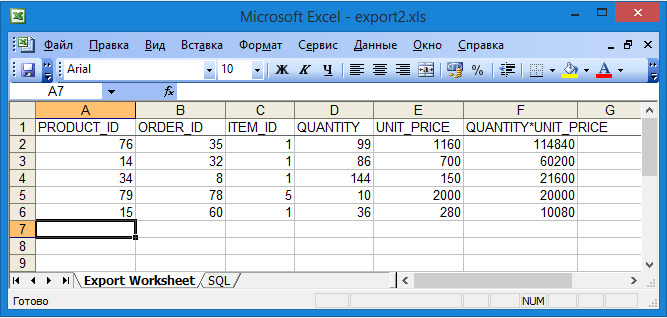
Рисунок 1.16. Результат экспорта — файл в формате xls
Сохранение операторов SQL
Для того чтобы сохранить операторы SQL в текстовом файле, следует нажать кнопку Save на панели инструментов или выбрать команду меню File — Save. На экране появится диалоговое окно Save (рисунок 1.17), в котором можно выбрать место сохранения и ввести имя файла.
Рисунок 1.17. Диалоговое окно Save
Выполнить сохраненные операторы SQL можно двумя способами:
Первый способ. Используя команду меню File — Open, открыть сохраненный файл, содержащий операторы SQL, и выполнить эти операторы кнопками Run Statement или Run Script (рисунок 1.18.
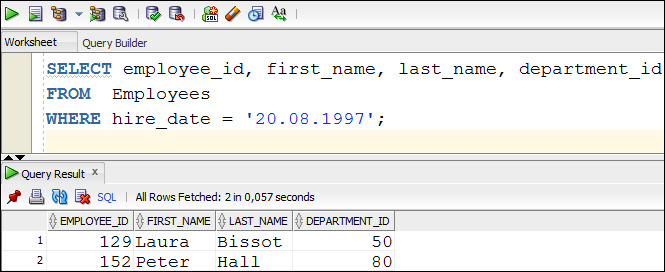
Рисунок 1.18. Первый способ выполнения операторов SQL
Второй способ. В рабочую область ввести команду, которая начинается с символа @ и содержит путь к файлу, и выполнить эту команду, используя кнопку Run Script. На рисунке 1.19 показан пример применения этого способа выполнения сохраненных операторов SQL.
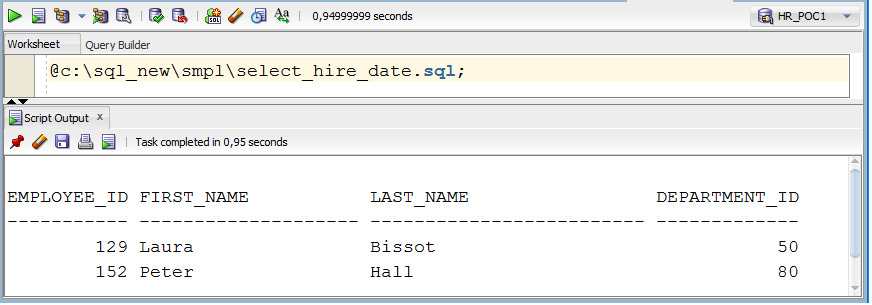
Рисунок 1.19. Второй способ выполнения операторов SQL
Экспорт базы данных
Используя Oracle SQL Developer, можно осуществить экспорт базы данных в файл, который будет содержать DDL-операторы создания таблиц и существующих ограничений и операторы INSERT для заполнения таблиц данными. Этот способ позволяет легко копировать небольшие базы данных с одного компьютера на другой.
На компьютере, куда копируется база данных, нужно создать схему, установить с ней соединение, открыть и выполнить файл, полученный в результате экспорта.
Для осуществления экспорта нужно выбрать команду Tools –Database Export. В результате на экране появится окно (рисунок 1.20), в котором нужно выбрать экспортируемую схему, имя и расположение файла, куда будут экспортироваться данные. Рекомендуется снять флажок Show Schema. Если этого не сделать, то все операторы будут содержать имя экспортируемой схемы, что усложнит процесс копирования. На компьютере, куда копируется база, нужно будет обязательно создать схему, имя которой должно совпадать с именем копируемой схемы.
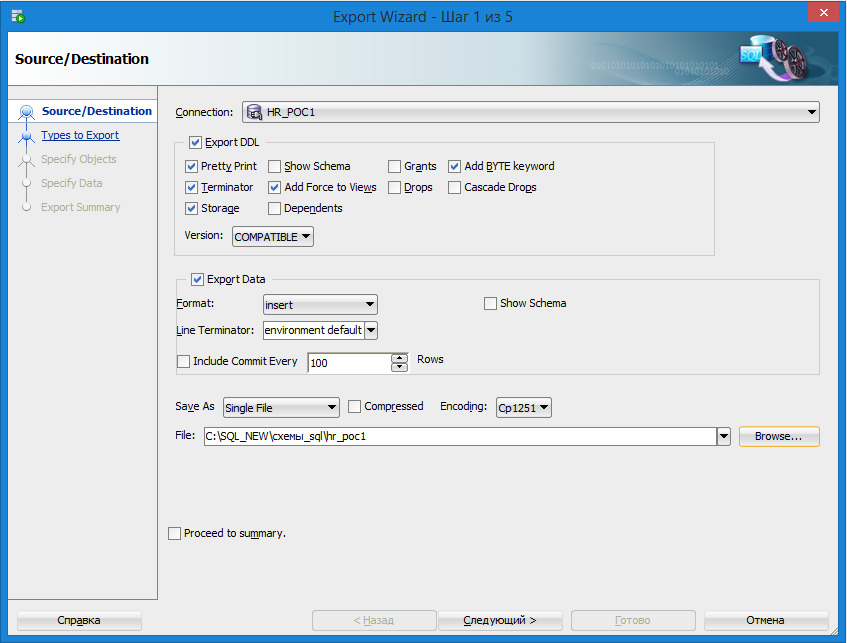
Рисунок 1.20. Окно экспорта
Полученный в результате экспорта файл можно использовать для графического отображения таблиц базы данных и связей между ними. Для этого данный файл нужно импортировать в программу Oracle SQL Developer Data Modeler. Так были получены схемы баз данных, которые рассматривались в предыдущем разделе.
Можно настроить многие параметры SQL Developer в соответствии со своими предпочтениями и потребностями. Для этого нужно выбрать в меню Tools команду Preferences. В качестве примера рассмотрим настройки параметров Database: NLS (рисунок 1.21).
Здесь указываются значения для параметров поддержки глобализации, такие как язык, территория, предпочтения сортировки и формат даты. Эти значения параметров используются для операций сеанса SQL Developer. Указанные на этой панели настройки не влияют на настройки СУБД. Чтобы изменить настройки СУБД, необходимо изменить соответствующие параметры, используя специальные команды, и перезапустить базу данных.
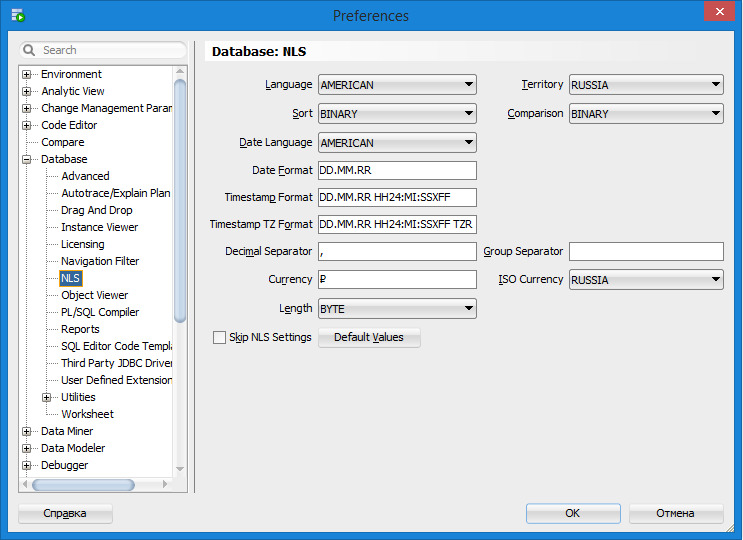
Рисунок 1.21. Настройка параметров Database: NLS
Создание пользователей и предоставление привилегий
Все действия с базой данных, включая создание ее объектов, осуществляются пользователями, поэтому на первом этапе необходимо создать пользователя и предоставить ему необходимые права (привилегии) для работы с базой данных.
Эту операцию должен выполнить администратор базы данных. По умолчанию администратором базы данных является пользователь SYSTEM.
Для создания нового пользователя используется команда CREATE USER. Упрощенный синтаксис этой команды имеет следующий вид:
CREATE USER {имя пользователя} IDENTIFIED BY {пароль}
DEFAULT TABLESPACE tablespace_name
QUOTA size (K | M | G) UNLIMITED ON tablespace_name;
где:
— tablespace_name — имя области данных, в которой будут создаваться объекты пользователя. Если имя области данных не указано, то объекты пользователя по умолчанию создаются в области данных SYSTEM;
— tablespace_tmp — имя области данных для временных объектов пользователя. Если имя области данных не указано, то временные объекты создаются в области данных SYSTEM;
— size — размер используемого пространства для области данных TABLESPACE в килобайтах (К), мегабайтах (М) и гигабайтах (G). Ключевое слово UNLIMITED используется для предоставления пространства неограниченного размера.
Пример:
CREATE USER C##HR_POC IDENTIFIED BY PASS123
DEFAULT TABLESPACE USERS
QUOTA 500M ON USERS;
Изменение пароля осуществляется командой:
ALTER USER {имя пользователя} IDENTIFIED BY {пароль};
Например:
ALTER USER C##HR_POC IDENTIFIED BY PASS456;
Для просмотра данных об объектах пользователя можно использовать следующий запрос:
SELECT OWNER, OBJECT_NAME, OBJECT_TYPE, CREATED,
STATUS
FROM SYS. DBA_OBJECTS
WHERE OWNER = ′ {имя пользователя} ′;
Например:
SELECT OWNER, OBJECT_NAME, OBJECT_TYPE, CREATED, STATUS
FROM SYS. DBA_OBJECTS
WHERE OWNER = ′ C##HR_POC ′;
Для того чтобы получить имена пользователей, зарегистрированных на сервере, следует выполнить следующий запрос:
SELECT USERNAME FROM DBA_USERS ORDER BY 1;
Для удаления пользователя и принадлежащей ему схемы служит команда:
DROP USER {имя пользователя} CASCADE;
После создания пользователя ему необходимо предоставить привилегии (права), которые определяют, какие действия может выполнять пользователь. Привилегии, предоставленные пользователю, могут меняться с течением времени: можно отменить (отозвать) имеющиеся привилегии или добавить новые.
Привилегии делятся на системные и объектные. В таблице 1.1 приведены основные системные привилегии, которые администратор может предоставить пользователю, а таблица 1.2 содержит основные объектные привилегии.
Таблица 1.1. Основные системные привилегии

Таблица 1.2. Основные объектные привилегии

Для предоставления пользователю системных привилегий используется команда GRANT, которая имеет следующий синтаксис:
GRANT {имя привилегии} ON {имя пользователя};
Пример предоставления системных привилегий пользователю:
GRANT CREATE SESSION, CREATE TABLE ON C##HR_POC;
Для отзыва привилегии используется команда:
REVOKE {имя привилегии} ON {имя пользователя};
Пример отзыва системной привилегии у пользователя:
REVOKE CREATE TABLE ON C##HR_POC;
Для предоставления пользователю объектных привилегий используется команда GRANT, которая имеет следующий синтаксис:
GRANT {имя привилегии} ({список столбцов}) ON {имя таблицы}
TO {имя пользователя};
где: ({список столбцов}) — список столбцов, для которых предоставляется привилегия. Если column_list отсутствует, то привилегия предоставляется для всех столбцов.
Пример предоставления объектной привилегии:
GRANT UPDATE (RATING_E, SALARY) ON EMPLOYEES TO C##HR_POC;
Для отзыва привилегии используется команда:
REVOKE {имя привилегии} ({список столбцов})
ON {имя таблицы} TO {имя пользователя};
Пример отзыва объектной привилегии:
REVOKE UPDATE (SALARY) ON EMPLOYEES TO C##HR_POC;
Для того чтобы увидеть какие системные привилегии предоставлены пользователю, следует выполнить запрос
SELECT *
FROM USER_SYS_PRIVS;
Для просмотра объектных привилегий служит запрос
SELECT *
FROM USER_TAB_PRIVS_MADE
Привилегии могут быть сгруппированы в роли. Роль определяет список привилегий, предоставляемых пользователю. Существуют предопределенные роли, которые администратор может назначить пользователю. Таблица 1.3 содержит список наиболее часто используемых предопределенных ролей.
Таблица 1.3. Список имен предопределенных ролей

Используя команду
GRANT {имя роли} ON {имя пользователя};
можно назначить пользователю список привилегий, определенных для роли.
Часть назначенных привилегий можно отозвать, используя команду
REVOKE {имя привилегии} ON {имя пользователя};
Для отзыва всех привилегий, назначенных ролью, следует использовать команду:
REVOKE {имя роли} ON {имя пользователя};
Следует иметь в виду, что роль RESOURCE включает предоставление привилегии UNLIMITED TABLESPACE и не включает привилегию CREATE VIEW. Учитывая это, привилегии, которые следует предоставлять пользователям, не являющимся администраторами базы данных, можно предоставить командой:
GRANT CONNECT, RESOURCE, CREATE VIEW TO {имя пользователя};
ЧАСТЬ 2. SQL — ЯЗЫК СТРУКТУРИРОВАННЫХ ЗАПРОСОВ
SQL (Structured Query Language) — язык структурированных запросов, является основным языком определения, манипулирования и управления данными в современных СУБД. Принципы работы с данными, на которых основан SQL, существенно отличаются от принципов решения таких задач при использовании алгоритмических языков программирования.
Иногда эту разницу объясняют следующим образом: при использовании алгоритмического языка вы должны определить последовательность действий, которая приведет к нужному результату, а при использовании SQL вы должны только определить данные, которые необходимо получить. Такое определение справедливо лишь отчасти, так как при решении сложных задач приходится их разбивать на отдельные подзадачи, решать эти подзадачи, используя подзапросы, которые должны быть выполнены в определенной последовательности. Здесь я имею в виду операторы манипулирования данными, содержащие подзапросы. Так что решение многих задач средствами SQL требует разработки алгоритма решения.
Стандарт SQL определяется Американским национальным институтом стандартов (American National Standards Institute, ANSI) и в данное время также принимается Международной организацией по стандартизации (International Organization for Standardization, ISO). Названия этих стандартов состоят из аббревиатуры SQL и года, когда они были приняты. К настоящему времени известны следующие стандарты: SQL-86, SQL-89, SQL-92, SQL:1999, SQL:2003, SQL:2006, SQL:2008, SQL:2011, SQL:2016, SQL:2019. При этом реализация SQL, используемой в конкретной версии СУБД, лишь отчасти соответствует тому или иному стандарту. Например, в содержится описание соответствия версии SQL, используемой в СУБД Oracle 18, стандартам языка SQL.
Операторы SQL разделены на три группы:
• Операторы манипулирования данными (Data Manipulation Language, DML) — предназначены для выборки и изменения данных: SELECT, INSERT, UPDATE, MERGE, DELETE.
• Операторы определения данных (Data Definition Language, DDL) — предназначены для создания и модификации объектов базы данных. Основными операторами этой группы являются: CREATE, ALTER, DROP.
• Операторы управления данными (Data Control Language, DCL) — предназначены для предоставления пользователям прав на выполнение определенных действий с базой данных: GRANT, REVOKE.
Глава 2. Структура оператора SELECT и формирование условий выбора
Оператор SELECT
Оператор SELECT предназначен для выборки данных из таблиц, то есть он реализует одно из основных назначений базы данных — предоставлять пользователю информацию. Результатом выполнения оператора SELECT является таблица.
Согласно классической классификации оператор SELECT относится к операторам DML. Однако в Oracle версии SQL к операторам DML относят только INSERT, UPDATE, MERGE и DELETE, а оператор SELECT выделен в отдельную группу.
В общем виде структура оператора SELECT может быть представлена в следующем виде:
SELECT [ALL|DISTINCT] {список столбцов или выражений}
FROM {список таблиц}
[WHERE {условия выбора}]
[ORDER BY {столбцы сортировки [ASC|DESC]]}
[GROUP BY {столбцы группировки}]
[HAVING {условия на группу}];
(Квадратными скобками отмечены необязательные элементы.)
Дадим предварительное описание элементов данного оператора.
Оператор SELECT начинается со списка столбцов или выражений, значения которых будет отображаться в результате выполнения запроса. По умолчанию SELECT не исключает дублирование строк в результате выполнения запроса. Для исключения дублирования следует использовать ключевое слово DISTINCT.
В предложении FROM указываются источники данных. В качестве таких источников можно использовать таблицы базы данных, а также таблицы, которые возвращают подзапросы или представления. В тех запросах, где используется несколько таблиц, необходимо обязательно указывать условия соединения. Если этого не сделать, то будет осуществляться декартово произведение таблиц.
Предложение WHERE содержит условия выбора строк, а также может содержать условия соединения таблиц в многотабличных запросах.
Строки, удовлетворяющие условиям выбора, могут быть упорядочены по значениям одного или нескольких столбцов.
В предложении ORDER BY указываются имена столбцов, по значению которых следует упорядочить результат выполнения запроса. По умолчанию строки упорядочиваются в порядке возрастания значений столбца. Для сортировки в порядке убывания после имени столбца следует указать параметр DESC. Если указать несколько столбцов, то результат будет упорядочиваться сначала по значению первого столбца; строки, имеющие одинаковые значения первого столбца, упорядочиваются по значению второго столбца, и так далее.
В предложении GROUP BY можно указать столбцы, по которым следует осуществить группировку. Группировка состоит в том, что несколько строк, имеющих совпадающие значение столбцов, по которым осуществляется группировка, объединяются в одну строку. Обычно группировка используется в запросах, использующих агрегатные функции, например: Sum (), Max ().
При наличии группировки в предложении HAVING можно указать условия на группу. Результат выполнения запроса будет содержать данные только о тех группах записей, которые удовлетворяют этому условию.
При изучении SQL следует обратить внимание на то, что для формирования запроса необходимо:
— определить структуру запроса, соответствующую заданной задаче обработки данных;
— синтаксически правильно записать запрос.
Перейдем к рассмотрению примеров, которые должны научить нас правильно решать обе задачи. Сначала будут рассмотрены запросы, структура которых очевидна, поэтому основное внимание будет уделяться синтаксису. Потом мы перейдем к рассмотрению более сложных запросов, где основной задачей будет являться определение структуры запроса.
В своей простейшей форме оператор SELECT должен включать в себя следующее:
— предложение SELECT, где указываются имена столбцов, значение которых будет отображаться в результате выполнения запроса;
— предложение FROM, в котором указывается имя таблицы, содержащей данные.
SELECT {список столбцов}
FROM {таблица};
Пример 2.1. Вывод содержимого одного столбца
SELECT employee_id
FROM Employees;
Пример 2.2. Вывод содержимого нескольких столбцов
SELECT employee_id, first_name, last_name, department_id
FROM Employees;
Если в качестве результата выполнения запроса нужно вывести значения всех столбцов, то вместо списка столбцов указывается символ *.
Пример 2.3. Вывод значений всех столбцов
SELECT *
FROM Employees;
Исключение дублирования данных
Рассмотрим запрос, который выводит коды должностей сотрудников.
Пример 2.4. Вывод значений столбца job_id
SELECT job_id
FROM Employees;
Так как одну должность могут занимать несколько сотрудников, то коды должностей будут повторяться. Для того чтобы исключить повторения значений, следует добавить ключевое слово DISTINCT.
Пример 2.5 Вывод значений столбца job_id без дублирования
SELECT DISTINCT job_id
FROM Employees;
Условия выбора
Для того чтобы выводить только те данные, которые удовлетворяют определенным условиям, оператор SELECT должен содержать предложение WHERE, которое содержит условное выражение.
