

Вызовы цифрового мира
Приход цифрового мира
Приходящий цифровой мир принципиально изменяет подходы и способы построения организаций и управления ими. Первой с этим столкнулась IT-отрасль, и в ней двадцать лет назад появился Agile-менеджмент, отвечающий на новые вызовы. А 5—7 лет назад интенсивные изменения начались и в других отраслях. Об этом видно по распространению Agile за пределы IT, большому интересу к бирюзовым организациям, основанным на самоуправлении и множеству других свидетельств. Эти изменения не случайны, а носят системный характер.
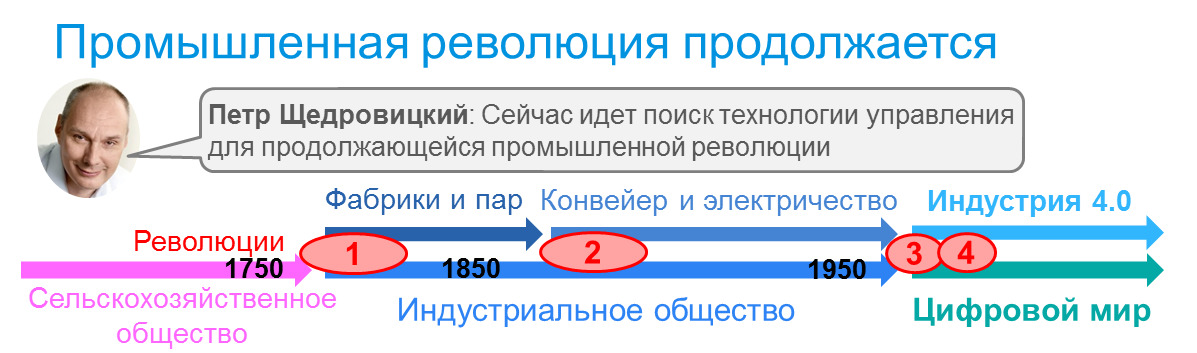
Как учит нас системный подход, изучение любого явления надо начинать с рассмотрения контекста. Контекстом изменений менеджмента является происходящая промышленная революция, ведущая нас в цифровой мир или мир индустрии 4.0. Это — не просто мир роботизированного производства на заводах без человека, это еще и новые способы организации этого производства и деловой жизни в целом и управления ими, и становится это очевидным, если посмотреть на историю.
Первая промышленная революция — это не только паровой двигатель, это еще и фабрики с разделением того труда, который в ремесленных мастерских выполняли мастера, на отдельные операции, технологичная организация работы и новая транспортная инфраструктура железных дорог, которыми тоже надо было научиться управлять. А вторая промышленная революция — это не только электричество и новые материалы, массово производимые на химических заводах, но и конвейер Форда, и транснациональные корпорации, которые тоже начались с Форда, потому что для обеспечения своего автомобильного завода требуемым металлом и резиной для колес ему пришлось самому перестраивать и металлургию и производство резины.
И если с этой точки зрения посмотреть на третью, научно-техническую революцию, которая связывается с развитием науки и техники, включая появление компьютеров примерно в 1960—1990, то можно отметить, что ее результаты были использованы в рамках ранее сложившихся способов организации производства, и с этой точки зрения ее нельзя считать завершенной. Именно разворачивающаяся сейчас цифровая революция призвана завершить преобразования, которые включают в себя не только заводы-роботы и управляемые автопилотом автомобили, но и персонализированное производство вместо типового, а также принципиальное изменение способов организации бизнеса на основе цифровых платформ, которые мы сейчас видим в Uber, Aliexpress и других. Отметим, кстати, что английские источники, такие как wikipedia.org/wiki/Technological, revolution#Potential, future, technological, revolutions не присваивают научно-технической революции отдельного номера и относят ее на более ранний период, а третьей промышленной революцией считают именно цифровую революцию, начавшуюся в 1975 и продолжающуюся сейчас.
Об истории промышленных революций сопоставлении их между собой, выявлении общей логики развития и формированием на их основе картины будущего много и интересно рассказывает Петр Щедровицкий. У него есть супер-короткий 12-минутный доклад об этом, и много развернутых выступлений на его сайте, включая подробный разбор пути России. И тех, кому эта тема интересна, я рекомендую смотреть и разбираться.

Об этой книге
У меня есть картина происходящих изменений, которую я рассказываю в статьях и выступлениях. Статья «Agile и бирюзовые организации — ответ менеджмента на вызовы новой промышленной революции» была опубликована в сборнике ПИР, а статья «Бирюзовые организации и agile: какие полезные практики стоят за хайпом», опубликованная в сентябре 2019 на портале vc.ru вызвала большой отклик читателей. Но материалов — много, полная сборка слайдов для выступлений превысила 200, в одной статье или лекции их можно изложить лишь поверхностно. И поэтому осенью 2019 года я решил написать серию статей. Это было успешно проделано, первая статья была опубликована на vc.ru 22 ноября 2019, а последняя в серии 52-я статья 10 июня 2020 года, вот оглавление на моем сайте.