SELECT {список столбцов}
FROM {таблица}
WHERE {условное выражение};
Условное выражение для каждой строки таблицы может принимать значения: ИСТИНА (TRUE), ЛОЖЬ (FALSE), НЕ ОПРЕДЕЛЕНО (UNKNOWN). Результат выполнения запроса будет содержать только те строки, для которых условное выражение будет иметь значение ИСТИНА (TRUE).
Пример 2.6. Вывод данных о сотрудниках, зарплата которых больше 5000
SELECT employee_id, first_name, last_name, salary, department_id
FROM Employees
WHERE salary> 5000;
Пример 2.7. Вывод данных о сотрудниках, принятых на работу 20.08.1997
SELECT employee_id, first_name, last_name, salary, department_id
FROM Employees
WHERE hire_date = ′ 20.08.1997 ′;
В процессе выполнения этого оператора осуществляется неявное преобразование строки ′ 20.08.1997 ′ в формат Date. Для того чтобы это преобразование произошло без ошибок, содержимое строки, содержащую дату, должно быть совместимо с настройками Oracle SQL Developer (рисунок 1.21).
Для указаний условий выбора могут быть использованы операторы сравнения: =,>, <и логические операторы: NOT, AND, OR. Логические операторы используются для формирования сложных условий выбора и имеют разный приоритет. Сначала выполняются все операторы NOT, потом операторы AND; операторы OR выполняются в последнюю очередь. Для исключения возможных ошибок при формировании сложных запросов следует использовать скобки. Выражения внутри скобок выполняются первыми, слева направо.
Рассмотрим примеры запросов, использующих логические операторы при формировании условий выбора.
Пример 2.8. Вывод данных о сотрудниках, которые работают в отделе 50 и занимают должность ST_MAN
SELECT employee_id, first_name, last_name, department_id
FROM Employees
WHERE (department_id = 50) AND (job_id= ′ ST_MAN ′);
Пример 2.9. Вывод данных о договорах, заключенных сотрудником 150 с клиентом 49, совершенных в определенную дату (27.09.2017)
SELECT * FROM Orders
WHERE (salesman_id = 150) AND (customer_id=49)
AND (order_date = ′ 27.09.2017 ′);
Использование скобок при формировании условий выбора может существенным образом изменять логику выполнения запроса.
Пример 2.10. Вывод данных о договорах сотрудника 155, заключенных 15.03.2018 или 02.11.2019
SELECT * FROM Orders
WHERE (salesman_id = 155) AND (order_date = ′ 15.03.2018 ′
OR order_date = ′ 02.11.2019 ′);
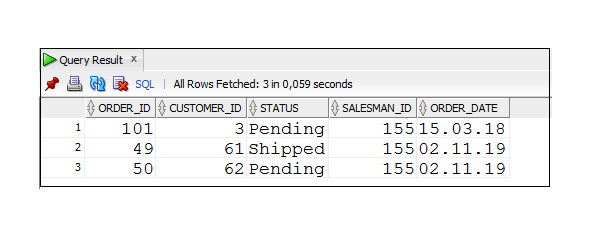
Если в предложении WHERE скобки поставить так, как это показано в примере 2.11, то запрос будет иметь совсем другой смысл.
Пример 2.11. Вывод данных о договорах сотрудника 155, заключенных 15.03.2018, или обо всех договорах, заключенных 02.11.219
SELECT * FROM Orders
WHERE (salesman_id = 155) AND (order_date = ′ 15.03.2018 ′)
OR (order_date = ′ 02.11.2019 ′);
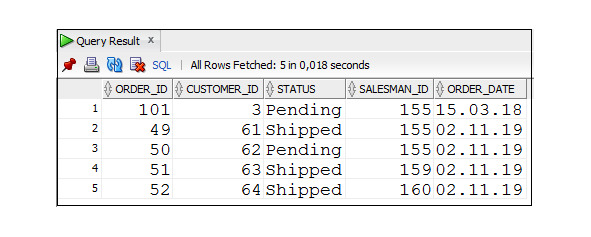
Специальные операторы
Для формирования условий выбора можно использовать специальные операторы, представленные в таблице 2.1.
Таблица 2.1. Специальные операторы

Рассмотрим примеры запросов, использующих специальные операторы.
Оператор LIKE
Оператор LIKE используется для работы со строками. Он проверяет, совпадает ли часть строки с заданным шаблоном. Для создания шаблонов в операторе LIKE используются следующие символы:
— символ подчеркивания _ обозначает один символ;
— символ процента % обозначает несколько символов.
Синтаксис:
{имя столбца} LIKE ′ шаблон ′
Пример 2.12. Вывод данных о сотрудниках, имена которых начинаются на букву L
SELECT employee_id, first_name, last_name, department_id
FROM Employees
WHERE first_name LIKE ′ L% ′;
Пример 2.13. Вывод имен сотрудников, вторым символом которых является буква а
SELECT DISTINCT first_name
FROM Employees
WHERE first_name LIKE ′ _a% ′;
Пример 2.14. Вывод имен сотрудников, которые состоят из четырех символов, начинаются на букву J и заканчиваются буквой n
SELECT DISTINCT first_name
FROM Employees
WHERE first_name LIKE ′ J__n ′;
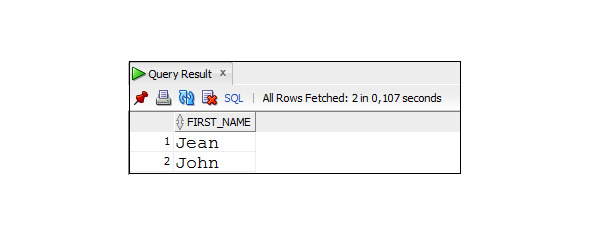
Для поиска в строке символов _ и % при построении шаблона используется опция ESCAPE /. Символ, который в шаблоне будет располагаться после /, будет рассматриваться как символ поиска. Вместо символа / можно использовать и другие символы, например!.
Пример 2.15. Вывести имя и адрес клиентов, столбец address которых содержит символ /
SELECT c_name, address
FROM Customers
WHERE address LIKE ′ %//% ′ ESCAPE ′ / ′;
Оператор BETWEEN
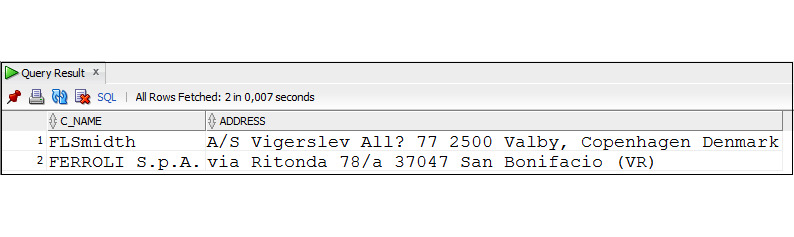
Оператор BETWEEN используется для того, чтобы результат запроса содержал только те строки, в которых значение проверяемого столбца находится в заданном диапазоне.
Синтаксис:
{имя столбца} BETWEEN V_MIN AND V_MAX
V_MIN — нижняя граница диапазона;
V_MAX — верхняя граница диапазона
Оператор BETWEEN осуществляет поиск среди всех значений диапазона, включая границы. Оператор BETWEEN эквивалентен двум операциям сравнения, объединенным логическим оператором AND.
({имя столбца}> = V_MIN) AND ({имя столбца} <= V_MAX)
Пример 2.16. Вывести данные о сотрудниках, зарплата которых находится в определенном диапазоне
SELECT employee_id, first_name, last_name, department_id
FROM Employees
WHERE salary BETWEEN 6000 AND 8000;
Для определения границ диапазона можно использовать вещественные числа, даты и строки.
Пример 2.17. Получить данные о сотрудниках, у которых значение комиссионных находится в определенном диапазоне
SELECT employee_id, first_name, last_name, department_id,
salary, commission_pct
FROM Employees
WHERE commission_pct BETWEEN 0.15 AND 0.2;
Пример 2.18. Получить данные о договорах, дата заключения которых лежит в определенном диапазоне
SELECT * FROM Orders
WHERE order_date BETWEEN ′ 01.09.2019 ′
AND ′ 30.09.2019 ′;
Оператор BETWEEN можно использовать совместно с логическим оператором NOT.
Пример 2.19. Получить данные о договорах, дата заключения которых не лежит в определенном диапазоне
SELECT * FROM Orders
WHERE order_date NOT BETWEEN ′ 01.09.2019 ′ AND ′ 30.09.2019 ′;
При использовании в качестве границ диапазона строчных значений нужно учитывать особенности сортировки строк. Например, нужно получить данные о сотрудниках, имена которых начинаются с букв в диапазоне с A по B.
На первый взгляд может показаться, что данную задачу должен решить следующий запрос.
Пример 2.20. Получить данные о сотрудниках, имена которых начинаются с букв в диапазоне с A по B (содержит ошибку)
SELECT employee_id, first_name, last_name, department_id
FROM Employees
WHERE first_name BETWEEN ′ A ′ AND ′ B ′;
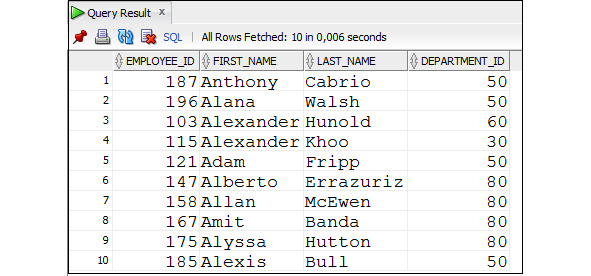
Но анализ результатов этого запроса показывает, что данные о сотрудниках, чьи имена начинаются на букву B, в результат выполнения запроса не попали, хотя такие сотрудники есть, например Bruce.
Это происходит потому, что значение строки B меньше значения строки Bruce, поэтому данные о сотрудниках, чьи имена начинаются на букву B, в результат выполнения запроса не попали. Эту проблему можно решить, указывая в качестве верхнего диапазона следующую букву.
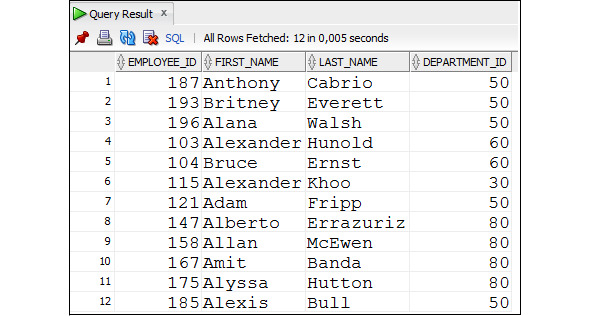
Пример 2.21. Получить данные о сотрудниках, имена которых начинаются с букв в диапазоне с A по B
SELECT employee_id, first_name, last_name, department_id
FROM Employees
WHERE first_name BETWEEN ′ A ′ AND ′ C ′;
Оператор IN
Оператор IN используется для того, чтобы результат запроса содержал только те строки, в которых значение проверяемого столбца совпадает с одним из значений, указанных в списке.
Синтаксис:
{имя столбца} IN {список значений}
Список значений в операторе IN может формироваться в результате выполнения оператора SELECT (подзапроса).
Пример 2.22. Вывести данные о сотрудниках, которые работают в отделах с определенными номерами
SELECT employee_id, first_name, last_name, department_id
FROM Employees
WHERE department_id IN (40, 10, 110);
Пример 2.23. Вывести данные о договорах, заключенных в определенные даты
SELECT * FROM Orders
WHERE order_date IN (′ 07.09.19 ′, ′ 14.09.19 ′, ′ 02.11.19 ′);
Оператор IN можно использовать вместе с логическим оператором NOT. В этом случае результат запроса будет содержать строки, в которых значение проверяемого столбца не совпадает ни с одним из значений, указанных в списке.
Пример 2.24. Вывести данные о сотрудниках, которые не работают в отделах с определенными номерами
SELECT employee_id, first_name, last_name, department_id
FROM Employees
WHERE department_id NOT IN (40, 10, 110);
Условия выбора, формируемые оператором IN, можно объединять с другими условиями выбора.
Пример 2.25. Вывести названия городов, которые расположены в США или Канаде и почтовый индекс которых заканчивается цифрой 2
SELECT city FROM Locations
WHERE (country_id IN (′ US ′, ′ CA ′))
AND (postal_code LIKE ′ %2 ′);
Следует иметь в виду, что если список значений в IN будет содержать NULL, то результат выполнения оператора не будет содержать строк, у которых проверяемый столбец имеет значение NULL, так как результат сравнения NULL имеет значение НЕ ОПРЕДЕЛЕНО (UNKNOWN).
Пример 2.26. Вывести данные о сотрудниках, которые работают в отделах с определенными номерами, и о сотрудниках, у которых не задан номер отдела
SELECT employee_id, first_name, last_name, department_id
FROM Employees
WHERE department_id IN (40, 10, 110, NULL);
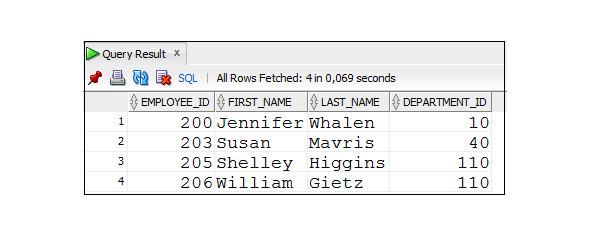
При этом в таблице Employees есть строки, у которых столбец department имеет значение NULL (см. результаты выполнения запроса из примера 2.29).
Если список значений в NOT IN будет содержать NULL, то результат выполнения оператора SELECT будет пуст. Это происходит, потому что оператор
X NOT IN (A1, A2, AN)
эквивалентен выражению
X <> A1 AND X <> A2 AND …X <> AN
Если одно из Ai будет NULL, то результат этого выражения будет иметь значение НЕ ОПРЕДЕЛЕНО (UNKNOWN).
Пример 2.27. Вывести данные о сотрудниках, которые не работают в отделах с определенными номерами
SELECT EMPLOYEE_ID, FIRST_NAME, LAST_NAME,
DEPARTMENT_ID
FROM EMPLOYEES
WHERE DEPARTMENT_ID NOT IN (30,50,60,80,90,100,NULL);
Результат выполнения этого запроса не будет содержать строк.
Оператор IS NULL
Оператор IS NULL используется для определения строк с неопределенным значением заданного столбца.
Синтаксис:
{имя столбца} IS NULL
Данное выражение принимает значение TRUE, если значение проверяемого столба будет NULL.
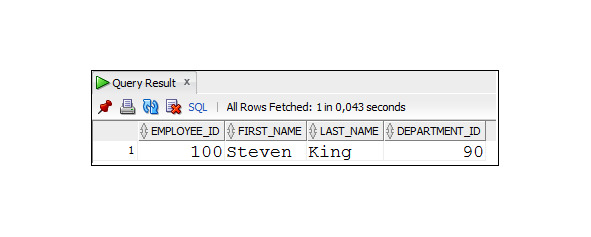
Пример 2.28. Получить данные о сотрудниках, для которых неизвестен номер руководителя
SELECT employee_id, first_name, last_name, department_id
FROM Employees
WHERE manager_id IS NULL;
Пример 2.29. Вывести данные о сотрудниках, у которых не задан номер отдела
SELECT employee_id, first_name, last_name, department_id
FROM Employees
WHERE department_id IS NULL;
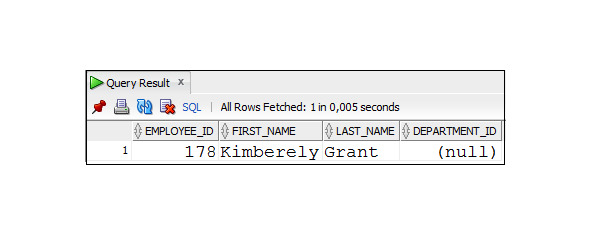
Можно также использовать разновидность данного оператора IS NOT NULL, который возвращает значение FALSE, если значение проверяемого столба будет NULL.
Пример 2.30. Получить данные о сотрудниках, для которых известен номер руководителя
SELECT employee_id, first_name, last_name, department_id
FROM Employees
WHERE manager_id IS NOT NULL;
Использование вычисляемых столбцов
В предложении SELECT, кроме списка столбцов таблиц участвующих в запросе, могут присутствовать вычисляемые столбцы, которые представляют собой выражения, состоящие из имен столбцов, констант, функций и арифметических операций. Значению вычисляемого поля можно присвоить имя. Для этого используется следующая конструкция:
{Выражение} As {псевдоним}
При вычислении выражения, содержащего несколько арифметических операций, Oracle выполняет операции с более высоким приоритетом перед выполнением операций с более низким приоритетом.
Сначала выполняются операции умножения и деления, которые имеют одинаковый приоритет, потом сложения и вычитания, которые также относительно друг друга имеют одинаковый приоритет.
Если операции в выражении имеют одинаковый приоритет, то их выполнение производится слева направо.
Рассмотрим примеры использования вычисляемых столбцов. Если значение столбца commission_pct в таблице Employees обозначает надбавку к зарплате как часть заработной платы, то общая зарплата с учетом комиссионных может быть вычислена с использованием выражения:
SALARY * (1 + COMMISSION_pct) As Total_Salary
Следует иметь в виду то, что у некоторых сотрудников значение столбца commission_pct равно NULL. А если один из элементов выражения равен NULL, то и все выражение будет иметь значение NULL. Данную проблему можно решить, используя специальные функции, которые мы рассмотрим позже.
Пример 2.31. Вывести данные о размере комиссионных для сотрудников, которые получают комиссионные
SELECT employee_id, first_name, last_name, department_id,
commission_pct*salary as commission
FROM Employees
WHERE commission_pct IS NOT NULL;
Вычисляемые столбцы можно использовать в предложении WHERE.
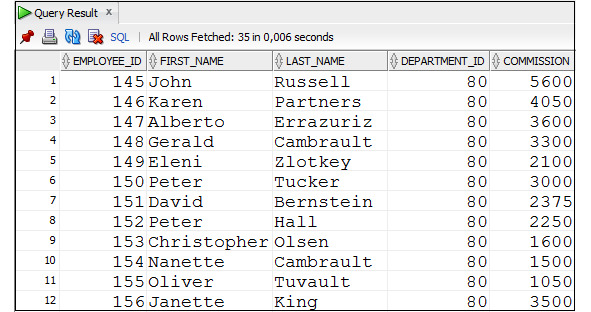
Пример 2.32. Вывести данные о продажах товаров, в которых сумма одной покупки превышала 300 000
SELECT product_id, order_id, item_id, quantity, unit_price,
quantity*unit_price
FROM Order_items
WHERE quantity*unit_price> 300000;
Использование псевдостолбца ROWNUM
Значение псевдостолбца ROWNUM равно номеру записи, возвращаемой запросом. Используя этот столбец, можно ограничить число строк в результате выполнения запроса.
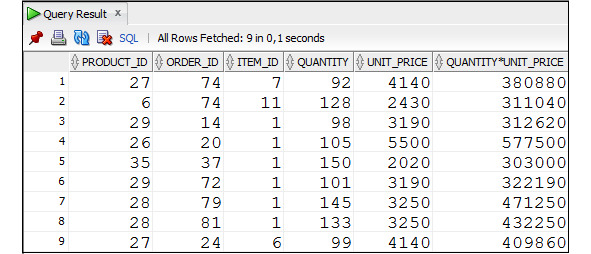
Пример 2.33. Вывести пять строк с данными о продажах товаров, в которых сумма одной покупки превышала 300 000
SELECT product_id, order_id, item_id, quantity, unit_price,
quantity*unit_price
FROM Order_items
WHERE quantity*unit_price> 300000
AND ROWNUM <=5;
Следует иметь в виду, что любой запрос, содержащий условие ROWNUM = N, где N> 1, будет пуст. Это происходит потому, что первая строка, возвращаемая запросом, имеет значение ROWNUM = 1, это значение не удовлетворяет условию ROWNUM = N и поэтому не попадает в результат выполнения запроса. После этого каждая следующая строка будет иметь значение ROWNUM = 1 и также не будет удовлетворять условию ROWNUM = N.
Оператор конкатенации
Оператор конкатенации (слияния) записывается двумя вертикальными чертами (||) и используются для того, чтобы объединить при выводе данных два или несколько столбцов или литералов в один столбец.
Синтаксис:
{столбец1/литерал1} || {столбец2/литерал2} …As {псевдоним}
Оператор конкатенации можно применять для строк, чисел и дат. Даты и числа при слиянии конвертируются в строковые значения. При слиянии строки значения со значением типа NULL Oracle возвращает строковое значение.
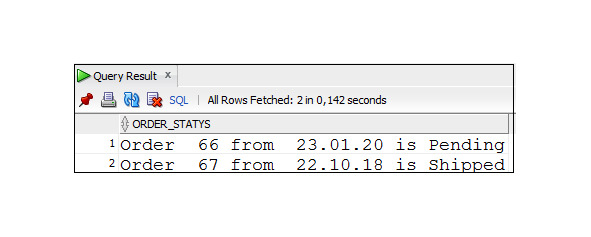
Пример 2.34. Вывести данные о заказах, оформленных сотрудником 165
SELECT ′ Order ′ ||order_id|| ′ from ′ ||order_date
|| ′ is ′ ||status AS Order_Statys
FROM Orders
WHERE salesman_id =165;
Сортировка
Результат выполнения оператора SELECT может быть упорядочен по значению одного или нескольких столбцов. Для этого служит предложение ORDER BY, которое имеет следующий синтаксис:
ORDER BY {имя столбца | номер столбца [ASC|DESC]}
Пример 2.35. Вывести данные о сотрудниках, упорядочив их в порядке убывания зарплаты
SELECT employee_id, first_name, last_name, department_id, salary
FROM Employees
ORDER BY salary DESC;
Отсортировать результат можно по значениям нескольких столбцов. Сначала строки упорядочиваются по значению первого столбца. Строки, имеющие одинаковые значения первого столбца, упорядочиваются по значению второго столбца, и т. д. Для каждого столбца можно указать свой порядок сортировки.
Пример 2.36. Вывести данные о сотрудниках, упорядочив их в порядке возрастания номеров отделов, в которых они работают. Данные о сотрудниках, которые работают в одном отделе, упорядочить в порядке убывания зарплаты
SELECT employee_id, first_name, last_name, department_id, salary
FROM employees
ORDER BY department_id, salary DESC;
В предложении ORDER BY можно использовать псевдонимы столбцов.
Пример 2.37. Вывести данные о сотрудниках, которые получают комиссионные, упорядочив их в порядке убывания суммы комиссионных
SELECT employee_id, first_name, last_name, department_id,
commission_pct*salary as commission
FROM Employees
WHERE commission_pct IS NOT NULL
ORDER BY commission DESC;
Можно сортировать строки по столбцам, не указанным в предложении SELECT.
Пример 2.38. Вывести данные о сотрудниках, которые работают в отделе 80, упорядочив их в порядке убывания рейтинга
SELECT employee_id, first_name, last_name, department_id, salary
FROM Employees
WHERE department_id = 80
ORDER BY rating_e;
Следует иметь в виду, что запрос с группировкой, содержащий условие ROWNUM ≤ N, не вернет первые N строк из всего набора записей, удовлетворяющих условиям запроса отсортированные по значениям определенного столбца. Это происходит потому, что сначала проверяется условие ROWNUM ≤ N, затем осуществляется сортировка. Это может стать причиной трудно обнаруживаемых ошибок. Для иллюстрации этого утверждения рассмотрим следующий пример.
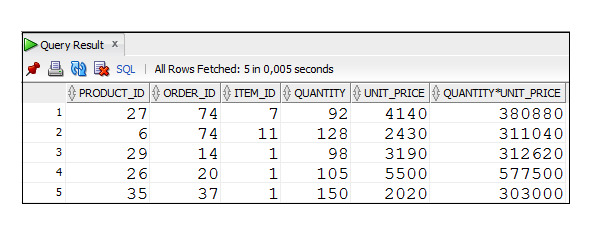
Пример 2.39. Вывести пять строк с данными о продажах товаров с максимальными суммами (запрос содержит ошибку)
SELECT product_id, order_id, item_id, quantity, unit_price,
quantity*unit_price
FROM Order_Items
WHERE ROWNUM <=5
ORDER BY quantity*unit_price DESC;
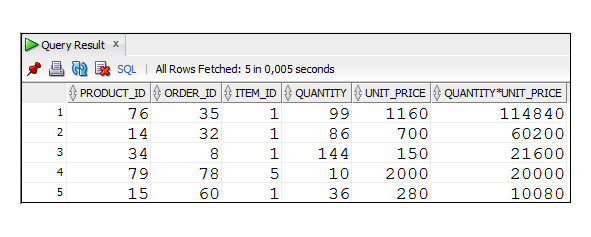
Полученный результат выглядит весьма правдоподобно. Результат содержит пять строк, и они упорядочены в порядке убывания сумм. Ошибка заключается в том, что сортируются не все строки, а только первые пять строк. Правильный вариант решения рассматриваемой задачи приведен в следующем примере.
Пример 2.40. Вывести пять строк с данными о продажах товаров с максимальными суммами
SELECT product_id, order_id, item_id, quantity, unit_price,
quantity*unit_price
FROM Order_Items
ORDER BY quantity*unit_price DESC
FETCH FIRST 5 ROWS ONLY;
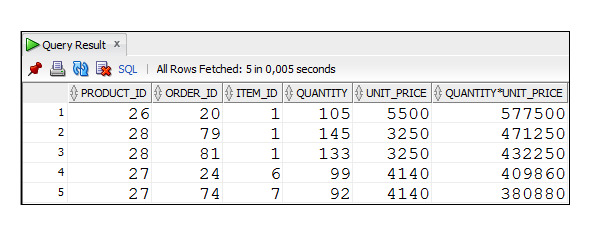
Этот запрос содержит строку FETCH FIRST 5 ROWS ONLY, которая выбирает первые пять строк после сортировки. Этот оператор появился в Oracle 12.
Задачи для самостоятельного решения
1. Вывести данные о товарах, у которых столбец rating_p имеет значение 3 или 4, а price <1000.
2. Вывести first_name, last_name сотрудников, у которых first_name начинается на букву P и в last_name есть буква r.
3. Вывести значения столбцов employee_id, department_id, first_name, last_name, job_id, salary, department_id сотрудников, у которых зарплата salary> 9000 и работают в одном из отделов: 50, 80, 100.
4. Вывести содержимое столбца street_address в таблице Locations тех строк, у которых значение этого столбца начинается не с цифры.
5. Вывести first_name, last_name, job_id и суммарную зарплату за год в следующем виде:
Michael Hartstein занимает должность MK_MAN, и зарплата за год составляет 156 000.
6. Вывести значения столбцов employee_id, department_id, first_name, last_name, department_id, job_id, salary, bonus для сотрудников, у которых зарплата salary <10 000. Вычисляемый столбец bonus содержит размер премии, которая вычисляется по формуле: Salary * (1 +0.1 * rating_e). Выводимые данные упорядочить по размеру премии.
7. Вывести значения столбцов employee_id, department_id, first_name, last_name, job_id сотрудников, которые работают в отделах 50 или 80, но не являются менеджерами. Менеджерами являются те сотрудники, у которых столбец job_id содержит подстроку MAN.
8. Вывести значения столбцов employee_id, department_id, first_name, last_name, job_id, salary сотрудников, у которых код должности (job_id) имеет значение IT_PROG и зарплата имеет одно из значений (4800, 6000, 9000), а также о сотрудниках, у которых код должности (job_id) имеет значение SA_REP, а зарплата находится вне диапазона от 7000 до 9000.
Глава 3. Типы данных и встроенные функции
Каждый столбец таблицы реляционной базы данных должен содержать данные только одного типа. Тип данных определяет значения, которые могут быть присвоены элементам данного столбца и операции, в которых могут участвовать элементы данного столбца.
Типы данных можно разбить на три категории:
— числовые типы;
— символьные типы;
— типы даты и времени.
Следует иметь в виду, что количество типов в каждой категории достаточно велико, и в этом разделе мы рассмотрим только наиболее часто используемые типы данных, которые далее будут использоваться в примерах.
При изучении каждого типа будут приведены основные встроенные функции, аргументы которых могут иметь рассматриваемый тип.
Для вывода результатов выполнения выражений с использованием рассматриваемых функций мы будем использовать оператор SELECT. Но данный оператор должен обязательно содержать предложение:
FROM {источник данных}
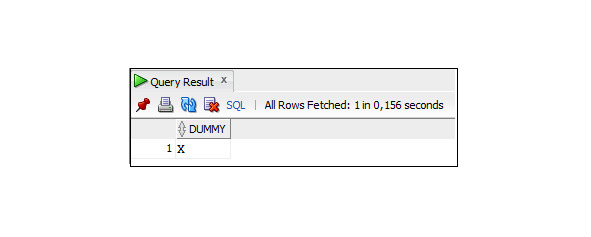
В качестве источника данных мы будем использовать служебную таблицу DUAL, которая доступна для всех пользователей. Таблица DUAL имеет один столбец с именем DUMMY, тип данных которого VARCHAR2 (), и содержит одну строку со значением X.
Пример 3.1. Вывод содержимого таблицы DUAL
SELECT *
FROM Dual;
Числовые типы
Числовые типы используются для работы с числовыми данными. Можно использовать следующие форматы чисел:
— целые числа;
— вещественные числа в формате с фиксированной точкой;
— вещественные числа в формате с плавающей точкой.
При определении столбцов, содержащих числовые данные, можно использовать следующие спецификации:
NUMBER (n) — целое число не более n цифр;
NUMBER (n,m) — вещественное число с фиксированной точкой,
n — максимальное число цифр в записи числа а m — число цифр справа от десятичной точки;
NUMBER — вещественное число с плавающей точкой с точностью до 38 цифр.
В таблице 3.1 приведены основные функции, которые можно использовать при обработке данных числового типа.
Таблица 3.1. Основные функции для обработки чисел

Функция ROUND
Выполняет округление до ближайшего числа с заданной точностью (результат может быть не целым). Синтаксис:
ROUND (n,m)
n — численное значение;
m — точность округления.
Значение m может быть отрицательным, позиция округления отсчитывается влево.
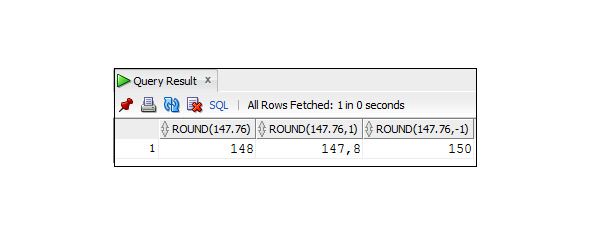
Пример 3.2. Примеры использования функции ROUND
SELECT ROUND (147.76), ROUND (147.76,1), ROUND (147.76, -1)
FROM Dual;
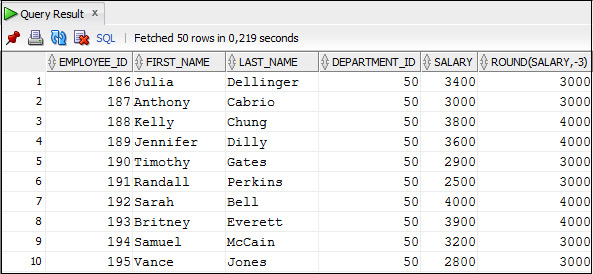
Пример 3.3. Вывести значение зарплаты, округленное до 1000
SELECT employee_id, first_name, last_name, department_id, salary, ROUND (salary, -3)
FROM Employees;
Функция TRUNC
Усекает (отбрасывает) значащие цифры справа без округления. Синтаксис:
TRUNC (n, m)
Параметры n, m аналогичны параметрам функции ROUND.
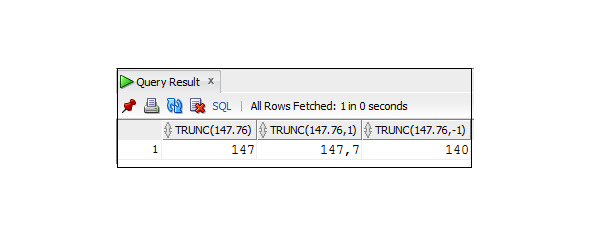
Пример 3.4. Пример использования функции TRUNC
SELECT TRUNC (147.76), TRUNC (147.76,1), TRUNC (147.76, -1)
FROM Dual;
Функция MOD
Возвращает остаток от деления n на m. Синтаксис:
MOD (n,m)
где n и m — численные значения целого или вещественного типа.
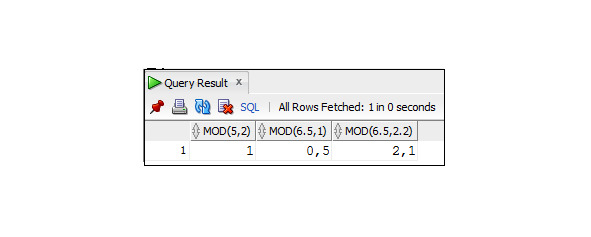
Пример 3.5. Пример использования функции MOD
SELECT mod (5,2), mod (6.5,1),mod (6.5,2.2)
FROM Dual;
Пример 3.6. Найти сотрудников с нечетным рейтингом
SELECT employee_id, first_name, last_name,
department_id, rating_e
FROM Employees
WHERE MOD (rating_e,2) =1;
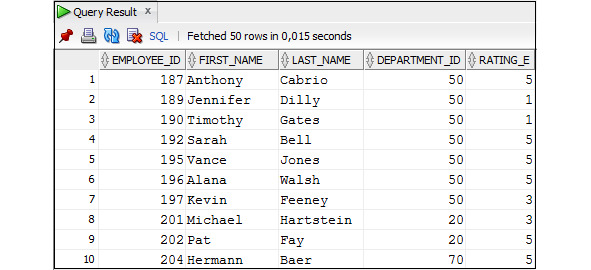
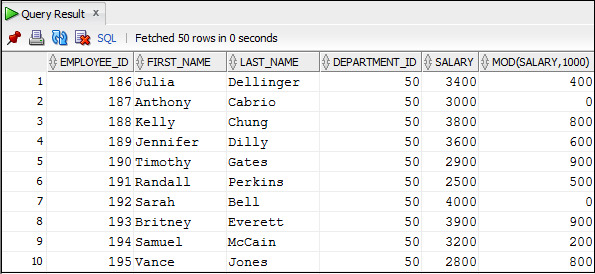
Пример 3.7. Вывести ту часть зарплаты сотрудника, которая меньше 1000
SELECT employee_id, first_name, last_name, department_id,
salary, MOD (salary,1000)
FROM Employees;
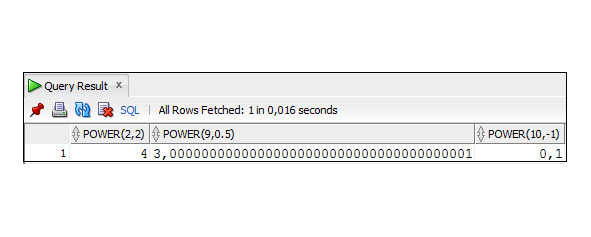
Функция POWER
Возводит число x в степень n. Синтаксис:
POWER (x,n)
x — численное значение;
n — степень, может иметь вещественный тип и отрицательное значение.
Пример 3.8. Пример использования функции POWER
SELECT POWER (2,2),POWER (9,0.5),POWER (10, -1)
FROM Dual;
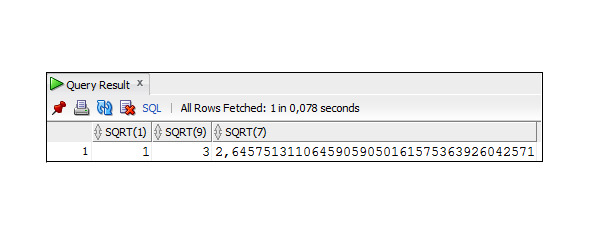
Функция SQRT
Возвращает квадратный корень от числа. Синтаксис:
SQRT (x)
x — численное значение;
Пример 3.9. Пример использования функции SQRT
SELECT SQRT (1), SQRT (9),SQRT (7)
FROM Dual;
Символьные типы
Символьные типы используются для работы с данными, представленными в виде текста. Основными символьными типами являются:
CHAR (n) — строка символов фиксированной длины n, позволяет хранить символьные данные длиной от 1 до 2000 символов. Если длина (n) явно не указана, то она считается равной 1. Если длина присваиваемого значения будет меньше n, то оно дополняется пробелами справа.
VARCHAR2 (n) — строка символов переменной длины, которая может содержать не более n — 1 символа, предназначена для хранения символьных данных длиной от 1 до 4000 символов. Хранит столько символов, сколько содержит присваиваемое значение. Значение n трактуется как максимально возможная длина строки.
Типы NCHAR (n) и NVARCHAR2 (n) — предназначены для хранения символьных данных фиксированной и переменной длинны в формате Unicode.
Функции для обработки символьных данных
Эти функции принимают на вход строку символов, обрабатывают ее и возвращают результат обработки. Источником данных может быть: строковая константа, столбец таблицы, выражение. Все функции для обработки символьных данных можно разбить на две группы:
— функции преобразования регистра;
— функции обработки строк.
Таблица 3.2. Функции преобразования регистра

Пример 3.10. Вывести название товара, используя различные функции преобразования регистра
SELECT
UPPER (Product_name) As UPPER,
LOWER (Product_name) As LOWER,
INITCAP (Product_name) As INITCAP
FROM Products
WHERE product_id = 50;
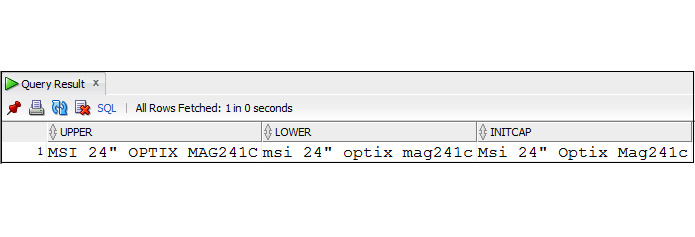
Довольно часто столбец, имеющий символьный тип, содержит значения в различных регистрах. Например, столбец first_name может содержать как значение DAVID, так и значение David. В этом случае запрос, содержащий условие выбора: first_name = ′DAVID′ или first_name = ′David′ выведет только часть необходимых данных. Эту проблему можно решить, используя функции преобразования регистра.