Публикации вызывали отклик, и были пожелания от читателей сделать на их основе книгу. Однако, крупные издательства, признавая интересный материал, были согласны на публикацию только при оплате спонсором без каких-либо перспектив возврата денег. Естественно было опубликовать на ridero — это бесплатно. Однако, инициативу губил перфекционизм. Статьи были рассчитаны на изолированное прочтение, и это вело к повторам. Кроме того, я публиковал их сразу после написания, и разбивка на отдельные статьи частично была ситуативной, а изложение не всегда последовательно и логично. Это хотелось исправить, но работа откладывалась в пользу более важных и интересных дел. В конце концов, статьи уже опубликованы и доступны желающим в таком виде.
Однако, зимой 2022 года я готовил курс по менеджменту цифрового мира, и помимо лекций необходимо учебное пособие. статьи могут выступать в этой роли, их надо собрать в единый файл. Поэтому я наступил на горло своему перфекционизму, взял исходные тексты статей, которые готовил в Word и поверхностно прошел по ним, заменив в ссылках «статьи» на «главы», убрав в начале каждой статьи изложение предыдущего и внеся другие небольшие редакторские правки. При этом, возможно, был утерян ряд правок, которые я делал непосредственно при публикации на портале. И получилась эта книга.
События 2022 года поставили в фокус моих интересов тему самоопределения, у меня была серия докладов и статей на эту тему. Работа над темой потребовала глубокой проработки устройства личности человека, к которой я подошел как ИТ-архитектор. Результатом была архитектурная модель личности, объединяющая модели психологии и нейрофизиологии. Она была опубликована в виде серии статей, на основе которой весной 2024 года на ridero вышла книга «Инженерная модель личности», В отличие от Менеджмента цифрового мира, книга вышла не только в электронном, но и в бумажном варианте, и это оказалось востребованным, не взирая на потерю цветов при черно-белой печатью. А со ссылками, оказалось, можно удобно разобраться, добавив в книгу QR-коды после каждого раздела.
И я решил обновить эту книгу: я прошел по тексты, актуализировал ссылки, часть из них теперь ведут на archive.org, и добавил QR-коды. Еще обновил некоторые иллюстрации, чтобы было контрастное черно-белое изображение, а в схемы спиральной динамики добавил названия цветов. Основной текст я не менял, кроме малого количества редакторских правок и нескольких примечаний. В целом содержание книги сохраняет актуальность, и хотя некоторые разделы я бы, конечно, сейчас доработал, это было бы более подробное раскрытие и иллюстрация новыми примерами, а не изменение содержания. Наверное, я это сделаю в будущем, а пока обновляю книгу для комфортного печатного варианта.
Особо следует сказать про последний раздел книги. Он включает статьи, опубликованные после основной серии. Они посвящены различным вопросам, и при хорошей переработке материала в книгу их следовало бы поместить на подходящие места. Однако, это требует существенной переработки текста — поэтому они оставлены в конце. Среди них хочу отметить главу «Реальность цифрового мира: проекты делает некомпетентная команда», фиксирующую новую реальность: компетентную команду собрать невозможно, а ведь это — необходимое условие для успешных проектов в классическом менеджменте. А глава «Agile-методы и проектный подход — в чем разница?» сопоставляет проектный подход и Agile-методы. В основной части эти методы разбираются последовательно, а такое сопоставление повышает понимание различий — они не ограничиваются отсутствием в Agile-методах требования компетентности команды для успеха проекта.
И пара слов обо мне. Я из ИТ, более 25 лет архитектор, бизнес-аналитик и разработчик в проектах разработки и внедрения корпоративных и банковских систем, которые неизбежно сопровождались трансформацией бизнес-процессов организаций — и это я тоже умею. В 2007 — знакомство с Agile и начало активного участия в сообществе AgileRussia, применение Agile-методов при ведении проектов и сопряжение их с методами классического проектного управления и другими методами регулярного менеджмента, которые обычно применяли компании-заказчики.
И с 2017 года я, продолжая работать над ИТ-проектами, стал консультантом по применению Agile-методов и других методов самоуправления — бирюзовыми организациям, холакратии, социократией за пределами ИТ, навигатором по миру нового менеджмента цифрового мира. А также рассказываю ИТ-шникам и консультирую ИТ-компании по альтернативным моделям самоуправления, спиральной динамике и другим моделям soft skill, необходимым в современном менеджменте. Опыт работы аналитика позволяет объяснять это на понятном языке, приземлять на знакомый материал. Подробнее — на моем сайте http://mtsepkov.org, там более 230 моих статей и выступлений по разным темам и много других материалов.

Цифровой мир: от физического труда — к умственному
Наиболее очевидный вызов цифрового мира для менеджмента — это перейти от организации физического труда, task work, к организации труда умственного, knowledge work. Сила этого вызова стремительно возрастает по мере цифровизации бизнеса.