Пример 3.11. Вывести данные о сотрудниках, у которых столбец first_name имеет значение DAVID, или David, или david
SELECT employee_id, first_name, last_name, department_id, salary
FROM Employees
WHERE UPPER (first_name) = ′DAVID′;
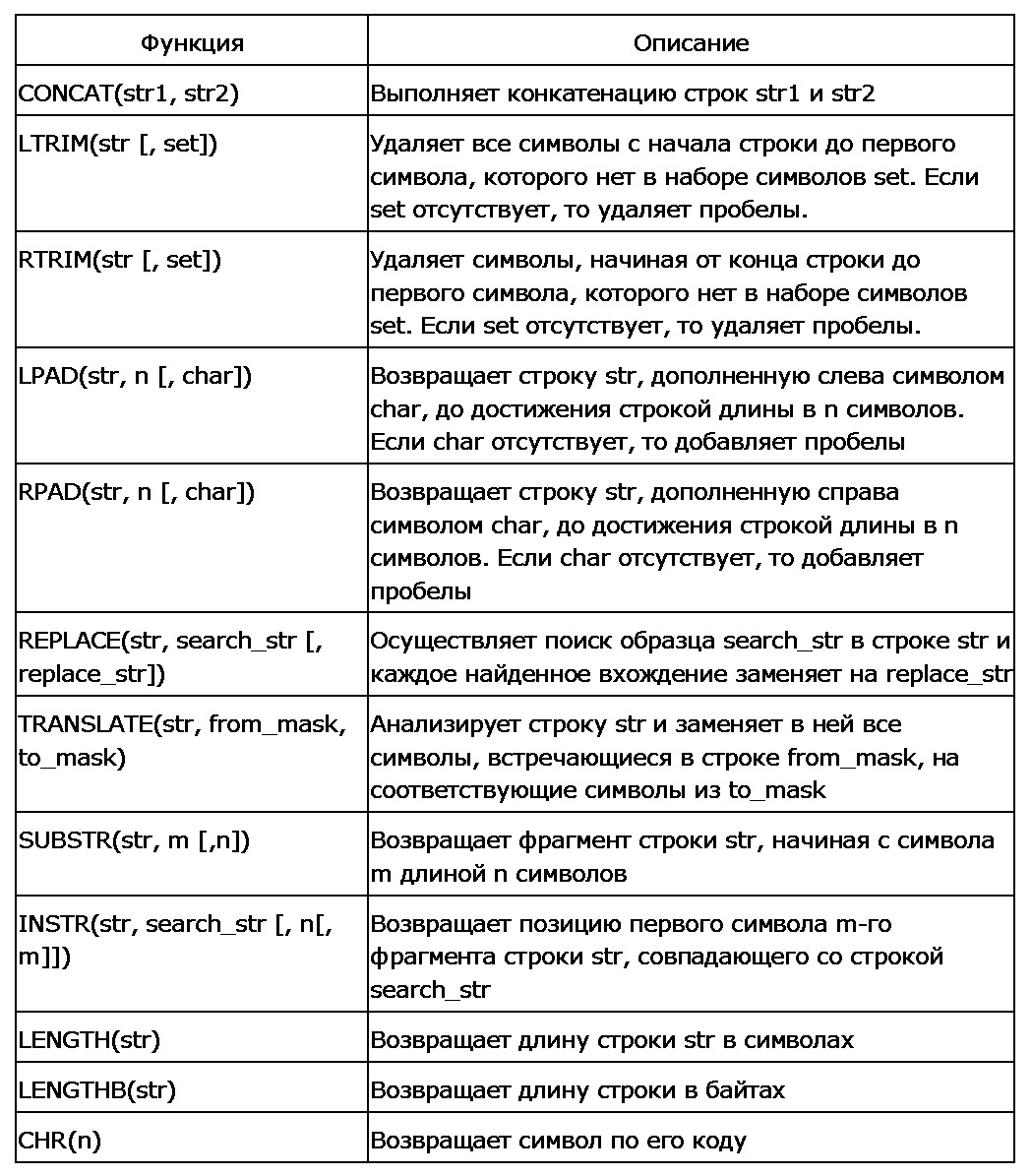
Таблица 3.3. Функции обработки строк
Примеры использования функций обработки строк
Функции LPAD () и RPAD () можно использовать для отображения результата выполнения запроса в виде, который более удобен для восприятия.
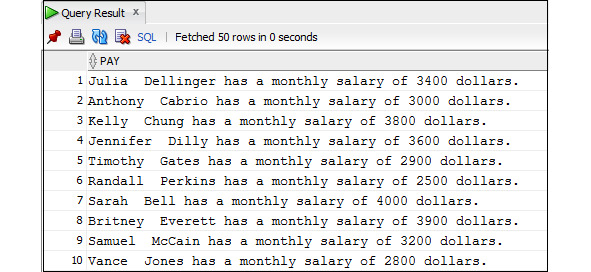
Пример 3.12. Вывод данных о зарплате сотрудников без использования функций LPAD () и RPAD ()
SELECT first_name||′ ′||last_name || ′ has a monthly salary of ′
|| salary || ′ dollars. ′ AS Pay
FROM Employees;
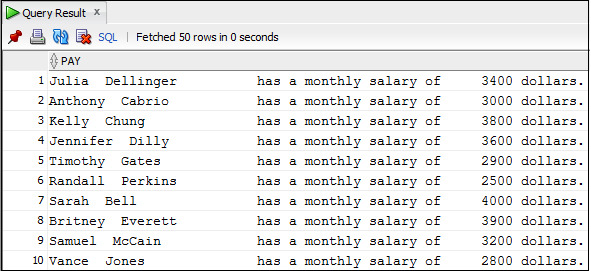
Пример 3.13. Вывод данных о зарплате сотрудников c использованием функций LPAD () и RPAD ()
SELECT RPAD (first_name||′ ′||last_name,25)
|| ′ has a monthly salary of ′
|| LPAD (salary,6) || ′ dollars.» AS Pay
FROM Employees;
Рассмотрим более подробно функцию INSTR, которая часто используется при работе с символьными данными.
Функция INSTR возвращает номер позиции в строке str, начиная с которой строка search_str входит в строку str. Если вхождений не найдено, то функция возвращает значение 0. Синтаксис:
INSTR (str, search_str [, n [, m]])
— str — исходная строка;
— search_str — строка поиска;
— n — начало поиска, определяет начальную позицию, с которой следует начинать поиск;
— m — вхождение, определяет номер вхождения, который следует возвратить.
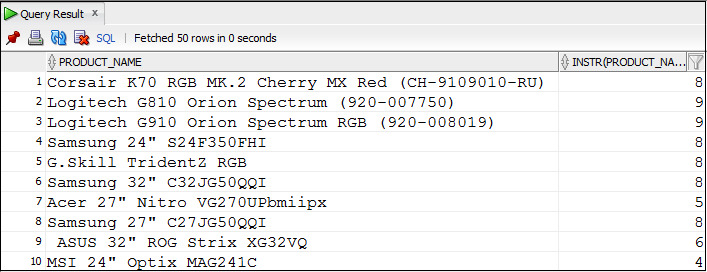
Пример 3.14. Использование функции INSTR для нахождения позиции первого пробела в названии товара
SELECT product_name, INSTR (product_name, ′ ′)
FROM Products;
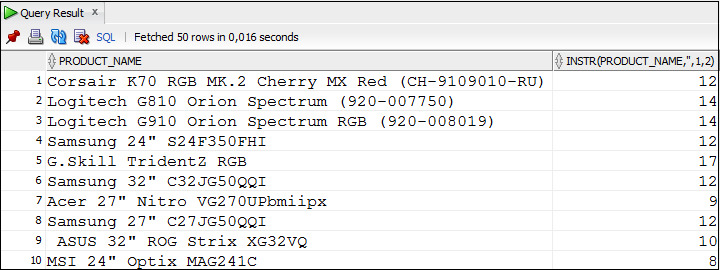
Пример 3.15. Использование функции INSTR для нахождения позиции второго пробела в названии товара
SELECT product_name, INSTR (product_name, ′ ′,1,2)
FROM Products;
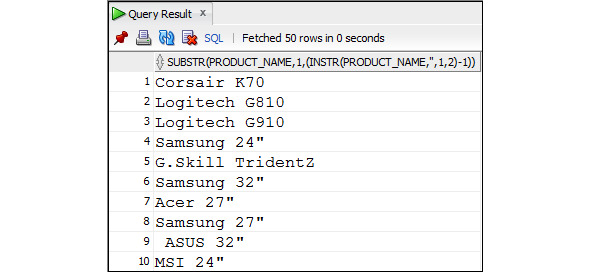
Используя функцию SUBSTR совместно с функцией INSTR, можно вывести часть строчного значения, которая состоит из одного или нескольких слов. Следует иметь в виду, что если название товара состоит из двух слов, то второй пробел найден не будет и этот товар не попадет в результат выполнения запроса.
Пример 3.16. Вывести первые два слова из названия товара
SELECT SUBSTR (product_name,1,
(INSTR (product_name, ′ ′,1,2) -1))
FROM Products;
Пример 3.17. Вывести названия товаров, первое слово которых состоит из трех символов
SELECT product_id, product_name
FROM Products
WHERE Length (SUBSTR (product_name,1,
(INSTR (product_name, ′ ′) -1))) =3;
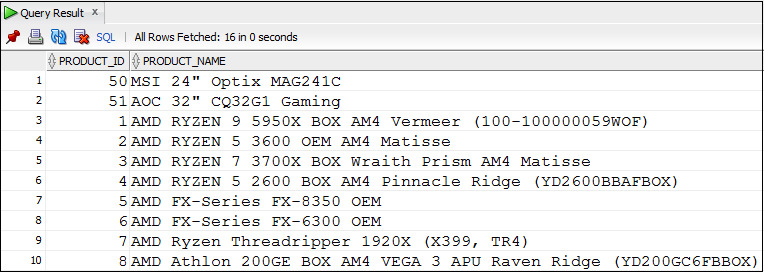
Используя функцию INSTR, можно осуществлять поиск по части строчного значения.
Пример 3.18. Вывести данные о товарах, в названии которых есть слово Core
SELECT *
FROM Products
WHERE INSTR (UPPER (product_name), ′CORE»′> 0;
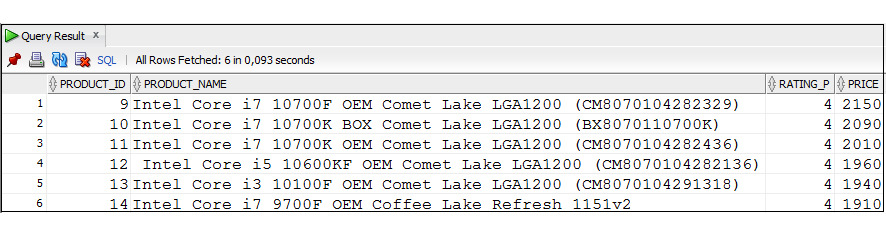
Типы даты и времени
Эти типы используются для работы с данными, представляющими собой даты с учетом времени. Тип Date является основным при работе с данными, представляющими собой дату и время. При использовании этого типа данные хранятся в формате DD-MM-YY HH: MI: SS, где:
DD — двузначное значение дня;
MM — двузначный номер месяца;
YY — две последние цифры года;
HH, MI, SS — двузначные значения часа, минуты и секунды.
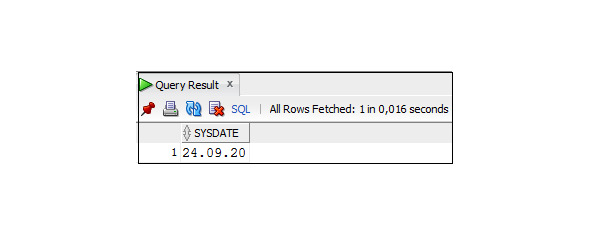
При выводе значений данного типа по умолчанию отображается дата. Для получения текущей даты в формате Date используется функция SYSDATE.
Пример 3.19. Вывод текущей даты в формате по умолчанию
SELECT SYSDATE
FROM Dual;
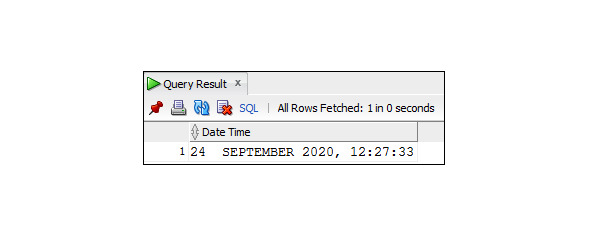
Для отображения и обработки полного значения, содержащего время, используются специальные функции.
Пример 3.20. Вывод текущей даты с использованием функции TO_CHAR
SELECT TO_CHAR (SYSDATE, ′DD MONTH YYYY, HH24:MI: SS′)
As Date_Time
FROM Dual;
К типам данных, используемых для представления значений даты и времени, также относятся:
— TIMESTAMP — аналогичен типу Date, но время хранится с точностью до миллиардной доли секунды. Для получения текущей даты в этом формате используется функция LOCALTIMESTAMP;
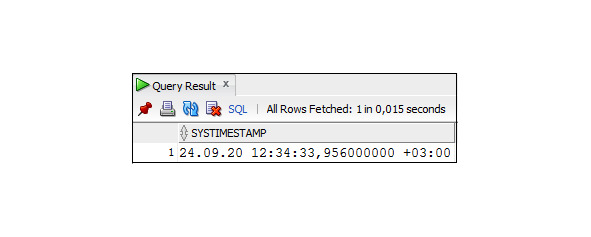
— TIMESTAMP WITH TIME ZONE — хранит вместе со значением даты и времени информацию о часовом поясе. Часовым поясом называется смещение от времени по Гринвичу. Для получения текущей даты в этом формате используется функция SYSTIMESTAMP.
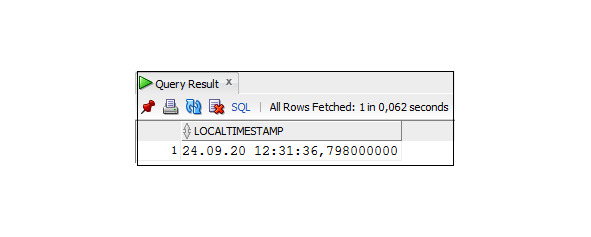
Пример 3.21. Использование функция LOCALTIMESTAMP
SELECT LOCALTIMESTAMP
FROM DUAL;
Пример 3.22. Использование функция SYSTIMESTAMP
SELECT SYSTIMESTAMP
FROM DUAL;
Функции для работы с данными, имеющими тип даты и времени
Для обработки данных, имеющих тип Date, можно использовать функции, представленные в таблице 3.4.
Таблица 3.4. Функции для работы с данными, имеющими тип даты и времени
Значения, имеющие этот тип, могут участвовать в арифметических операциях с некоторыми ограничениями. Например, разница меду двумя датами равна количеству дней, прошедших между этими датами, но нельзя непосредственно складывать значения, имеющие тип Date.
Прибавление целого значения n к значению типа Date эквивалентно прибавлению n дней к дате. Прибавление значения n/24 к значению типа Date эквивалентно прибавлению n часов к дате.
Если в выражении участвует строка, содержащая значение даты, то ее рекомендуется преобразовать к значению типа Date, используя функцию TO_DATE ().
Рассмотрим примеры, в которых значения, имеющие тип Date, участвуют в арифметических выражениях.
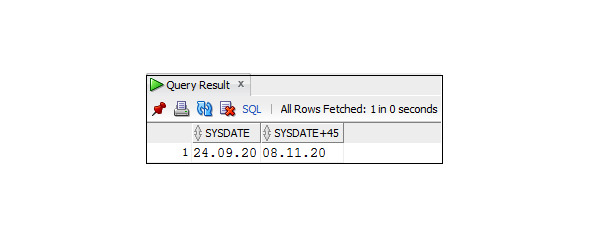
Пример 3.23. Вывод значения текущей даты, увеличенного на 45 дней
SELECT SYSDATE, SYSDATE +45
FROM DUAL;
Пример 3.24. Вывод значения текущей даты и времени, увеличенного на два часа
SELECT TO_CHAR (SYSDATE, ′DD MONTH YYYY, HH24:MI: SS′)
As Date1,
TO_CHAR (SYSDATE +2/24, ′DD MONTH YYYY, HH24:MI: SS′)
As Date2
FROM DUAL;
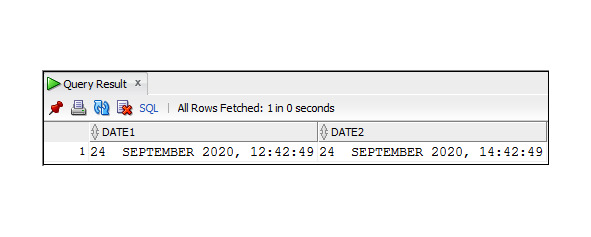
Пример 3.25. Определить количество дней, прошедших между датой приема на работу и сегодняшним днем
SELECT employee_id, ROUND (SYSDATE — hire_date AS DAYS, -2)
FROM Employees;
Следует обратить внимание на то, что этот запрос возвращает дробное значение, так как значение, возвращаемое функцией SYSDATE, содержит текущее время, которое трактуется как часть суток: например, 12 часов отобразятся в виде значения 0,5.
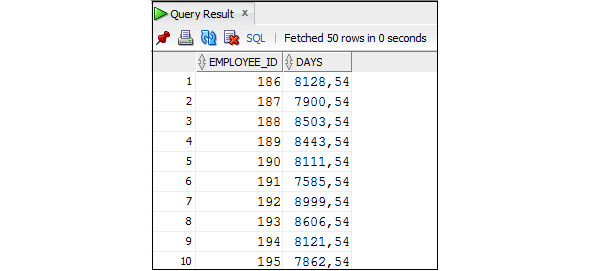
Пример 3.26. Определить количество недель, прошедших между датой приема на работу и сегодняшним днем
SELECT employee_id, TRUNC ((SYSDATE — hire_date) /7)
AS WEEKS
FROM Employees;
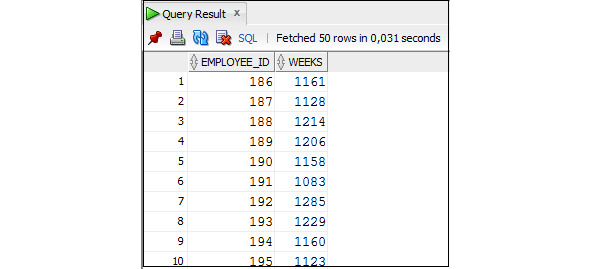
Для определения интервалов между двумя датами в месяцах следует использовать специальную функцию MONTHS_BETWEEN.
Пример 3.27. Вывести данные о сотрудниках и количестве месяцев, прошедших между датой приема на работу и сегодняшним днем
SELECT employee_id, first_name, last_name,
department_id, hire_date,
—
TRUNC (MONTHS_BETWEEN (SYSDATE, hire_date)) AS MONTHS
— —
FROM Employees;
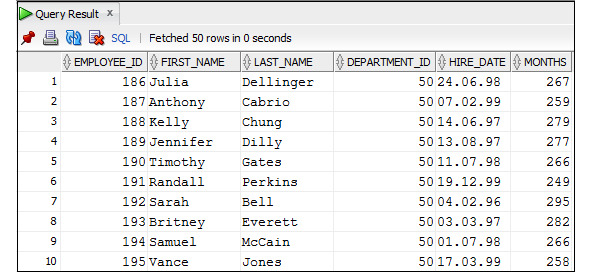
Пример 3.28. Вывести данные о сотрудниках, которые проработали более 30 лет
SELECT employee_id, first_name, last_name, salary,
department_id, hire_date
FROM Employees
WHERE MONTHS_BETWEEN (SYSDATE, hire_date)> 360;
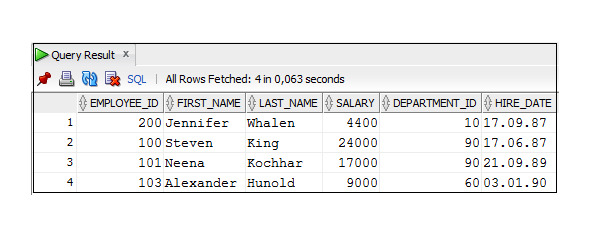
Функция NEXT_DAY (x, день недели) возвращает следующую ближайшую дату, соответствующую определенному дню недели: например, среда.
Пример 3.29. Использование функции NEXT_DAY
SELECT SYSDATE AS «Сегодня», EXT_DAY (SYSDATE, ′Tuesday′)
AS Tuesday
FROM DUAL;
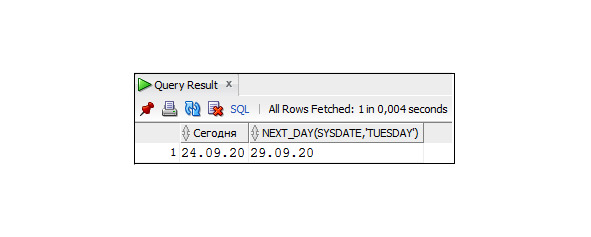
Функция LAST_DAY (x) возвращает дату, соответствующую последнему дню месяца, которому принадлежит x.
Пример 3.30. Использование функции LAST_DAY
SELECT SYSDATE, LAST_DAY (SYSDATE)
FROM DUAL;
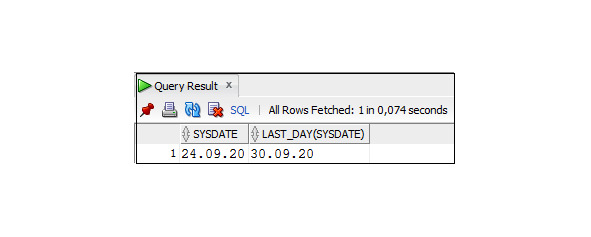
Функция ROUND (x, {параметр}) округляет дату x, если параметр отсутствует, то до начала ближайших суток; если {параметр} = MM/ MON / MONTH — то до начала ближайшего месяца; если параметр = YY / YYYY /YEAR — то до начала ближайшего года.
Пример 3.31. Использование функции ROUND c параметром MM
SELECT ROUND (TO_DATE (′12.05.2018′, ′DD.MM.YYYY′),′MM′)
As ′′ ROUND MONTCH 12.05.2018 ′′,
ROUND (TO_DATE (′20.05.2018′, ′DD.MM.YYYY′),′MM′)
As ′′ ROUND MONTCH 20.05.2018 ′′
FROM DUAL;
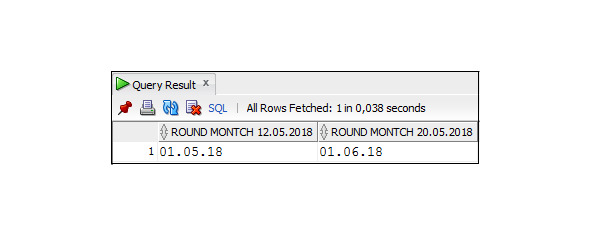
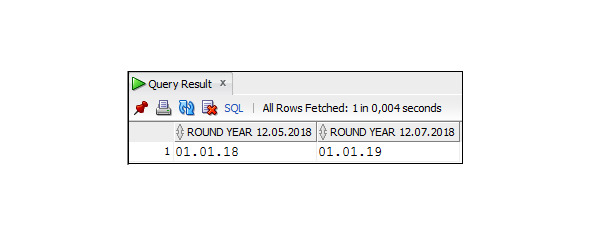
Пример 3.32. Использование функции ROUND c параметром YYYY
SELECT ROUND (TO_DATE (′12.05.2018′, ′DD.MM.YYYY′),′YYYY′)
As ′′ ROUND YEAR 12.05.2018 ′′,
ROUND(TO_DATE(′12.07.2018′,′DD.MM.YYYY′),′YYYY′)
As ′′ ROUND YEAR 12.07.2018 ′′
FROM Dual;
Функция TRUNC (x, {параметр}) отличается от ROUND тем, что возвращает начало текущих суток, начало текущего месяца, начало текущего года соответственно.
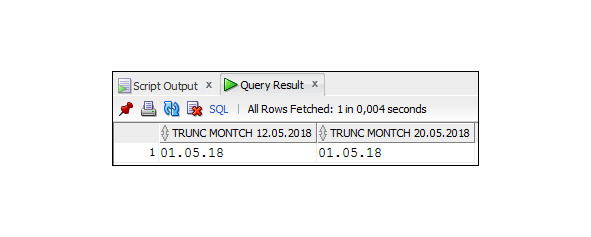
Пример 3.33. Использование функции TRUNC c параметром MM.
SELECT TRUNC (TO_DATE (′12.05.2018′, ′D.MM.YYYY′),′MM′)
As ′′ TRUNC MONTCH 12.05.2018 ′′,
TRUNC (TO_DATE (′20.05.2018′, ′D.MM.YYYY′),′MM′)
As ′′ TRUNC MONTCH 20.05.2018 ′′
FROM DUAL;
Функция EXTRACT
Функция EXTRACT возвращает значение заданного поля даты-времени из значения, имеющего тип date. Синтаксис:
EXTRACT ({часть даты} FROM {дата})
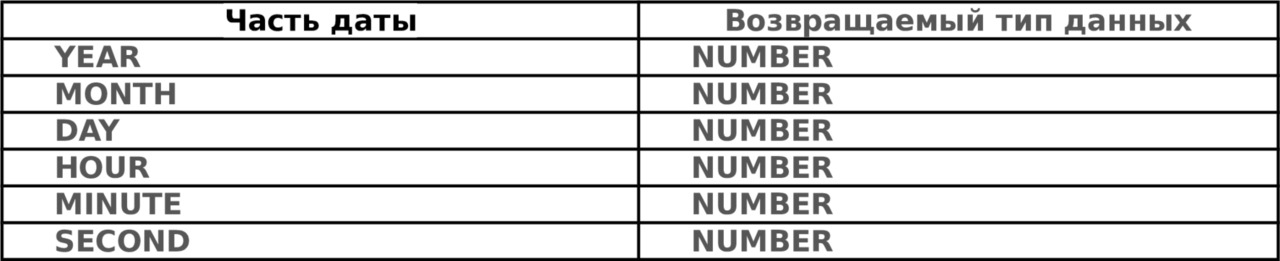
Таблица 3.5. Часть даты, возвращаемая функцией EXTRACT
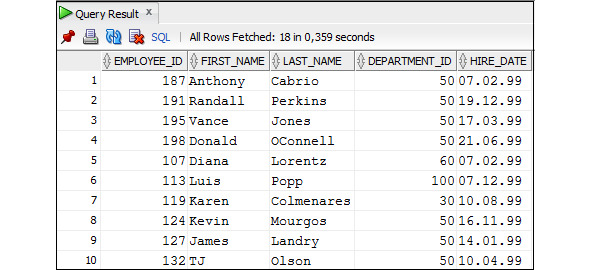
Пример 3.34. Вывести данные о сотрудниках, которые были приняты на работу в 1999 году
SELECT employee_id, first_name, last_name, department_id, hire_date
FROM Employees
WHERE EXTRACT (YEAR FROM hire_date) =1999;
Функции конвертирования
В СУБД Oracle используются три простых типа данных:
— строки CHAR, VARCHAR2;
— числа NUMBER;
— даты DATE.
Сервер Oracle может конвертировать данные, имеющие тип VARCHAR2 и CHAR, в данные типов NUMBER и DATE. Он может преобразовать данные, имеющие тип NUMBER или DATE, в данные типов CHAR и VARCHAR2.
Преобразование может осуществляться явным и неявным образом. Неявное преобразование осуществляется при выполнении следующего оператора:
{столбец} тип А = {начение/выражение} тип Б
При выполнении этого оператора значение или выражение в правой части преобразуется к типу, который имеет левая часть.
— WHERE order_date= ′2-04-2017′;
— WHERE order_date= ′26-apr-2017′;
— WHERE order_date= ′26-апр-2017′;
В этих примерах в зависимости от языковых настроек во втором или третьем операторе возникнет ошибка. Если используемый язык — английский, то ошибка возникнет в третьем операторе, Если используемый язык — русский, то ошибка возникнет во втором операторе. Следует иметь в виду, что значение ′26-APR-2017′ имеет тип строки символов.
— WHERE salary = ′4200′;
— WHERE salary = ′4000′+200;
— WHERE salary = ′4.200′;
— WHERE salary = ′$4200′;
В этих примерах первый и второй операторы будут успешно выполнены, при выполнении третьего и четвертого операторов возникнут ошибки, так как эти строки содержат недопустимые символы.
Для того чтобы неявное преобразование было возможно, необходимо, чтобы присваиваемое значение соответствовало формату столбца, которому это значение присваивается.
Хотя неявное преобразование возможно, лучше для этого использовать специальные функции. Чаще всего функции преобразования типов используются для того, чтобы числовые данные и даты отобразить в наиболее удобном (понятном) виде.
Четыре типа преобразования:
— число в строку символов;
— строку символов в число;
— дату в строку символов;
— строку символов в дату.
Преобразование чисел в строку символов
Числа, хранящиеся в базе данных, не имеют форматирования. Это означает, что они не имеют символов валюты, запятых, десятичных знаков и других параметров форматирования. Чтобы добавить форматирование, необходимо преобразовать число в строку символов. Для этого используется функция:
TO_CHAR (Х {маска преобразования})
Для преобразования численного значения в строку можно использовать элементы формата, представленные в таблице 3.6.
Таблица 3.6. Элементы маски преобразования, используемые в функции TO_CHAR
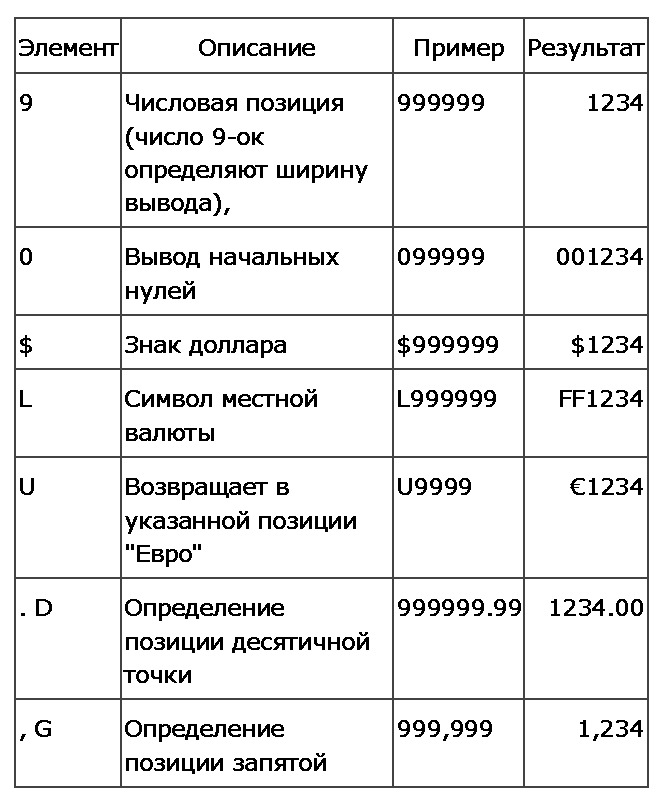
Пример 3.35. Использование функции TO_CHAR
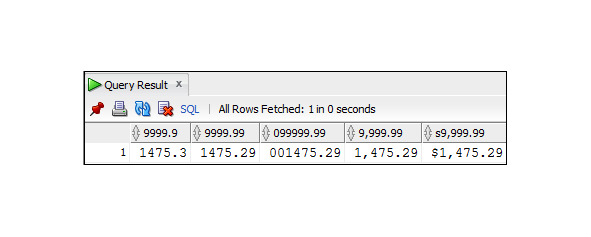
SELECT TO_CHAR (1475.29, ′9999.9′) As ′′9999.9′′,
TO_CHAR (1475.29, ′9999.99′) As ′′9999.99′′,
TO_CHAR (1475.29, ′099999.90′) As ′′099999.99′′,
TO_CHAR (1475.29, ′9,999.99′) As ′′9,999.99′′,
TO_CHAR (1475.29, ′$9,999.99′) As ′′$9,999.99′′
FROM DUAL;
Преобразование строки символов в число
Для преобразования символьного значения в число используется функция TO_NUMBER. Синтаксис:
TO_NUMBER (х, {маска преобразования})
Строка x может содержать цифры и символы, которые соответствуют заданному формату. Параметр {маска преобразования} определяет, как нужно интерпретировать символьное представление числа, может содержать те же элементы, которые были определены для функции TO_CHAR.
Если число символов в строке будет больше числа элементов формата, то возникает ошибка. Примеры преобразований, при которых возникает ошибка:
TO_NUMBER (′1475.29′,′999.99′)
TO_NUMBER (′1475.29′, ′9999.9′)
Если число символов в строке будет меньше числа элементов формата, то возникает ошибка.
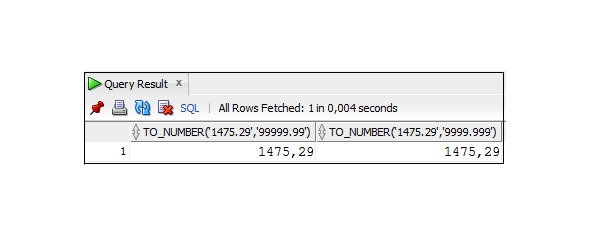
Пример 3.36. Использование функции TO_NUMBER
SELECT TO_NUMBER (′1475.29′, ′99999.99′),
TO_NUMBER (′1475.29′, ′9999.999′)
FROM DUAL;
Преобразование строки символов в дату
Для преобразования строки символов в значение, имеющее формат даты, используется функция:
TO_DATE (х, {маска преобразования})
Строка x содержит символьное значение даты. Параметр {маска преобразования} определяет, как нужно интерпретировать символьное представление даты.
Маска может содержать элементы формата, представленные в таблице 3.7.
Таблица 3.7. Элементы маски преобразования, используемые в функции TO_DATE
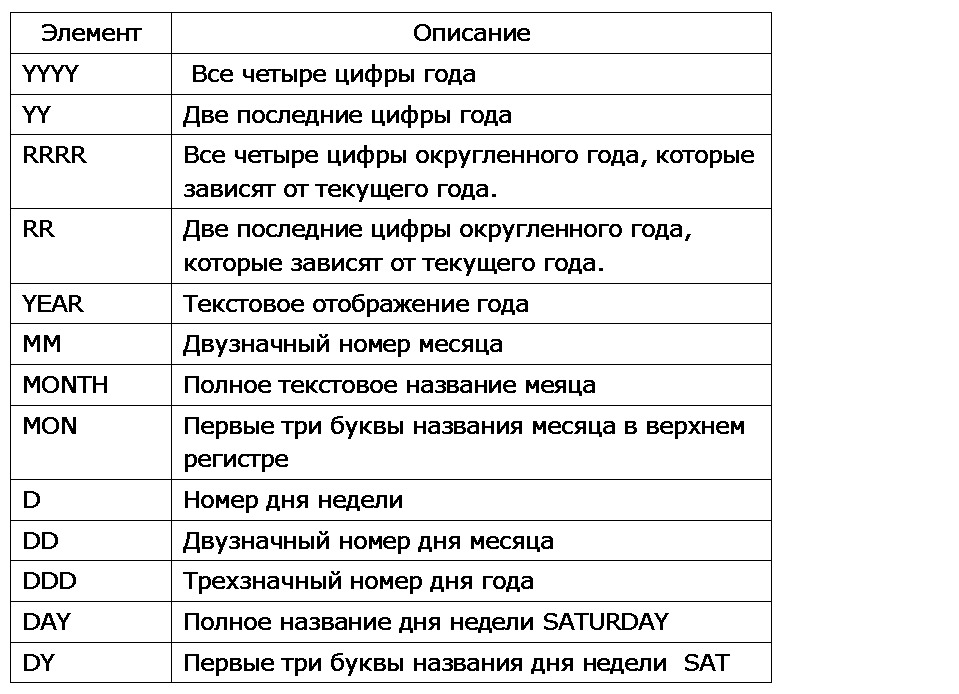
Пример 3.37. Использование функции TO_DATE
SELECT TO_DATE (′01-SEP-2018′, ′DD-MON-YYYY′)
As ′′01-SEP-2018′′,
TO_DATE (′09/01/18′, ′MM/DD/RR′) As ′′ 09/01/18′′,
TO_DATE (′01092018′, ′DDMMYYYY′) As ′′ 01092018′′
FROM DUAL
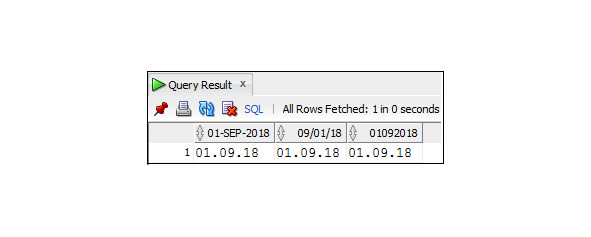
Замечание: срока преобразуется в дату, а дата выводится в установленном формате даты. Для ввода и вывода значения времени используется маска HH24:MI: SS, где:
— HH24 — двузначное значение часа в 24-часовом формате;
— MI — двузначное значение минут;
— SS — двузначное значение секунд.
Замечание: введенное значение времени сохраняется, но по умолчанию не отображается. Для отображения времени в значениях, имеющих тип Date, необходимо использовать функцию TO_CHAR.
Пример 3.38. Ввод и вывод значения даты, содержащей время
SELECT TO_CHAR (TO_DATE (′01-SEP-2018, 14:45:51′,
′DD-MON-YYYY HH24:MI: SS′),′DD MONTH YYYY, HH24:MI: SS′)
As Date_Time
FROM DUAL
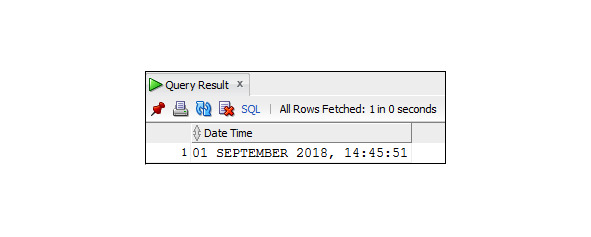
Использование формата RR
Этот формат связан с проблемой 2000 года. Определяет год, если в дате заданы две последние цифры года. Если две последние цифры лежат в диапазоне от 0 до 49, то год принадлежит текущему столетию. Если две последние цифры лежат в диапазоне от 50 до 99, то год принадлежит предыдущему столетию.
TO_DATE (′04-JUL-18′, ′DD-MON-RR′) → 04/JUL/2018
TO_DATE (′04-JUL-75′, ′DD-MON-RR′) → 04/JUL/1975
Более полная информация о правилах использования формата RR приведена в таблице 3.8.
Таблица. 3.8. Правила преобразования года в формате RR
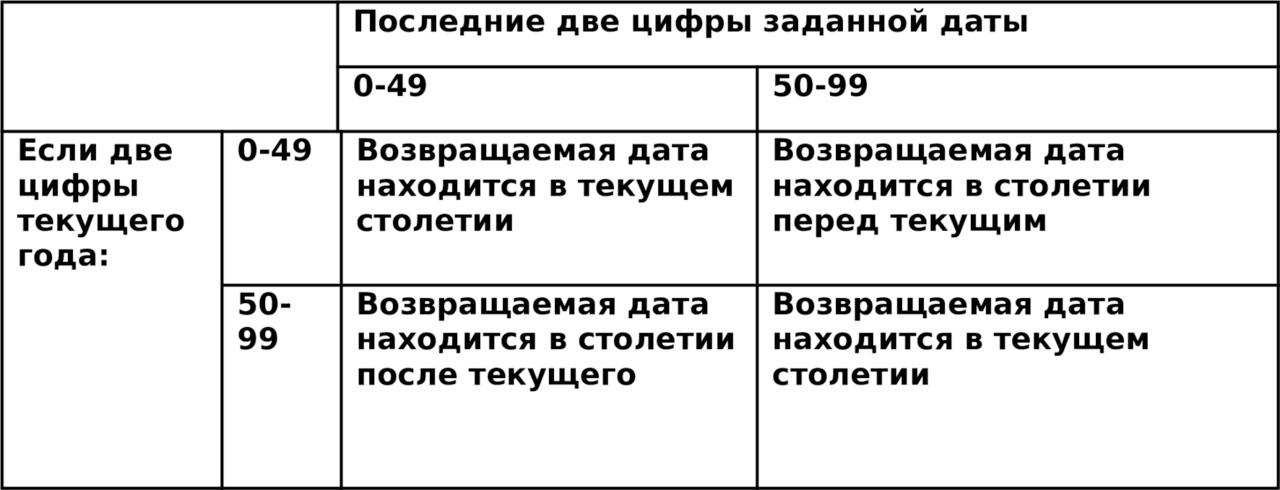
При использовании формата YY первые две цифры всегда соответствуют текущему столетию. Совет: при работе с датами всегда указывайте четыре цифры года.
Пример 3.39. Использование формата RR при вводе двузначного значения года
SELECT TO_CHAR (TO_DATE
(′04-07-18′, ′DD-MM-RR′),′DD-MON-YYYY′) As DAT1,
TO_CHAR (TO_DATE (′04-07-75′, ′DD-MM-RR′),′DD-MON-YYYY′)
As DAT2
FROM DUAL;
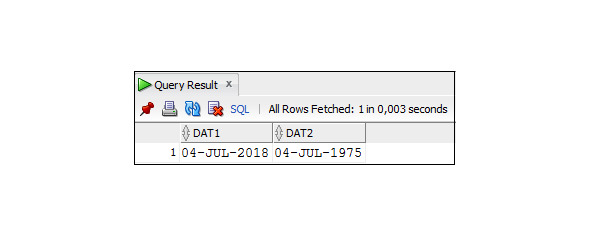
Пример 3.40. Использование формата YY при вводе двузначного значения года
SELECT TO_CHAR (TO_DATE (′04-07-18′, ′DD-MM-YY′),
′DD-MON-YYYY′) As DAT1,
TO_CHAR (TO_DATE (′04-07-75′, ′DD-MM-YY′),
′DD-MON-YYYY′) As DAT2
FROM DUAL;
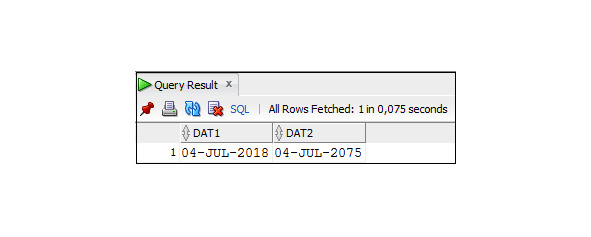
Преобразование даты в строку символов
Это преобразование выполняется для того, чтобы отобразить значение, имеющее тип Date в требуемом виде. Для осуществления этого преобразования используется функция:
TO_CHAR (х, {маска преобразования})
где: x — значение, имеющее тип Date, а строка {маска преобразования}) — маска, которая определяет, как нужно отобразить значение x; может содержать те же элементы, которые были определены для функции TO_DATE.