Традиционный менеджмент, сформировавшийся в ХХ веке, в фазе завершения второй промышленной революции и последовавшем после него периоде устойчивого развития, основан на регламентах, нормировании деятельности через инструкции и компетенции. Он представлен в трех основных вариантах: Process, Project и Case management. Уверенный результат достигается только в случае Process management, однако сама организация процесса и разработка регламентов опирается на компетентность организатора, а не на технологию управления. В случае Project management на компетентность участников опираются фазы анализа и создания самого проекта, а для Case management требуется высокая компетентность во всей деятельности.
Сейчас все эти подходы перестают действовать. Во-первых, потому что knowledge work невозможно организовать с помощью регламентов, что хорошо показывает история IT. Во-вторых, потому что период промышленных революций характеризуется быстрым изменением условий бизнеса, в которые и регламенты и компетентность перестают действовать, потому что не успевают за потоком изменений. И это можно наблюдать в многочисленных статьях о новом вызове Business Agility, которые принес VUCA-мир.
В этот период размываются границы традиционных отраслей и разрушаются стабильные условия. Ярким примером этого может служить банковская сфера, где банки начинают конкурировать с мобильными операторами и социальными сетями, не отягощенными регулированием и отраслевыми традициями и действующими очень быстро и гибко. Соцсети и мобильные операторы предоставляют возможность перевода средств, отбирая банковскую комиссию, но и сами банки идут в смежные отрасли, продавая билеты, туры, страховки. Поэтому даже если в вашей отрасли ничего нового не происходит, перемены все равно приходят из другой, неожиданной области. Отметим, что VUCA, то есть нестабильный, неопределенный, сложный и неоднозначный, он только относительно небольшого периода стабильности после второй мировой войны, а если сравнивать его с периодом промышленных революций и интенсивного развития на рубеже 19 и 20 веков, то вряд ли в те годы ситуация была более предсказуема. Тогда столь же интенсивно, появлялись новые отрасли и способы производства, разрушая уклад, казавшийся стабильным.
Кстати, кто не знаком с понятием VUCA-мира — гуглите, и вам объяснят, что это — акроним, расшифровка которого показывает аспекты изменчивости и непредсказуемости современного мира. И в этих объяснениях, скорее всего, будет меме ярко выражен тревога или страх жизни в эпоху перемен, которая и породила мем. Но это — только для скучных людей, на самом деле, жизнь в эпоху перемен и прогресса — интереснейшее приключение с множеством возможностей, и нам повезло жить сейчас.
Питер Друкер начиная с 1980-х анализирует изменения и вызовы, которые несет менеджменту автоматизация рутинного труда и переход к работе, связанной со знаниями, посвящая этому главы в своих книгах. А в начале века написал об этом отдельную книгу «Менеджмент. Вызовы XXI века». Основной вызов состоит в том, что все большая доля деятельности будет требовать от сотрудников решений «менеджерского» уровня. В традиционном менеджменте такие решения требуют личных способностей и опыта, и доступны ограниченному кругу сотрудников, получивших соответствующее образование и прошедших отбор. Они медленно накапливают опыт и компетенции, двигаясь от решения простых задач к более сложным. Если все простые задачи решают компьютеры и роботы, такой путь становится невозможным. В обществе, управляемом знаниями, области высокой компетентности расширяются и охватывают всю деятельность. С помощью традиционного обучения сформировать новые компетенции также невозможно из-за высокого темпа изменений: традиционные курсы требуют для становления 5—7 лет минимум, и потому оказываются устаревшими уже в середине создания.
Почему в области умственного труда не работают регламенты? Потому что от выбора метода решения принципиально меняется его трудоемкость, а инструкцию по выбору написать нельзя. С этим сталкивался всякий, кто в институте решал задачи аналитического интегрирования. Или увлекался задачами на геометрические доказательства в школе — одно удачное дополнительное построение может сделать нерешаемую задачу очевидной. И решения о выбранном методе принимает исполнитель, который делает задачу, более того он принимает не одно, а десятки таких решений, почти на каждом шагу — потому что когда метод не дает результата тоже надо принять решение — настойчиво пробовать дальше использовать тот же метод или остановиться и попробовать другой. И потому эти решения не могут быть переданы менеджерам или опытным сотрудникам — тогда, по сути, решать задачу будет другой человек. Впрочем, менеджерам для решения профессиональных задач не хватает компетентности и знаний предмета. О проблемах менеджеров, которые взялись принимать профессиональные решения в современном мире, есть замечательная серия комиксов Скотта Адамса про Дильберта, одну из которых я привожу как иллюстрацию. Кто не знаком с этим феноменом — гуглите и получайте удовольствие.