Пример 3.41. Использование функции TO_CHAR для преобразования значения, имеющего тип Date, в строку символов
SELECT TO_CHAR (SYSDATE, ′ DD/MM/YYYY′) AS RESULT1,
TO_CHAR (SYSDATE, ′ DD MON, YYYY′) AS RESULT2,
TO_CHAR (SYSDATE, ′ DD DAY MONTH, YYYY′) AS RESULT3,
TO_CHAR (SYSDATE, ′ DD — MONTH -YYYY, HH24:MI: SS′)
AS RESULT4
FROM DUAL;
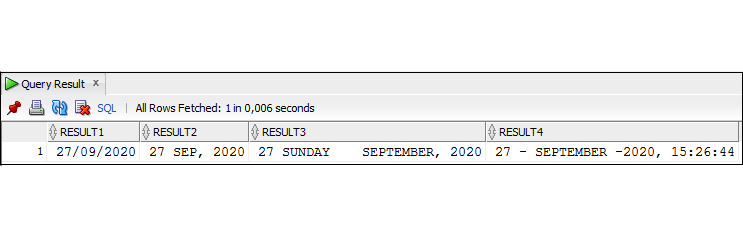
Используя функцию TO_CHAR при работе с данными, имеющими тип Date, можно выделить определенную часть даты: день, месяц, год.
Пример 3.42. Вывести данные о сотрудниках, которые были приняты на работу в 2000 году
SELECT employee_id, first_name, last_name, hire_date, salary
FROM Employees
WHERE TO_CHAR (hire_date, ′YYYY′) = ′2000′;
Работа с неопределенными значениями
Если при вводе новой строки в таблицу столбцу не будет присвоено значение, то этот столбец будет иметь значение NULL — не определено. Это может происходить по двум основным причинам. Первая причина: в момент ввода строки значение столбца неизвестно, в этом случае значение будет присвоено позже. Вторая причина: значение не может быть присвоено исходя из правил предметной области. Для рассматриваемой базы данных вторую причину можно пояснить на примере столбца commission_pct таблицы Employees. Некоторым сотрудникам полагаются комиссионные, столбец commission_pct содержит значение комиссионных. Зарплата таких сотрудников рассчитывается по формуле: Salary * (1 + commission_pct). У сотрудников, которым комиссионные не полагаются, значение столбца commission_pct не может быть определено.
При работе с арифметическими и логическими выражениями следует иметь в виду следующее: арифметическое выражение вернет значение NULL, если один или несколько операндов будут иметь значение NULL; результатом операции сравнения будет NULL, если один или оба операнда будут иметь значение NULL.
Результат логических операций AND и OR приведен в таблицах 3.9 и 3.10 соответственно.
Таблица 3.9. Таблица истинности логической функции AND с учетом значений NULL

Таблица 3.10. Таблица истинности логической функции OR с учетом значений NULL

Для корректной обработки данных, которые могут иметь значения NULL, следует использовать специальные функции.
Функция NVL
Позволяет заменить значение NULL фактическим значением. Синтаксис:
NVL (x,y)
Возвращает x, если x не NUUL, и возвращает y, если x имеет значение NUUL, например: NVL (commission_pct,0).
Рассмотрим примеры использования функции NVL при решении конкретных задач.
Пример 3.43. Вывести данные о сотрудниках, включая размер комиссионных, которые работают в отделах 30 и 80
SELECT employee_id, first_name, last_name, department_id,
salary, NVL (commission_pct,0)
FROM Employees
WHERE department_id IN (30,80)
ORDER BY department_id;
Пример 3.44. Вывести данные о сотрудниках, включая зарплату с учетом комиссионных (полная зарплата), которые работают в отделах 30 и 80, упорядочив их в порядке убывания значений зарплаты с учетом комиссионных
SELECT employee_id, first_name, last_name, department_id,
salary* (1+NVL (commission_pct,0)) AS total_salary
FROM Employees
WHERE department_id IN (30,80)
ORDER BY total_salary DESC;
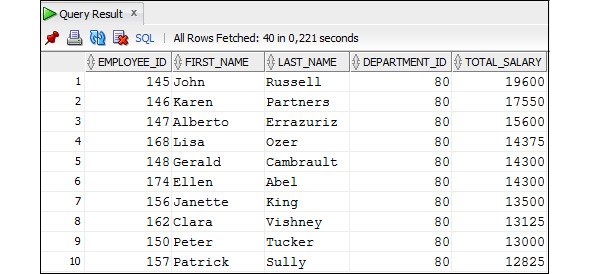
Псевдонимы столбцов можно использовать в предложении ORDER BY, но нельзя использовать в предложении WHERE.
Пример 3.45. Вывести данные о сотрудниках, включая зарплату с учетом комиссионных, полная зарплата которых больше 15 000, упорядочив их в порядке убывания значений полной зарплаты
SELECT employee_id, first_name, last_name, department_id,
salary* (1+NVL (commission_pct,0)) AS total_salary
FROM Employees
WHERE total_salary> 15000
ORDER BY total_salary DESC;
Правильный вариант решения задачи 3.45:
SELECT employee_id, first_name, last_name, department_id,
salary* (1+NVL (commission_pct,0)) AS total_salary
FROM Employees
WHERE salary* (1+NVL (commission_pct,0))> 15000
ORDER BY total_salary DESC;
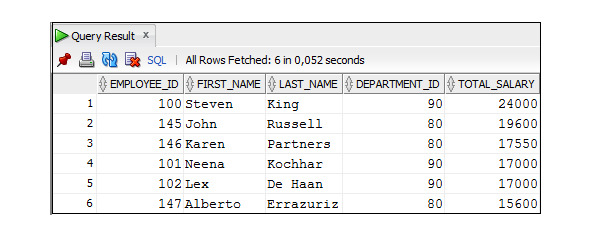
Функция NVL2
Расширяет возможности функции NVL. Синтаксис:
NVL2 (x,y1,y2)
Возвращает y1, если x не NUUL, и возвращает y2, если x имеет значение NUUL.
Например:
NVL2 (commission_pct, salary* (1+commission_pct), salary)
Пример 3.46. Вывести данные о сотрудниках, которые работают в отделах 30 и 80, размере премии, которую они должны получить. Размер премии, у сотрудников, которые получают комиссионные, равен зарплате с учетом комиссионных. Размер премии, у сотрудников, которые не получают комиссионные, равен зарплате, увеличенной на 30%
SELECT employee_id, first_name, last_name, department_id,
NVL2 (commission_pct, salary* (1+commission_pct), salary*1.3)
AS prize
FROM Employees
WHERE department_id IN (30,80)
ORDER BY prize DESC;
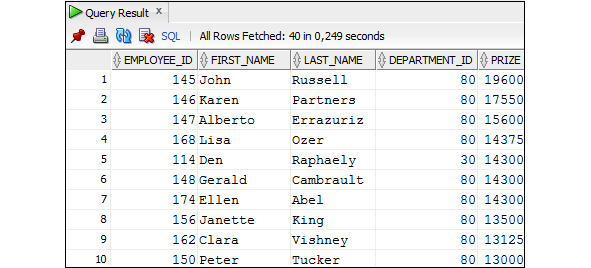
Функция COALESCE
Предназначена для обработки значений NULL и предоставляет более широкие возможности, чем функции NVL и NVL2. Позволяет отрабатывать несколько значений NULL. Синтаксис:
COALESCE (y1,y2,…yn)
Возвращает первое не NULL значение.
Для того чтобы продемонстрировать возможности этой функции, рассмотрим следующую задачу. Предположим, что таблица Employees имеет еще один столбец bonus. Значение этого столбца равно некоторой фиксированной сумме, которая должна быть прибавлена к зарплате сотрудника, может иметь значение NULL. С учетом столбца bonus зарплата сотрудников равна:
— bonus + salary * (1 + commission_pct) — если сотруднику положен бонус и он получает комиссионные;
— bonus + salary — если сотруднику положен бонус, но он не получает комиссионные;
— salary * (1 + commission_pct) — если сотруднику не положен бонус, но он получает комиссионные;
— salary — если сотруднику не положен бонус и он не получает комиссионные.
Используя функцию COALESCE, это правило начисления зарплаты можно реализовать следующим образом.
Пример 3.47. Вывести данные о сотрудниках и их полную зарплату, которая включает комиссионные и бонус
SELECT employee_id, first_name, last_name, department_id,
COALESCE (bonus + salary* (1+commission_pct),
bonus + salary, salary* (1+commission_pct), salary)
AS total_salary
FROM Employees
ORDER BY total_salary DESC;
Условные выражения
Довольно часто значение столбца, которое должен вернуть SQL-запрос, зависит от условий, которые нужно проверять для каждой строки. Для реализации подобного выбора используются выражение CASE и функция DECODE. Используя CASE и DECODE, можно реализовать условную логику if-then-else в операторе SELECT. Выражение CASE соответствует стандарту ANSI SQL, а функция DECODE специфична для Oracle.
Выражение CASE
Практически во всех современных языках программирования используется выражение CASE. Есть два варианта выражения CASE:
— выражение CASE с параметром;
— выражение CASE с условием.
Выражение CASE с параметром имеет следующий синтаксис:
CASE {параметр}
— WHEN {значение1} THEN {результат1}
— [WHEN {значение2} THEN {результат2}
— …
— WHEN {значениеN} THEN {результатN}]
— [ELSE {результат_ELSE}]
END;
Выражение CASE выполняется следующим образом: сравниваются значение {параметр} со значениями {значение i} в предложениях WHEN и возвращает результат {результатi} первого предложения, в котором будет выполнено условие {параметр} = {значениеi}.
Следует иметь в виду, что Oracle не оценивает остальные предложения WHEN. Если ни в одном из предложений WHEN не выполняется условие {параметр} = {значениеi}, то возвращается значение {результат_ELSE}. Если предложение ELSE отсутствует, то выражение CASE вернет результат NULL.
Возвращаемый результат может быть значением или выражением. Выражения {параметр} и {значение1} должны иметь один и тот же тип данных. Все возвращаемые значения {результат2} должны иметь одинаковый тип данных.
Примечание. Выражение CASE может содержать другие выражения CASE. Единственным ограничением является то, что одно выражение CASE может иметь максимум 255 условных выражений.
Пример 3.48. Вывести данные о сотрудниках и размере их премии, которая задана в виде фиксированной суммы, размер которой зависит от отдела, где работает сотрудник

Пример 3.49. Вывести данные о сотрудниках и размере их премии, которая задана как часть заработной платы, размер которой зависит от отдела, где работает сотрудник

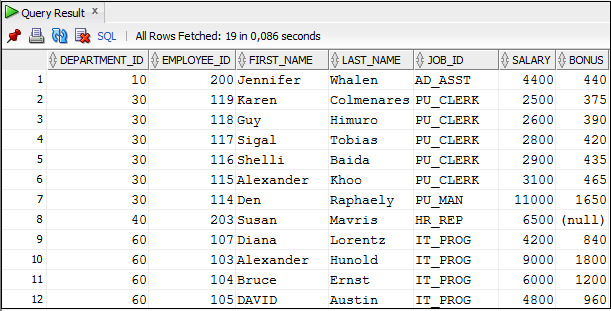
В этом примере отсутствует предложение ELSE, поэтому размер премии для сотрудников отделов, номеров которых нет в предложениях WHERE, имеет значение NULL.
Размер премии может зависеть как от отдела, в котором работает сотрудник, так и от его должности. Для решения этой задачи необходимо использовать вложенные выражения CASE.
Пример 3.50. Вывести данные о сотрудниках и размере их премии, которая зависит как от отдела, где работает сотрудник, так и от его должности.

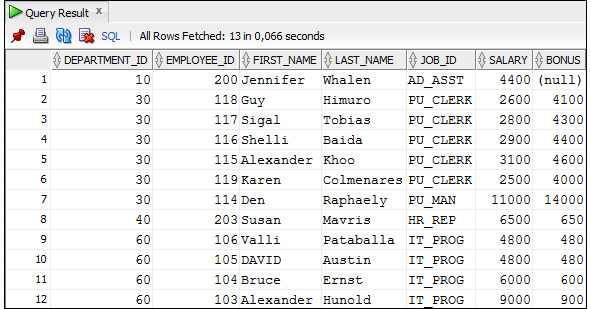
Выражение CASE с условием имеет следующий синтаксис:
CASE
WHEN {условие1} THEN {результат1}
[WHEN {условие2} THEN {результат2}
…
WHEN {условиеN} THEN {результатN}]
[ELSE {результат_ELSE}]
END
При использовании этой разновидности оператора CASE последовательно поверяются значения условных выражений в предложениях WHEN и возвращается результат из первого предложения, в котором это выражение будет иметь значение TRUE.
Пример 3.51. Вывести данные о сотрудниках и размере их премии, которая зависит от зарплаты сотрудника

Пример 3.52. Вывести данные о сотрудниках и размере их премии, которая зависит от количества лет, которые проработал сотрудник

Функция DECODE
По своему назначению функция DECODE аналогична условному выражению CASE, но не поддерживается стандартом ANSI/ISO SQL. Синтаксис:
DECODE ({столбец} | {выражение}
{, {значение 1}, {результат 1}
[, {значение 2}, {результат2}
…
[, {значение N}, {результат N}]
[, {результат default}]);
Значение {столбец} | {выражение} сравнивается со значениями {значение i} и возвращается результат первого совпадения.
Если совпадения не будет, то возвращается значение {результат default}. Если {результат default} отсутствует, то функция DECODE вернет результат NULL.
Следует обратить внимание на то, что функция DECODE требует точного совпадения значений и не позволяет использовать операции сравнения>, <и сложные условия. Поэтому возможности функции DECODE уступают возможностям условного выражения CASE.
Пример 3.53. Вывести данные о сотрудниках и размер их премии, которая задана в виде фиксированной суммы, размер которой зависит от отдела, в котором работает сотрудник
SELECT department_id, employee_id, first_name, last_name,
job_id, salary,
DECODE (department_id, 10, 1000,30, 1200,60, 1500,500)
AS bonus
FROM Employees
WHERE department_id in (10,30,40,60,100)
ORDER BY department_id;
Результат выполнения этого запроса совпадает с результатом выполнения запроса из примера 3.50.
Рассмотрим еще один пример использования функции DECODE для решения задачи из примера 3.53. Особенностью этой задачи является использование операции сравнения>, которую нельзя использовать в DECODE. Но при решении этой задачи данное ограничение удается обойти. Обратите внимание на то, что число месяцев, которые проработал сотрудник, делится на 60, что соответствует пяти годам работы. Если целая часть результата равна пяти, то это означает что сотрудник проработал не менее 25, но не более 30. Последнее замечание означает, что запросы из примеров 3.53 и 3.55 не эквивалентны и запрос с использованием функции DECODE требует расширения списка значений.
Пример 3.54. Вывести данные о сотрудниках и размере их премии, которая зависит от количества лет, которые проработал сотрудник, используя функцию DECODE
SELECT department_id, employee_id, first_name, last_name, job_id,
hire_date, salary,
DECODE (TRUNC (MONTHS_BETWEEN (SYSDATE, hire_date) /60),
6,3*salary,
5,3*salary,
4, 2*salary,
3, salary,
0.5*salary) As bonus
FROM Employees
WHERE department_id IN (10,30,40,60)
ORDER BY department_id;
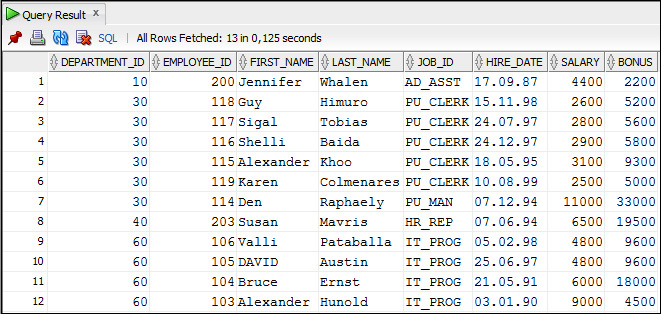
Задачи для самостоятельного решения
1. Вывести значения столбцов employee_id, first_name, last_name и значение зарплаты, увеличенное на 25%. Увеличенное значение зарплаты округлить до сотен.
2. Вывести значения столбцов employee_id, first_name, last_name, salary и ту часть зарплаты сотрудника, которая меньше 1000.
3. Создать запрос, который вернет столбец name_and_salaries. Столбец должен содержать полное имя сотрудника, зарплату и несколько звездочек (*) — по одной звездочке на каждые $1000 зарплаты.
4. Вывести данные о товарах, название которых содержит слово AMD и не содержит слова RYZEN.
5. Вывести названия товаров, второе слово которых состоит из шести букв.
6. Вывести данные о товарах, второе слово в названии которых — – iPhone.
7. Вывести данные о сотрудниках, которые были приняты на работу в понедельник.
8. Вывести данные о сотрудниках, которые были приняты на работу 21 апреля.
9. Для сотрудников, работающих в отделе 50, вывести разницу между текущей датой и датой приема на работу в формате: УУ лет ММ месяцев ДД дней.
10. Вывести значения столбцов employee_id, first_name, last_name, salary и премию, которую они должны получить. Размер премии у сотрудников, которые получают комиссионные, равен зарплате с учетом комиссионных. Размер премии у сотрудников, которые не получают комиссионные, равен зарплате, увеличенной на 30%.
11. Вывести значения столбцов employee_id, first_name, last_name, salary и bonus — премию, которую они должны получить. Размер премии зависит от рейтинга и вычисляется по следующему правилу:
— если рейтинг сотрудника равен 5, то bonus = salary * 1.5;
— если рейтинг сотрудника равен 4, то bonus = salary * 1.3;
— если рейтинг сотрудника равен 3, то bonus = salary * 1.1;
— сотрудникам, рейтинг которых меньше 3, премия не полагается.
12. Вывести значения столбцов employee_id, first_name, last_name, salary и category. Значение категории (category) определяется по следующему правилу:
— если rating_e ≥ 4 и salary ≥ 10 000, то category = ′High′;
— если rating_e <3 и salary <5000, то category = ′Low′;
— у остальных сотрудников category = ′Middle′.
Глава 4. Агрегатные функции и группировка данных
Агрегатные функции
В отличие от однострочных функций, агрегатные функции обрабатывают группу строк и возвращают один результат для группы. Группа строк может включать как всю таблицу, так и ее часть.
Таблица 4.1. Агрегатные функции
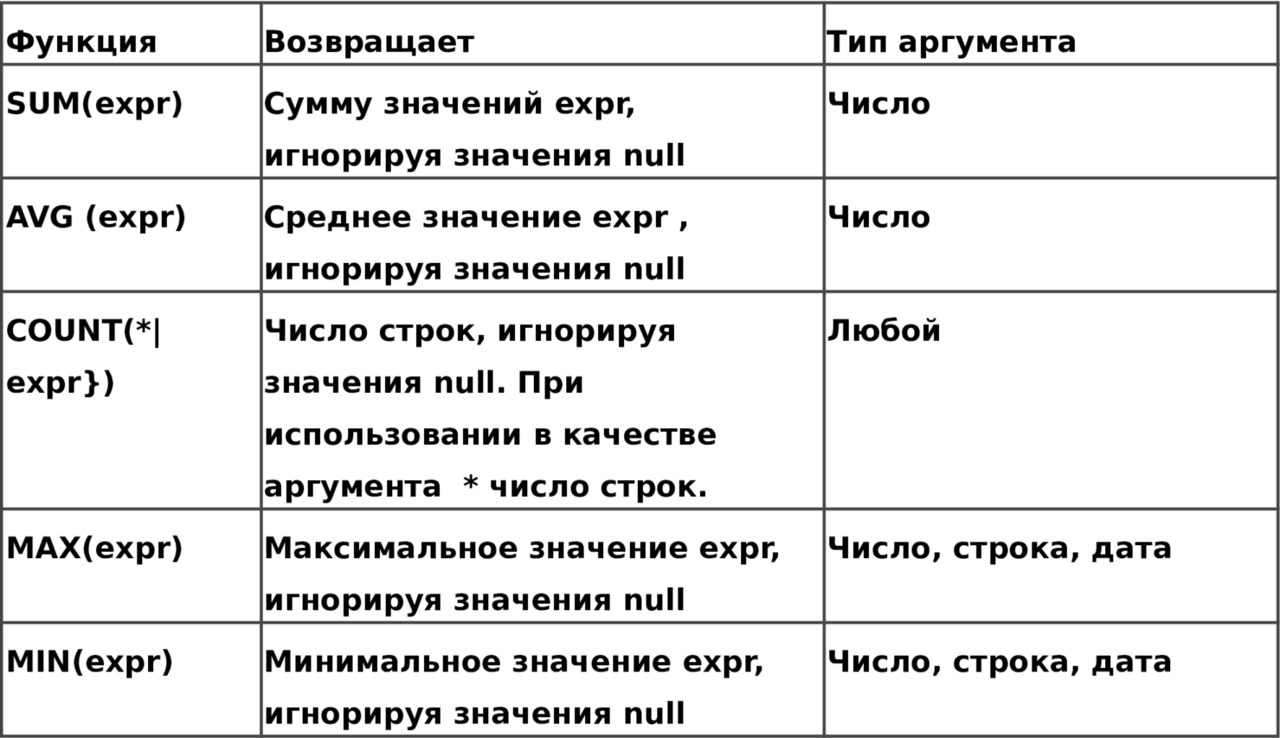
Синтаксис агрегатных функций:
{имя функции} ({Аргумент})
где: expr — аргумент агрегатной функции, который может содержать следующие элементы:
[DISTINCT] {имя столбца} | {выражение} | {однострочная функция}
Следует обратить внимание на то, что аргументом групповой функции может быть однострочная функция. Хотя стандарт языка SQL запрещает использование агрегатных функций в качестве аргумента агрегатных функций, СУБД Oracle допускает это, но только на один уровень в глубину и только в предложении SELECT. Рассмотрим примеры использования агрегатных функций.
Пример 4.1. Вывод обобщенных данных о зарплате сотрудников
SELECT MIN (salary) AS minimum, MAX (salary) AS maximum, ROUND (AVG (salary)) AS medium, SUM (salary) As summa, COUNT (salary), COUNT (*)
FROM Employees;
В полученном результате следует обратить внимание на то, что:
— COUNT (salary) возвращает число сотрудников, получающих зарплату, у которых значение столбца salary не NULL;
— COUNT (*) возвращает число всех сотрудников.
Этот запрос не учитывает то, что некоторые сотрудники получают комиссионные. Зарплата сотрудника с учетом комиссионных может быть вычислена путем использования выражения:
salary * (1 + NVL (commission_pct,0))
Используя это выражение в предыдущем запросе, вместо столбца salary получим:
Пример 4.2. Вывод обобщенных данных о зарплате сотрудников с учетом комиссионных
SELECT MIN (salary* (1+NVL (commission_pct,0))) AS minimum,
MAX (salary* (1+NVL (commission_pct,0))) AS maximum,
ROUND (AVG (salary* (1+NVL (commission_pct,0)))) AS medium,
SUM (salary* (1+NVL (commission_pct,0))) As summa,
COUNT (salary* (1+NVL (commission_pct,0))) AS ′′COUNT (expr) ′′,
COUNT (*)
FROM Employees;
Пример 4.3. Использование функции COUNT
SELECT COUNT (*), COUNT (salary),COUNT (DISTINCT salary),
COUNT (commission_pct)
FROM Employees
WHERE department_id =80;
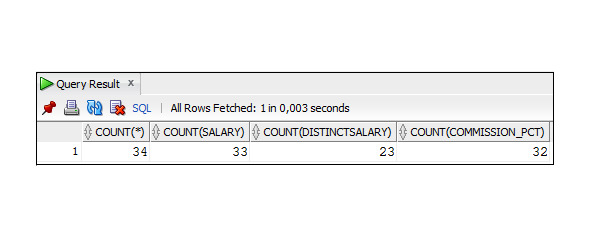
Анализ результатов этого запроса:
— COUNT (*) — вернула число сотрудников в отделе 80;
— COUNT (salary) — вернула число сотрудников в отделе 80,
у которых значение столбца salary не NULL;
— COUNT (DISTINCT salary) — вернула число различных значений в столбце salary;
— COUNT (commission_pct) — вернула число сотрудников в отделе 80, у которых значение столбца commission_pct не NULL.
Оператор DISTINCT используется для исключения повторяющихся значений. Например, необходимо определить количество должностей. Запрос без оператора DISTINCT вернет количество сотрудников, у которых значение столбца job_id не NULL.
Пример 4.4. Количество сотрудников, у которых значение столбца job_id не NULL
SELECT COUNT (job_id)
FROM Employees;
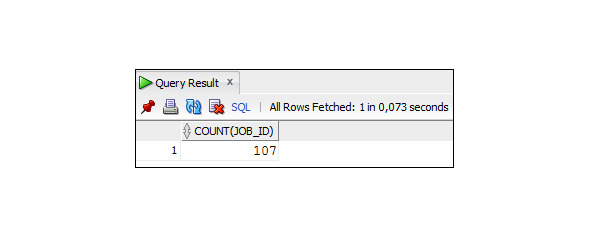
Если в аргумент функции COUNT добавить оператор DISTINCT, то будут исключены повторяющиеся значения столбца job_id и запрос вернет количество должностей (количество уникальных значений столбца job_id).
Пример 4.5. Количество уникальных значений столбца job_id
SELECT COUNT (DISTINCT job_id)
FROM Employees;
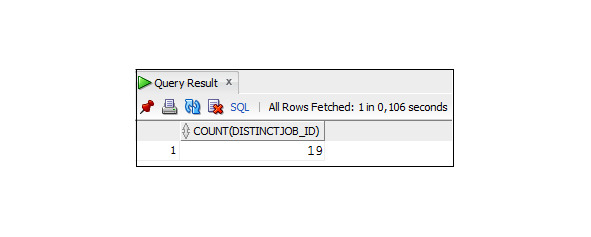
Задача: требуется определить средний размер комиссионных. Рассмотрим два варианта решения этой задачи.
Вариант 1
SELECT AVG (commission_pct)
FROM Employees;
Вариант 2.
SELECT AVG (NVL (commission_pct, 0))
FROM Employees;
Здесь правильный вариант решения не очевиден. У значительной части сотрудников значение столбца commission_pct имеет значение NULL. Если этим сотрудникам комиссионные не положены и они не должны учитываться, то правильным будет первый вариант. Если значение NULL следует считать равным нулю, то следует использовать второй вариант запроса.
Агрегатные функции нельзя использовать в предложении WHERE. Например, нельзя найти сотрудника с максимальной зарплатой, используя следующий запрос:
Пример 4.6a. Найти сотрудника, получающего максимальную зарплату
Внимание: ЭТОТ ЗАПРОС НЕ БУДЕТ ВЫПОЛНЕН!
SELECT employee_id, salary
FROM Employees
WHERE salary = MAX (salary);
Данную задачу можно решить следующим образом:
Пример 4.6б. Найти сотрудника, получающего максимальную зарплату
SELECT employee_id, salary AS maximum
FROM Employees
WHERE salary = (SELECT MAX (salary) FROM Employees);
Данный запрос содержит в предложении WHERE подзапрос. Использование подзапросов будет рассмотрено позже.
Группировка
Чаще всего агрегатные функции используются в запросах с группировкой. В общем виде запрос с группировкой может быть представлен в следующем виде:
SELECT {список столбцов*), {агрегатные функции}
FROM {таблица}
WHERE {условия}
GROUP BY {список столбцов*}
HAVING {условия на группу};
Списки столбцов в предложениях SELECT и GROUP BY должны совпадать.
Предложение GROUP BY разбивает данные на группы, и запрос выводит обобщенные данные о каждой группе.
Рассмотрим примеры задач, для решения которых необходимо использовать группировку и агрегатные функции.
Пример 4.7. Для каждого отдела определить суммарную зарплату
SELECT department_id, SUM (salary) AS SUM_salary
FROM Employees
GROUP BY department_id
ORDER BY department_id;
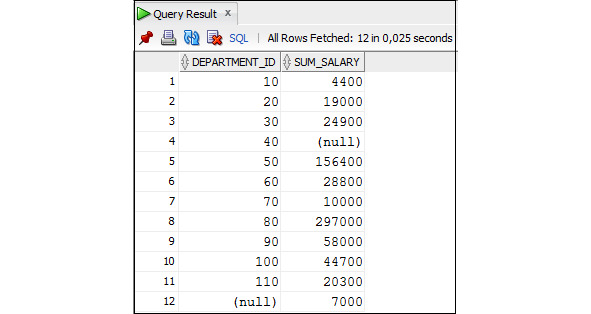
Пример 4.8. Для каждого отдела определить суммарную зарплату с учетом комиссионных
SELECT department_id, SUM (salary* (1+NVL (commission_pct,0)))
As sum_sal
FROM Employees
GROUP BY department_id
ORDER BY department_id;
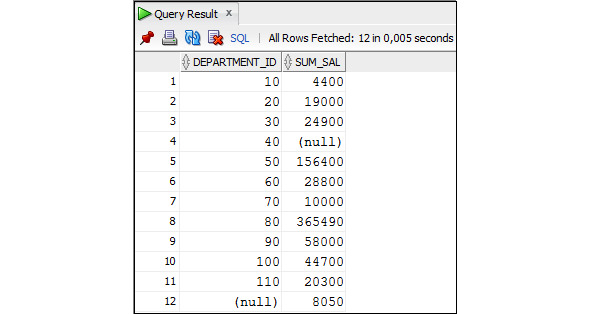
Пример 4.9. Для каждого отдела определить суммарную длину имен (столбца first_name)
SELECT department_id, SUM (LENGTH (first_name)) As sum_f_nam
FROM Employees
GROUP BY department_id
ORDER BY department_id;
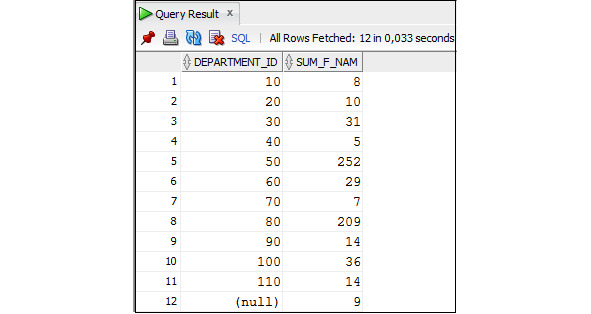
Группировка по нескольким столбцам
В предложении GROUP BY можно указать несколько столбцов. В этом случае группу образуют строки с совпадающими значениями всех столбцов, по которым осуществляется группировка. Рассмотрим задачи, в которых требуется группировка по нескольким столбцам.
Сначала рассмотрим запрос, который содержит типичную ошибку при решении задач, требующих группировки по нескольким столбцам.
Пример 4.10а. Для каждого отдела определить должности и количество сотрудников, занимающих эту должность (содержит ошибку)
SELECT department_id, job_id, count (*)
FROM employees
GROUP BY department_id;
Причина ошибки: при наличии группировки предложение SELECT может содержать только столбцы, по которым осуществляется группировка и агрегатные функции.
Пример 4.10б. Для отделов 30 и 50 определить должности и количество сотрудников, занимающих каждую должность
SELECT department_id, job_id, count (*)
FROM Employees
WHERE department_id IN (30,50)
GROUP BY department_id, job_id
ORDER BY department_id;
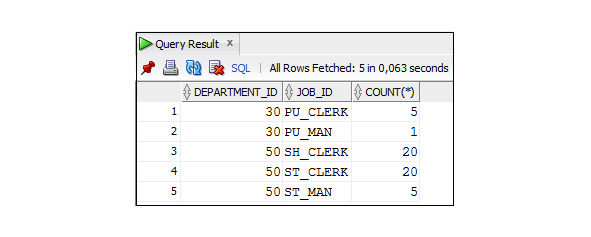
Пример 4.11. Для отделов, номер которых меньше 50, вывести рейтинги, которые имеют сотрудники этого отдела, их количество и суммарную зарплату
SELECT department_id, rating_e, count (*),sum (salary)
FROM Employees
WHERE department_id <= 50
GROUP BY department_id, rating_e
ORDER BY department_id;
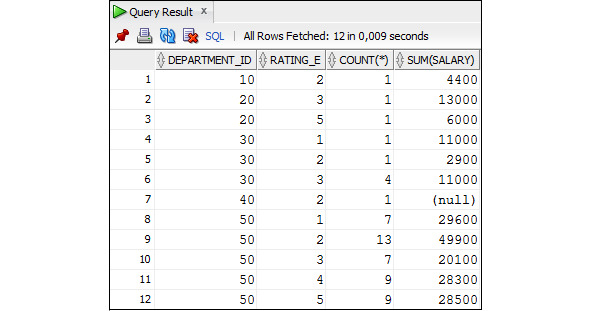
Использование условий на группу
Условия на группу указываются в предложении HAVING.
Пример 4.12. Вывести суммарную зарплату для тех отделов, у которых суммарная зарплата превышает 50 000
SELECT department_id, SUM (salary)
FROM Employees
GROUP BY department_id
HAVING SUM (salary)> 50000;
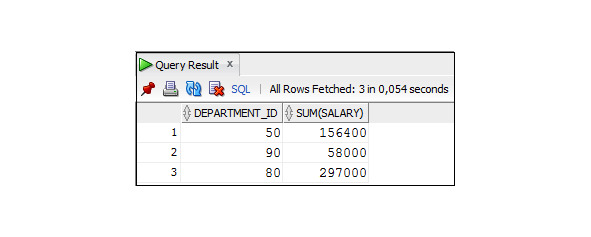
Условие выборки может быть проверено до группировки. В этом случае сначала выбираются строки, удовлетворяющие условию, а потом осуществляется группировка полученных данных. Для полученных групп можно указать условие в предложении HAVING. В результат запроса попадут только те группы, которые удовлетворяют этому условию.
Пример 4.13. Вывести должности и количество сотрудников, которые получают зарплату более 10 000
SELECT department_id, SUM (salary)
FROM Employees
GROUP BY department_id
HAVING SUM (salary)> 50000;
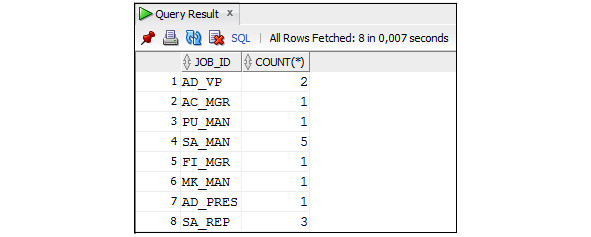
К условиям предыдущей задачи можно добавить условие: вывести только те должности, которые занимают более одного сотрудника.
Пример 4.14. Вывести должности и количество сотрудников, которые получают зарплату более 10 000, которые занимают более одного сотрудника, упорядочив их в порядке убывания количества сотрудников
SELECT job_id, COUNT (*) As num_job
FROM Employees
WHERE salary> 10000
GROUP BY job_id
HAVING COUNT (*)> 1
ORDER BY num_job DESC;
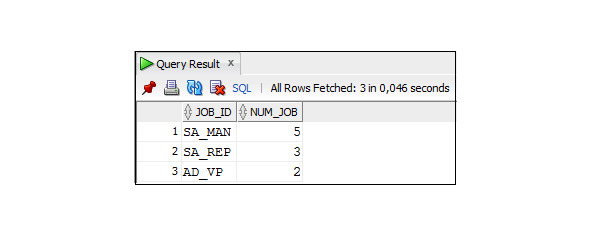
Пример 4.15. Вывести номера отделов, у которых число сотрудников, имеющих рейтинг 5, больше одного, количество сотрудников, имеющих рейтинг 5, и их суммарную зарплату
SELECT department_id, rating_e, count (*),sum (salary)
FROM Employees
WHERE rating_e = 5
GROUP BY department_id, rating_e
HAVING count (*)> 1
ORDER BY department_id;
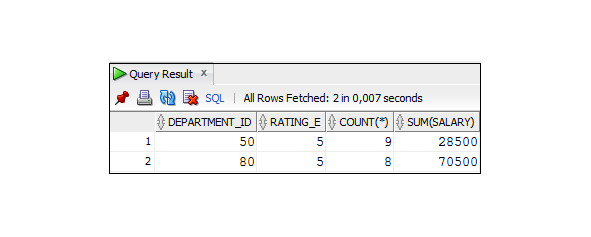
Использование вложенных агрегатных функций
Хотя Oracle и допускает использование вложенных агрегатных функций, но только на один уровень и только в предложении SELECT. При этом предложение SELECT не должно содержать других элементов.
Пример 4.16. Определить количество сотрудников в каждом отделе
SELECT department_id, count (*)
FROM Employees
GROUP BY department_id
ORDER BY department_id;
Используя вложенные агрегатные функции, можно найти максимальное число сотрудников, работающих в одном отделе.
Пример 4.17. Найти максимальное число сотрудников работающих в одном отделе
SELECT Max (COUNT (*))
FROM Employees
GROUP BY department_id;
Но вложенные агрегатные функции нельзя использовать в предложениях WHERE и HAVING, поэтому для того, чтобы найти отдел, в котором работает максимальное число сотрудников, понадобится использование подзапроса.
Пример 4.18. Найти отдел, в котором работает максимальное число сотрудников.
SELECT department_id, COUNT (*)
FROM Employees
GROUP BY department_id
HAVING COUNT (*) =
(SELECT MAX (COUNT (*))
FROM Employees
GROUP BY department_id);
Использование специальных операторов группировки
Рассмотрим специальные операторы группировки и функции, которые позволяют существенно расширить возможности запросов с группировкой данных.
Оператор GROUP BY ROLLUP
Расширяет возможности GROUP BY, возвращая для каждой группы строку, содержащую итоги по группе, а также строку, содержащую общий итог для всех групп, и имеет следующий вид:
GROUP BY ROLLUP {список столбцов}
Для демонстрации возможностей, которые предоставляет оператор GROUP BY ROLLUP, рассмотрим следующую задачу: для каждого отдела определить должности и количество сотрудников, занимающих эту должность. Решение этой задачи без использования ROLLUP содержится в примере 4.10.
Пример 4.19. Для отделов 30 и 50 определить должности и количество сотрудников, занимающих эту должность
SELECT department_id, job_id, count (*)
FROM Employees
WHERE department_id IN (30,50)
GROUP BY ROLLUP (department_id, job_id)
ORDER BY department_id;
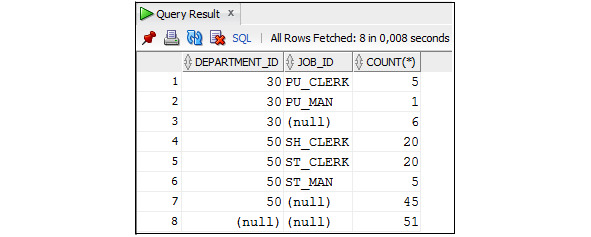
По сравнению с результатами, которые выводит запрос из примера 4.10, этот запрос выводит данные о количестве сотрудников в каждом отделе и общем количестве сотрудников, работающих в рассматриваемых отделах.
В условия группировки можно добавить столбец rating_e.
Пример 4.20. Для отделов 30 и 50 определить должности, рейтинг и количество сотрудников, занимающих каждую должность и имеющих определенный рейтинг
SELECT department_id, job_id, rating_e, count (*)
FROM Employees
WHERE department_id IN (30,50)
GROUP BY ROLLUP (department_id, job_id, rating_e)
ORDER BY department_id;
Оператор GROUP BY CUBE
Возвращает предварительные итоги для всех комбинаций столбцов и строку с общим итогом и имеет следующий вид:
GROUP BY CUBE {список столбцов}
Рассмотрим решение предыдущих задач с использованием этого оператора.