В этих условиях сотрудники должны сами организовывать свой труд и собственное обучение. И Питер Друкер предсказал принципиальное изменение рынка труда, к которому приведут эти изменения: возможность самореализации становится ключевым фактором при выборе места работы, а мотивация деньгами перестает работать. Именно это сейчас наблюдается не только в IT, но и во всех других наукоемких и требующих креативности отраслях, и чем дальше, тем эффект усиливается.
Заметим, что образ организации с самореализующимися и развивающимися сотрудниками очень напоминает ту идеальную картину, о которой пишет Фредерик Лалу, рассказывая о бирюзовых организациях. Сам Друкер не пишет, как будет устроена такая организация, более того, он полагает, что существующий на момент написания книги менеджмент не знает этих ответов. Питер Друкер — один из создателей менеджмента и до конца жизни оставался действующим теоретиком менеджмента, поэтому его трудно заподозрить в незнании каких-то секретных методов менеджмента, которые эту проблему решат.
Кстати, необходимо отметить одно интереснейшее следствие того, что люди выбирают работу для своей реализации и развития. Оно заключается в том, что вся работа выполняется некомпетентными людьми, которые взялись за нее, чтобы научиться в процессе работы и это — вызов, который их драйвит. В лучшем случае компетентные эксперты доступны для вопросов, но заняты другими, более сложными и интересными задачами, которые являются вызовом уже для них, а делать то, что они умеют им скучно. Конечно, не все люди таковы, особенно сейчас, когда культура и школа прививают любовь к рутинной работе, но эта ситуация изменяется, и меняться она будет только в сторону дефицита компетентных исполнителей. Впрочем, об изменениях mindset, мировоззрения мы поговорим в следующей главе. А сейчас отметим, что важнейшее условие успеха регулярного менеджмента — наличие компетентных сотрудников — в новом мире оказывается не выполненным.
В заключении отметим, что, как это обычно происходит, о грядущих изменениях писали давно, но когда они начали интенсивно происходить, то для многих менеджеров это оказалось такой же неожиданностью, как для коммунальных служб приход зимы и выпадение снега в декабре.
Поколение соцсетей — новый mindset цифрового мира
Главное изменение, которое несет промышленная революция — конец индустриального общества. И это изменение тоже давно предсказано. Почти 40 лет назад, в далеком 1980 году, Элвин Тоффлер в книге «Третья волна» писал о неизбежности принципиальных изменений, показывая, что сложившиеся механизмы и мировоззрение индустриального общества будут несовместимы с тем новым, что несут технологии. И делал вывод о кардинальных изменениях, переосмыслении понятий и ценностей, которые приведут к радикальному изменению бизнеса и организаций, семьи, государства и всего человечества.
Таким образом схему, приведенную в первой статье следует дополнить. Полная картина выглядит таким образом.
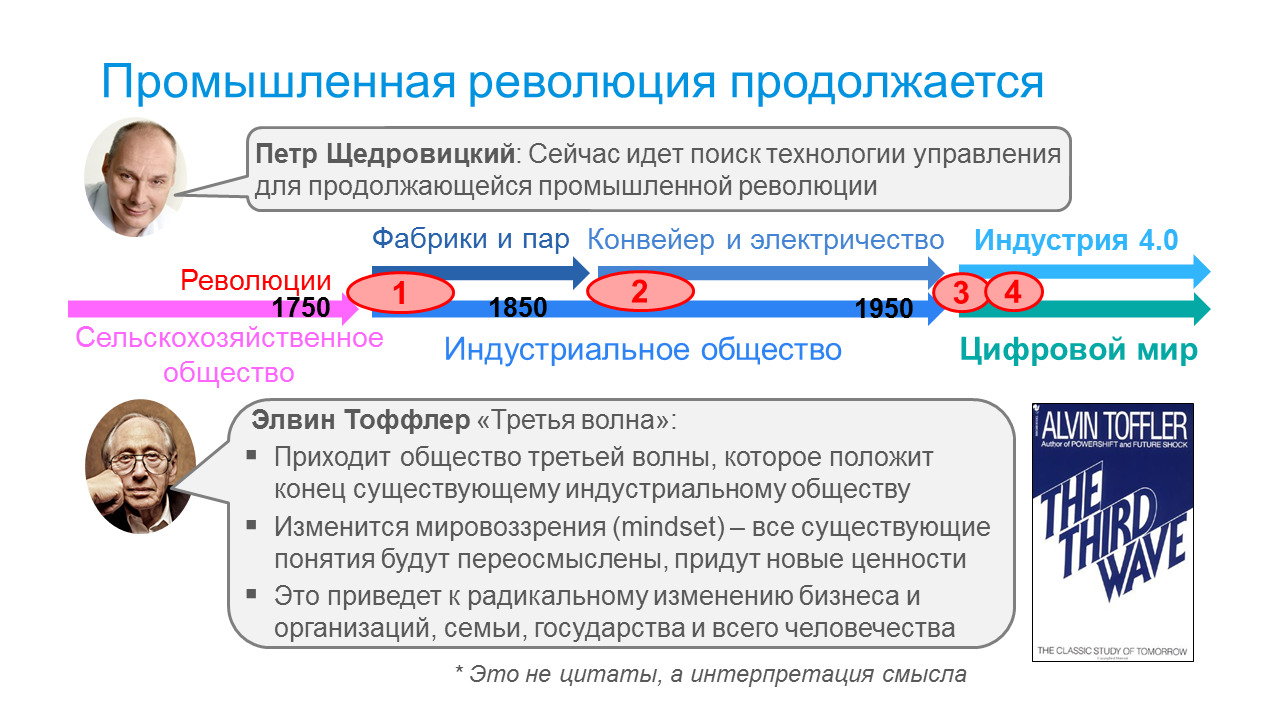
Тогда, в 1980-х, это было вопросом веры или доверия к результатам анализа. Однако сейчас этому предсказанию не надо верить или не верить, потому что развитие общества явно показывает его справедливость. Благодаря развитию IT-технологий: появился Интернет, а в нем — форумы и социальные сети. В этом новом пространстве коммуникаций сформировалось другое мировоззрение — mindset поколения соцсетей. Наиболее очевидно он проявляется в тезисе «работа должна давать фан и драйв, а не быть тяжкой обязанностью ради денег». С этим сейчас сталкиваются практически везде, и чем квалифицированнее и способнее нужны люди, тем сильнее mindset поколения соц. сетей проявляется. Практика показывает, что решить вопрос традиционными способами, к примеру, высокими зарплатами, не получается.