Пример 4.21. Для отделов 30 и 50 определить должности и количество сотрудников, занимающих каждую должность
SELECT department_id, job_id, count (*)
FROM Employees
WHERE department_id IN (30,50)
GROUP BY CUBE (department_id, job_id)
ORDER BY department_id;
Сравнивая эти результаты с результатами из примера 4.19, можно увидеть, что результат последнего запроса содержит данные о количестве сотрудников, занимающих определенную должность, без учета отдела, в котором они работают.
В примере 4.22 приведен вариант решения задачи из примера 4.20 с использованием оператора GROUP BY CUBE.
Пример 4.22. Для отделов 30 и 50 определить должности, рейтинг и количество сотрудников, занимающих каждую должность и рейтинг и имеющих рейтинг> 3
SELECT department_id, job_id, rating_e, count (*)
FROM Employees
WHERE department_id IN (30,50) AND rating_e> 3
GROUP BY CUBE (department_id, job_id, rating_e)
ORDER BY department_id;
Оператор GROUP BY CUBE выводит очень много строк, поэтому в ряде случаев удобнее использовать оператор GROUP BY GROUPING SETS.
Оператор GROUP BY GROUPING SETS
Используется вместо оператора GROUP BY CUBE в тех случаях, когда нужно вывести только строки с промежуточными итогами. При использовании GROUP BY CUBE такие строки содержат NULL в одном или нескольких столбцах.
Пример 4.23. Для отделов 30 и 50 определить количество сотрудников в отделе и количество сотрудников, занимающих каждую должность
SELECT department_id, job_id, count (*)
FROM Employees
WHERE department_id IN (30,50)
GROUP BY GROUPING SETS (department_id, job_id)
ORDER BY department_id;
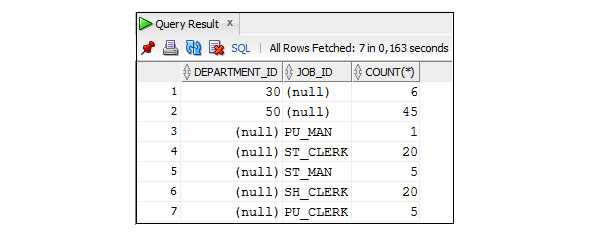
Результат этого запроса содержит данные только о количестве сотрудников, работающих в каждом отделе, и данные о количестве сотрудников, занимающих определенную должность, без учета отдела, в котором они работают. Добавим в предложение GROUP BY GROUPING SETS столбец rating_e.
Пример 4.24. Для отделов 30 и 50 определить количество сотрудников в отделе, количество сотрудников, занимающих каждую должность, и количество сотрудников, имеющих определенный рейтинг
SELECT department_id, job_id, count (*)
FROM Employees
WHERE department_id IN (30,50)
GROUP BY GROUPING SETS (department_id, job_id, rating_e)
ORDER BY department_id;
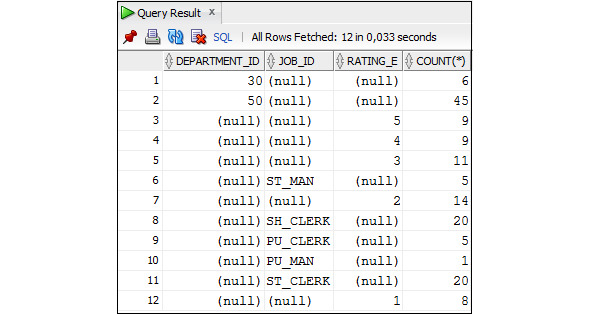
Несколько столбцов в этом операторе можно заключить в скобки, в этом случае они будут рассматриваться как один столбец, по которому нужно вывести промежуточные итоги.
Пример 4.25. Для отделов 30 и 50 определить количество сотрудников в отделе и количество сотрудников, занимающих каждую должность и имеющих определенный рейтинг
SELECT department_id, job_id, count (*)
FROM Employees
WHERE department_id IN (30,50)
GROUP BY GROUPING SETS (department_id, (job_id, rating_e))
ORDER BY department_id;
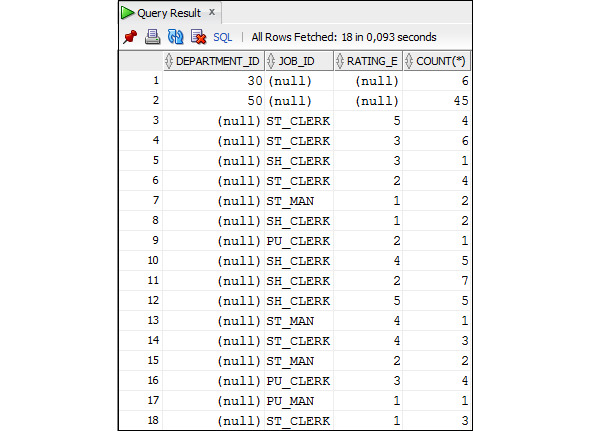
Из рассмотренных примеров видно, что специальные операторы группировки предоставляют значительно больше данных. Для облегчения анализа этих данных можно использовать специальные функции.
Функция GROUPING ()
Принимает значение столбца и возвращает значение 1, если значение столбца равно NULL, и 0 в противном случае. Может использоваться только в запросах с RULUP и CUBE.
Рассмотрим использование этой функции в запросе из примера 4.21.
Пример 4.26. Для отделов 30 и 50 определить должности и количество сотрудников, занимающих каждую должность
SELECT department_id, GROUPING (department_id) AS ALL_DEP,
job_id, GROUPING (job_id) AS ALL_JOB, count (*)
FROM Employees
WHERE department_id IN (30,50)
GROUP BY CUBE (department_id, job_id)
ORDER BY department_id;
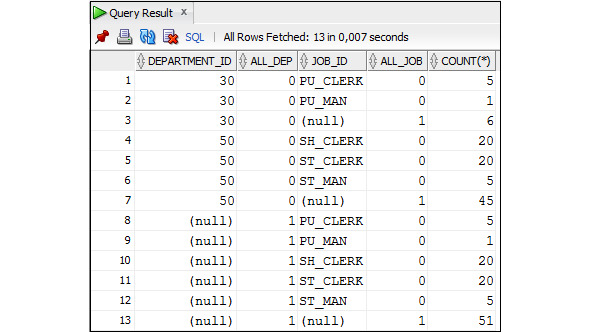
Использование этой функции совместно с оператором DECODE позволяет существенно повысить наглядность выводимых данных в запросах с группировкой.
Пример 4.27. Для отделов 30 и 50 определить должности и количество сотрудников, занимающих каждую должность, с использованием функции DECODE
SELECT
DECODE (GROUPING (department_id), 1, ′′ * ALL JOB * ′′,
0,department_id) AS DEPT,
DECODE (GROUPING (job_id), 1, ′′ *ALL DEP * ′′, 0,job_id)
AS JOBS, COUNT (*)
FROM Employees
WHERE department_id IN (30,50)
GROUP BY CUBE (department_id, job_id)
ORDER BY department_id;
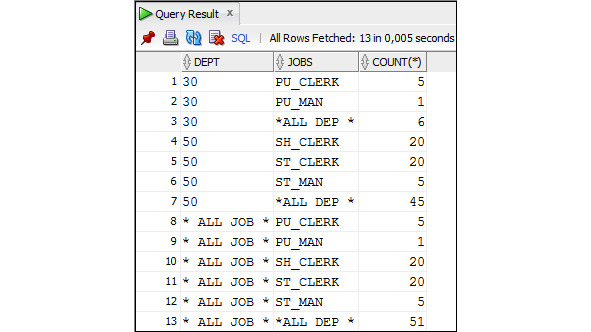
Задачи для самостоятельного решения
1. Вывести коды руководителей (manager_id), количество и суммарную зарплату сотрудников, находящихся у них в непосредственном подчинении.
2. Для каждого отдела определить количество сотрудников, имена которых начинаются на букву А.
3. Найти количество товаров, в названии которых есть слово CORE.
4. Вывести номера отделов и суммарную зарплату сотрудников в отделе с учетом комиссионных. Упорядочить данные в порядке убывания суммарной заработной платы.
5. Для каждой должности определить разницу между максимальной и минимальной зарплатой.
6. Определить должность, для которой разница между максимальной и минимальной зарплатой минимальна.
7. Определить должности, средняя зарплата по которым больше, чем средняя зарплата по должности IT_PROG. Нужно учитывать только те должности, которые занимает более одного сотрудника.
8. Определить номера товаров, по которым было совершено меньше пяти продаж.
9. Найти заказ с максимальным количеством товаров. Нужно учитывать все товары в заказе.
10. Найти сотрудника, который оформил наибольшее количество заказов.
11. Вывести значение location_id населенного пункта, в котором располагается наибольшее число отделов.
Глава 5. Многотабличные запросы
Реляционная база данных представляет собой совокупность взаимосвязанных таблиц. При решении большинства задач по обработке данных требуется извлекать информацию из нескольких таблиц. Запросы, в которых используется несколько таблиц, называют многотабличными.
В многотабличных запросах нужно обязательно указывать условия соединения таблиц. При отсутствии условий соединения ошибки не возникает, а происходит декартово произведение таблиц: каждая строка одной таблицы соединяется с каждой строкой второй таблицы.
Столбцы, по которым осуществляется соединение, должны иметь одинаковый тип и совпадающие или сравнимые значения. Чаще всего в соединениях используется ключ одной таблицы и столбец другой таблицы, который является внешним ключом.
Обычно в качестве операции соединения используется =, но можно использовать и другие операции, например>, <.
Полное имя столбца состоит из имени таблицы и имени столбца, между которыми стоит точка: например, Employees. employee_id. Если столбцы в многотабличных запросах имеют одинаковые имена, то необходимо использовать полные имена.
Условия соединения могут быть заданы или в предложении WHERE или в предложении FROM.
Условия соединения в предложении WHERE
Условия соединения в предложении WHERE в общем виде могут быть записаны следующим образом:
SELECT {список столбцов}
FROM Таблица1, Таблица2, [Таблица3]…
WHERE Таблица1.столбец {оператор объединения}
[AND Таблица2.столбец {оператор объединения}
Таблица3.столбец]
Например, нужно вывести номера и названия отделов, расположенных в определенном городе. Для решения данной задачи необходимы данные, содержащиеся в таблицах Departments и Locations.
Пример 5.1. Вывести номера и названия отделов, расположенных в городе London (запрос содержит ошибку — отсутствует условие соединения)
SELECT department_id, department_name
FROM Departments, Locations
WHERE city = ′London′;
В этом запросе отсутствует условие соединения таблиц, поэтому будет выполнено декартово произведение таблиц. Каждая строка таблицы Departments соединится с каждой строкой таблицы Locations. Формально это означает, что каждый отдел расположен во всех городах, поэтому при выполнении этого запроса будет выведен список всех отделов, и этот список не будет меняться при изменении названия города. Правильный запрос должен содержать условие соединения. Соединение этих таблиц осуществляется через столбец location_id.
Следует иметь в виду, что при создании базы данных между этими таблицами была определена связь. Связь на уровне определения таблиц представляет собой правило, которому должны удовлетворять данные, содержащиеся в этих таблицах. Например, при вводе данных о подразделении нельзя ввести location_id, которого нет в таблице Locations. Но при выполнении запроса на выборку эта связь не учитывается и должна быть описана в запросе.
Пример 5.2. Вывести номера и названия отделов, расположенных в городе London
SELECT department_id, department_name, l. location_id
FROM Departments d, Locations l
WHERE d. location_id=l. location_id
AND city = ′London′;
В данном примере, кроме добавления условия соединения, использованы псевдонимы таблиц. Позже мы более подробно рассмотрим использование псевдонимов в запросах.
Если в многотабличном запросе участвует N таблиц, то число условий соединения должно быть N — 1.
Пример 5.3. Вывести данные о товарах, которые приобретал покупатель 45
SELECT ord. order_id, ord. order_date, oi.item_id,
pr.product_name, oi. quantity, oi. unit_price
FROM Orders ord, Order_Items oi, Products pr
WHERE ord. order_id = oi. order_id
AND oi.product_id = pr.product_id
AND ord.customer_id = 45
ORDER BY ord. order_id;
В запросе из примера 5.3 участвуют три таблицы, поэтому предложение WHERE содержит два условия соединения и условие выбора.
Строки, которые возвращает многотабличный запрос, могут быть сгруппированы по одному или нескольким столбцам.
Пример 5.4. Для каждого города вывести число отделов, расположенных в этом городе
SELECT d. location_id, l.city, COUNT (*) As sm
FROM Departments d, Locations l
WHERE d. location_id=l. location_id
GROUP BY d.location_id,l.city;
Существует несколько типов соединений между таблицами. Перечислим основные:
— соединения по эквивалентности
(в рассмотренных примерах был использован именно этот тип соединения);
— соединения по неэквивалентности;
— внутренние соединения;
— внешние соединения;
— самосоединения.
Соединения по неэквивалентности
В соединениях по неэквивалентности вместо оператора = используются другие операторы:>, <, BETWEEN и др.
Данный тип соединения можно определять для таблиц, между которыми нет связи на уровне определения данных. В качестве примера использования такого типа соединения рассмотрим следующую задачу. Для каждого сотрудника, работающего в отделе 80, определить номера и названия товаров, которые он имеет право продавать. Это право определяется следующим правилом: рейтинг сотрудника должен быть больше или равен рейтингу товара.
Пример 5.5. Для каждого сотрудника, работающего в отделе 80, вывести номера и названия товаров, которые он имеет право продавать
SELECT employee_id, product_id, product_name, rating_e, rating_p
FROM Products, Employees
WHERE department_id = 80 AND rating_e> = rating_p
ORDER BY employee_id;
Пример 5.6. Вывести номера сотрудников и номера товаров, которые удовлетворяют условию: зарплата сотрудника должна быть в 200 раз больше продажной цены товара
SELECT DISTINCT employee_id, product_id
FROM Order_Items oi, Employees e
WHERE e.salary> 200*oi. unit_price
ORDER BY employee_id;
Условия соединения в предложении FROM
Для соединения таблиц в предложении FROM используется оператор JOIN, который имеет следующий синтаксис:
{таблица 1} {тип соединения} JOIN {таблица 2}
{условие соединения}
Таблицу, расположенную слева от оператора JOIN ({таблица 1}), будем называть левой таблицей, а таблицу, расположенную справа от оператора JOIN ({таблица 2}), будем называть правой таблицей.
Можно создавать два типа соединений: внутренние и внешние.
Внутренние соединения
При использовании внутреннего соединения запрос будет выводить только те строки левой таблицы, которые имеют связанные строки в правой таблице. Условия соединения, указанные в предложении WHERE, создают внутренние соединения.
Есть несколько вариантов определения внутреннего соединения в предложении JOIN.
NATURAL JOIN (естественное соединение)
Синтаксис:
SELECT {список столбцов}
FROM {таблица 1} NATURAL JOIN {таблица 2}
Этот оператор соединения соответствует операции соединения реляционной алгебры. При использовании этого оператора необходимо, чтобы соединяемые таблицы имели один или несколько одноименных столбцов. Строки левой таблицы соединяются с теми строками правой таблицы, которые имеют совпадающие значения всех одноименных столбцов.
Пример 5.7. Вывести названия населенных пунктов, номера и название отделов, которые в них расположены
SELECT location_id, city, department_id, department_name
FROM Locations NATURAL JOIN Departments;
Другой способ определения внутреннего соединения реализует оператор INNER JOIN, который имеет следующий синтаксис:
{таблица 1} [INNER] JOIN {таблица 2}
{условие соединения}
Этот оператор является более общим способом реализации внутреннего соединения и требует указания условий соединения. Служебное слово INNER можно не указывать.
Для определения условий соединения можно использовать следующие конструкции:
— USING (имя столбца);
— ON ({таблица 1.имя столбца} {оператор соединения}
{таблица 2.имя столбца}
При использовании USING таблицы должны иметь одноименный столбец, по которому будет осуществляться соединение. Оператор USING позволяет осуществлять соединение по нескольким столбцам, в этом случае в качестве параметра задается список столбцов. Строки левой таблицы соединяются с теми строками правой таблицы, которые имеют совпадающие значения всех столбцов из этого списка.
Пример 5.8. Вывести названия населенных пунктов, номера и названия отделов, которые в них расположены
SELECT location_id, city, department_id, department_name
FROM Locations JOIN Departments USING (location_id);
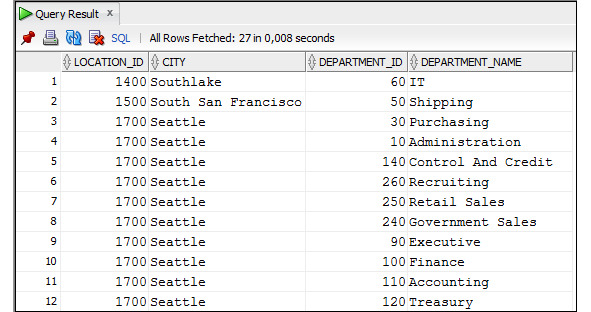
Оператор ON предоставляет намного больше возможностей. Он позволяет:
— осуществлять соединение по столбцам, имеющим разные имена в левой и правой таблице;
— использовать в условии соединения несколько столбцов;
— позволяет осуществлять соединение по неэквивалентности.
Пример 5.9. Вывести данные о заказах, которые оформил сотрудник 165
SELECT employee_id, first_name, last_name, job_id, order_id,
customer_id, order_date
FROM Employees JOIN Orders ON (employee_id=salesman_id)
WHERE employee_id =165;
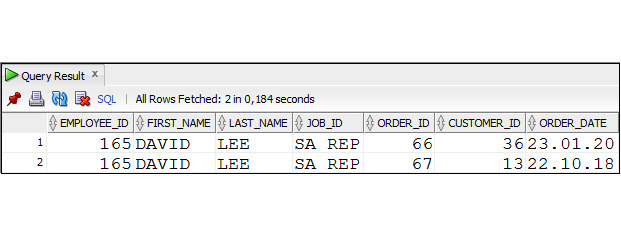
В примере 5.10 приведено решение задачи из примера 5.5, которая требует соединения по неэквивалентности, с использованием конструкции JOIN ON.
Пример 5.10. Для каждого сотрудника, работающего в отделе 80, вывести номера и названия товаров, которые он имеет право продавать
SELECT employee_id, product_id, product_name, rating_e, rating_p
FROM Products JOIN Employees ON (rating_e> = rating_p)
WHERE department_id = 80
ORDER BY employee_id;
Строки, полученные в результате выполнения запроса, можно группировать по значениям вы
Пример 5.11. Вывести общую сумму продаж за каждый месяц 2019 года
SELECT TO_CHAR (order_date, ′MM′) As Mon,
SUM (quantity*unit_price) As Sales
FROM Orders JOIN Order_Items USING (order_id)
WHERE order_date BETWEEN ′01/01/2019′ AND ′31/12/2019′
GROUP BY TO_CHAR (order_date, ′MM′)
ORDER BY Mon;
Пример 5.12. Вывести общую сумму продаж за каждый месяц каждого года
SELECT TO_CHAR (order_date, ′YYYY MM′) As Year_Mon,
SUM (quantity*unit_price) As Sales
FROM Orders JOIN Order_Items USING (order_id)
GROUP BY TO_CHAR (order_date, ′YYYY MM′)
ORDER BY Year_Mon;
Используя JOIN, можно установить соединение трех и более таблиц. В общем виде такое соединение можно представить следующим образом:
{таблица 1} JOIN {таблица 2} {условие соединения 1}
JOIN {таблица 3} {условие соединения 2}
……………………….
JOIN {таблица N} {условие соединения N — 1}
Пример 5.13. Для сотрудников из отдела 80 определить общую сумму продаж
SELECT employee_id, first_name, last_name, job_id,
SUM (quantity*unit_price) As Sales
FROM Employees JOIN Orders ord ON (employee_id=salesman_id)
JOIN Order_Items oit ON (ord. order_id = oit. order_id)
WHERE department_id =80
GROUP BY employee_id, first_name, last_name, job_id;
Бесплатный фрагмент закончился.
Купите книгу, чтобы продолжить чтение.