Однако под поверхностью лежит еще один слой — изменение шаблонов успешного лидерства. Гэри Хэмел (Gary Hamel) в статье «The Facebook Generation vs. the Fortune 500», опубликованной в The Wall Street Journal (2009) (общедоступная ссылка) показал, что способы достижения успеха на интернет-форумах и группах в соцсетях противоречат традиционным шаблонам поведения, ведущим к продвижению в корпоративной культуре. Их отличия столь велики, что новое поколение в статье было названо в честь Facebook.
В чем же эти отличия? В интернете все идеи конкурируют на равных; мнения объединяются и рецензируются, авторитет и признание основано на обмене информацией, а не ее накоплении и удержании и личный вклад имеет большее значение, чем полномочия. Организация сообществ также отличается: иерархии не предусмотрено, лидеры служат, а не руководят, группы самоопределяются и самоорганизуются, ресурсы привлекаются, а не выделяются, задачи выбираются, а не назначаются, внутренние награды сообщества и признание служат мощным стимулом.
Кстати, когда я рассказал об этой статье в беседе на HR Media. Ведущие заинтересовались, нашли статью и сделали краткое изложение содержания по-русски.
— Все идеи конкурируют на равных. В Web, каждая идея имеет шанс получить продолжение или нет, и никто не имеет права убить идеи или подавить их в обсуждении. Идеи усиливаются на основе их сути, а не политической власти их авторов.
— Вклад имеет большее значение, чем полномочия. При публикации видео на YouTube, никто не спрашивает вас, учились ли вы создавать фильмы. Когда вы пишете блог, никого не волнует, есть ли у вас журналистское образование. Должность, звание и ученые степени, ни один из обычных отличительных статусов не имеют большого веса в Интернете. На веб, что важно не ваше резюме, а что вы какой вклад вы можете внести.
— Иерархии не предусмотрено. В любом интернет-форуме есть лица, пользующиеся большим уважением и на которых обращают внимание, как следствие, которые имеют большее влияние. Чрезвычайно важно, чтобы эти лица не были назначены кем-то из высшей власти. Их влияние отражает доверие своих сверстников. У веб власти потоки вверх, а не вниз.
— Лидеры служат, а не руководят. В веб, каждый лидер — слуга-лидер и никто не имеет право командовать или накладывать санкции. Достоверные аргументы, продемонстрированные знания и самоотверженные поведение только рычаги для влияния на других людей. Забудьте это в сети — и ваши последователи очень быстро покинут вас.
— Задачи выбираются, а не назначаются. Веб выбор в экономике. Этому может способствовать блог, работающий на проект с открытым кодом, либо обмен советами в форуме, люди предпочитают работать на вещи, которые их интересуют. Каждый независимый подрядчик, и все неудачи принимает на свой счет.
— Группы самоопределяются и самоорганизуются. В веб, вы получаете возможность выбрать соотечественников. В любом интернет-сообществе у вас есть свобода связаться с некоторыми лицами и игнорировать всех остальных, поделиться глубоко с этими людьми, а вовсе не с другими. Так же, как никто не может назначить вам скучной задачи и заставить работать с тупым коллегой.
— Ресурсы привлекаются, а не выделяются. В больших организациях ресурсы выделяются сверху вниз, в политизированной конкуренции советского стиля. В веб, усилия людей устремляются к идеям и проектам, которые являются привлекательными (и приятные), и уходят от тех, которые таковыми не являются. В этом смысле, веб рыночная экономика, это экономика где миллионы людей сами решают, в каждый момент времени, как потратить драгоценную валюту своего времени и внимания.
— Власть исходит от обмена информацией, а не ее накопления. Веб также подарок для экономики. Для усиления влияния и статуса, вы должны передать свой опыт и содержание. И вы должны сделать это быстро, если вы этого не сделаете, кто-то будет более быстрым и возьмет кредиты, которые могли быть вашими. В Online много стимулов для обмена, и мало стимулов для накопления.
— Мнения объединяются и решения рецензируются. В интернете, по-настоящему умные идеи быстро получают поддержку, какими бы разрушительными они ни были. Веб практически идеальная среда для агрегирования мудрости толпы, мнения формально организованных рынков или случайных дискуссионных групп. И этот голос масс может быть использован в качестве тарана укоренившимся интересам учреждений в автономном мире.
— Пользователь может наложить вето на большинство политических решений. Интернет научил онлайн пользователей упрямо с шумом и быстро атаковать любые решения или изменения политики, которые, по их мнению, противоречит интересам сообщества. Единственный способ сохранить лояльных пользователей — дать им возможность говорить по существу при принятии ключевых решений. Вы, возможно, построили сообщество — пользователи его владельцы.
— Внутренние награды наиболее важны. Сети являются свидетельством мощи собственных наград. Подумайте все статьи способствовавшие развитию Википедии, все программное обеспечение с открытым кодом создано из часов волонтерского времени. И это очевидно, что человеческие существа будут щедро отдавать себя, когда они получают возможность внести свой вклад в то, что их на самом деле волнует. Деньги настолько же важны, насколько признание и радость достижений.
— Хакеры герои. Крупные организации, как правило, делают жизнь неудобной для активистов и демагогов. Однако они могут быть и конструктивными. В отличие от реального общества в интернет-сообществах часто симпатизируют и поддерживают анти-авторитарную точку зрения. В веб недовольные часто становятся защитниками Интернет-демократических ценностей, особенно если им удалось взломать кусок кода, который был вмешательством в то, что другие считают их неотъемлемыми цифровыми правами.
Отметим, что эти способы поведения не являются чем-то принципиально новым, многие из них проявляются в неформальных детских командах. Только раньше школы и вузы готовили человека к принятию корпоративных правил: выделялись дети, успешно воспринимавшие эту культуру, остальных относили к хулиганам и не поощряли. А теперь соцсети показывают, что можно достигать успеха и принципиально иными способами. При этом в сети можно найти группы с самыми разными правилами, в том числе и организованные в корпоративном духе — со строгими модераторами, безусловным уважением авторитетов и так далее. И наблюдение показывает, что если тематика группы достаточно интересна, то свободолюбивая молодежь умеет туда встраиваться. Но когда их там становится большинство — они перестраивают правила, или организуют рядом другую группу, куда уходит вся жизнь. Поэтому Гари Хэмел делает вывод, что когда поколение, получившее mindset соцсетей еще в школе и институте, массово придет на работу, компании принципиально изменится, а кто не сможет — останется без кадров.
Впрочем, идентифицированная опасность изменений вызывает противодействие, и новые соцсети сконструированы таким образом, чтобы больше способствовать появлению кумиров и последователей, нежели лидеров и деятельных сообществ. Но изменения не остановить, потому что все это свидетельства общего тренда, а не его формирование.
Так же отметим, что главным признаком нового общества является самоопределение: в сельскохозяйственном обществе будущее человека определяла семья и родители, в индустриальном — само общество через механизмы массового образования, а в цифровом мире твой путь определяешь ты сам.
Это очень хорошо показывает развитие IT, в котором сейчас интенсивно работают над тем, чтобы научить всех сотрудников самостоятельно определять траектории своего развития. И не из абстрактной любви к сотрудникам или стремлению к их совершенству. Просто опыт показывает, что хорошо сделать это со стороны — почти невозможно, а неудовлетворенный своим ростом сотрудник голосует ногами и уходит из компании. И по мере цифровизации это предстоит пережить другим отраслям.

Культура и процессы — две стороны компании
Мы уже разобрали, что принципиальным изменением, которое приносит цифровой мир, является изменение мировоззрения, которое уже ярко проявлено как mindset поколения соц. сетей. И это означает, что менеджмент не может ограничиваться организацией процессов, а должен уметь работать с культурой компании.
Конечно, нельзя сказать, что о работе с культурой никогда раньше не говорили. при любом внедрении новых подходов всегда говорят не только о постановке определенных процессов, но и о проявлении новых подходов в культуре. Типичным примером может служить Lean или бережливое производство. Он включает организацию процессов на основе цепочек создания ценности (value stream) и постановку отдельных процессов, нацеленных на анализ и оптимизацию потока. А еще он не работает без создания культуры нетерпимости к бесполезной работе, которая не создает дополнительной ценности, и о том, что каждый сотрудник должен быть нацелен на оценку своей или чужой работы под этим углом зрения, и предлагать улучшения. Без такой культуры процесс оптимизации не сможет работать надлежащим образом.
И тут уместно привести схему Марка Розина «Кораблик», наглядно показывающую разделение компании на бизнес-процессы и культуру, и два паруса, которые их двигают: целеполагание и управление изменениями. На рисунке поверх этой схемы показано отражение в этих составляющих таких ключевых факторов организации как гибкость, эффективность и вовлеченность.
— Гибкость означает, что процессы адаптивны и быстро перестраиваются, и в них встроена обратная связь от клиентов. Но эти процессы не будут работать без культуры жизни в эпоху перемен, поощрения инициативы и чуткости к нуждам клиентов.
— Эффективность означает, что процессы измеримы по стоимости и создаваемой ценности и оптимизируются. И она требует культуры инициативного поиска мест улучшений в процессах.
— Вовлеченность означает, что сотрудники разделяют цели и ценности компании, и считают работу на них частью своего дела жизни. И она невозможна, если процессы не позволяют самореализацию и развитие сотрудника, в них нет места для его инициативы.
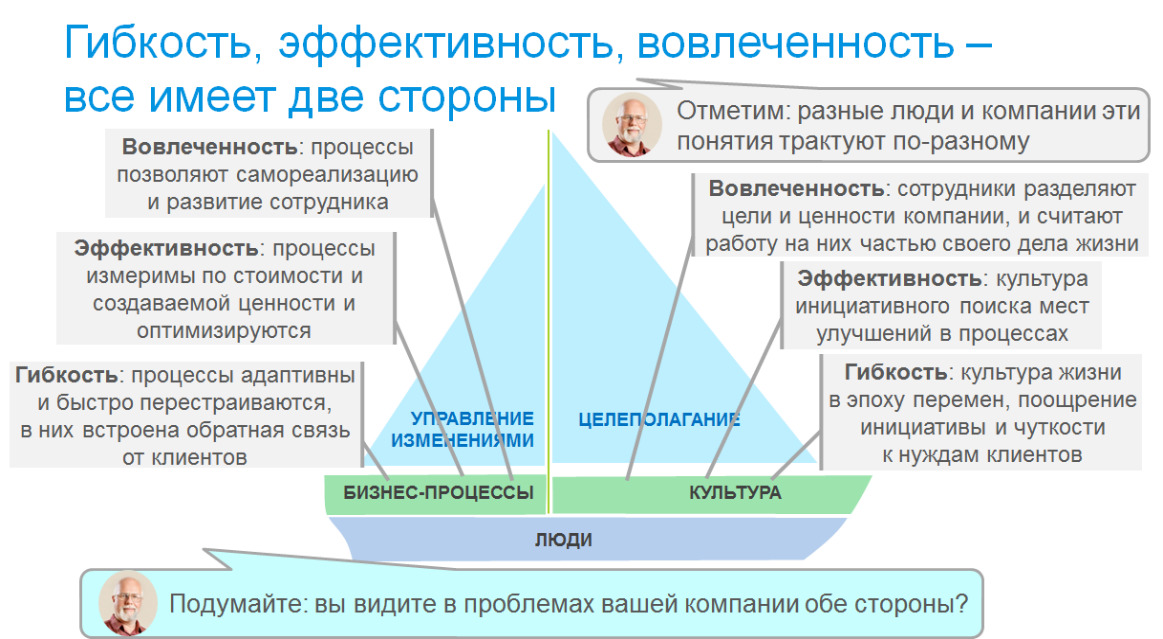
Подумайте, когда вы анализируете проблемы своей компании, или планируете, проведение изменений, вы всегда думаете про обе стороны медали, или только про одну? В жизни достаточно часто встречаются те, кто видит только одну сторону. Если видят только процессы, то возникает типичная ситуация, когда инициативы изменений саботируются и вязнут в культуре компании, и именно о такой ситуации Питер Друкер как-то заметил «культура ест стратегию на завтрак». Или появляется сожаление о природе человека: «каждый раз, когда мне нужна пара рук, к ним зачем-то прилагается голова». Эту фразу я услышал в одном из выступлений и выступающий приписывал ее Форду, она достаточно хорошо характеризует тех, кто мыслит процессами. Но не менее часто бывает и обратное, когда призывы о движении к великим целям и ежедневной работе не поддерживаются адекватной организацией процессов, и в результате все движение вязнет в хаосе несогласованных действий.
Однако, в индустриальном мире предполагалась, что есть единственная правильная культура, включающая правильную организацию труда, компетентных и ответственных сотрудников и не менее компетентных руководителей-лидеров, всеобщее сотрудничество, понимание сотрудниками целей компании и вовлеченность в их достижение, и так далее. И есть негативные варианты, при которых между сотрудниками и руководителями проходит антагонистичное разделение мы и они, вплоть до предельных форм классовой борьбы описанных Марксом, когда руководители — не компетентные бюрократы, или когда они вместо движения к общей цели устраивают крысиные гонки для достижения личных целей, и так далее. И есть задача руководителей и HR следить за проявлениями негативной культуры, исправлять и пресекать их.
Деструктивные варианты культуры компаний, бессмысленный мир корпораций хорошо описаны в книге Дэйва Логана, Джона Кинга и Хэли Фишер-Райт «Лидер и племя». И там же описан выход в здоровую культуру через обретение смысла. Однако, сейчас этого уже недостаточно, потому что поколение соцсетей несет другие ценности и смыслы. И единственный образ правильной компании со здоровой культурой размывается, у него получается много трактовок. Возможно, когда вы выше читали, как я в этой статье определяю гибкость, эффективность и вовлеченность, то не согласились с тем смыслом, который я вложил в эти понятия. И это — совершенно нормально. На самом деле я знаю не один и не два, а более пяти вариантов наполнения этих понятий смыслами. И не только для этих понятий — изменяется взгляд на лидерство, справедливость, назначение и роль бизнеса и практически все остальное. Хорошая иллюстрация этих изменений — уже упоминавшиеся комиксы Скотта Адамса про Дильберта. Вот пример, как воспринимается лидерство. Заметим, что при этом люди прекрасно знают правильные слова, и если надо — то будут их говорить. Но вот как они при этом будут действовать — тоже понятно.

Таким образом, в современном мире происходит следующее: молодое поколение, мыслящее по-новому, приходит в компанию, и им нужно сотрудничать с людьми более старшего возраста, эффективно работать вместе и не относиться друг к другу с пренебрежением. И потому при работе с культурой компании надо учитывать весь спектр смыслов, который разные люди вкладывают в одни и те же слова. И задача менеджмента — организовать такое сотрудничество. Работа с культурой становится намного сложнее, чем раньше, старые схемы — не работают, потому что не учитывают новые варианты.
Кстати, в уже упомянутой книге «Лидер и племя», описывающей пять корпоративных культур, авторы тоже столкнулись с этим феноменом. Они первоначально выделили и описали четыре культуры, три негативных варианта и один позитивный, компанию, которая сплочена и сотрудничает в достижении общей цели и потому уверенно побеждает конкурентов. А потом в компании Amgen они обнаружили культуру, которая не укладывалась в эту схему, но при этом была очень крутой: компания не боролась с конкурентами, а успешно изменяла мир к лучшему. И они два года исследовали ее, сочтя необходимым задержать выход книги. И это как раз проявление культуры компании, адекватной приходящему новому mindset. Впрочем, по одному примеру хорошего представления о конструкции новых компаний авторам получить не удалось. Но сейчас их становится больше. И мы еще вернемся к конструкции организаций будущего, когда в этой серии статей доберемся до разбора бирюзовых организаций. А пока я хочу порекомендовать книгу «Лидер и племя» тем, кто еще ее не читал. Ну и заодно порекомендовать свой разбор этой книги, включающий сопоставление с бирюзовыми организациями Фредерика Лалу.
Так же я хочу сказать, что многие почему-то полагают, что работа с культурой компании — это некоторое шаманство, или искусство, или непонятные психологические манипуляции. Это не так, работа с культурой компании вполне освоена в рамках менеджмента. Интересующимся я хочу порекомендовать книгу Марка Розина «Успех без стратегии» (мой конспект, одобренный автором), в пятой и, особенно, шестой главах Марк хорошо раскрывает технологичную работу с культурой. Просто раньше, в индустриальном мире, для этой работы можно было использовать более простые модели, не учитывающие формирующееся мировоззрение цифрового мира. А теперь нужны современные модели, такие, как модель Спиральной динамики, раскрывающие логику изменения систем ценностей. И эта модель тоже будет детально рассмотрена далее.

Три вызова цифрового мира
На данный момент можно заключить, что приход цифрового мира несет три основных вызова, которые обесценивают регулярный менеджмент, основанный на регламентах и компетентности сотрудников и требуют принципиально иных способов организации.
— Business Agility — необходимость для компаний быстро изменяться в ответ на высокую неопределенность и скорость изменения рынков в VUCA-мире. Изменения правил и регламентов не успевают за изменениями мира. Массовых курсов, обучающих эффективно действовать в условиях высокой неопределенности тоже нет.
— Цифровизация приводит к тому, что то, что ранее делали по регламентам — делает IT и роботы. Людям остается только обработка особых случаев, а также умственная и творческая работа. Раньше этим занимались только люди, обладавшие соответствующими способностями или приобретавшие опытом, а теперь это требуется от всех.
— Mindset поколения соцсетей: работа должна давать фан, драйв и самореализацию, человек должен быть счастлив на работе. Организация должна вовлекать людей с таким представлением о жизни, иначе останется без сотрудников.
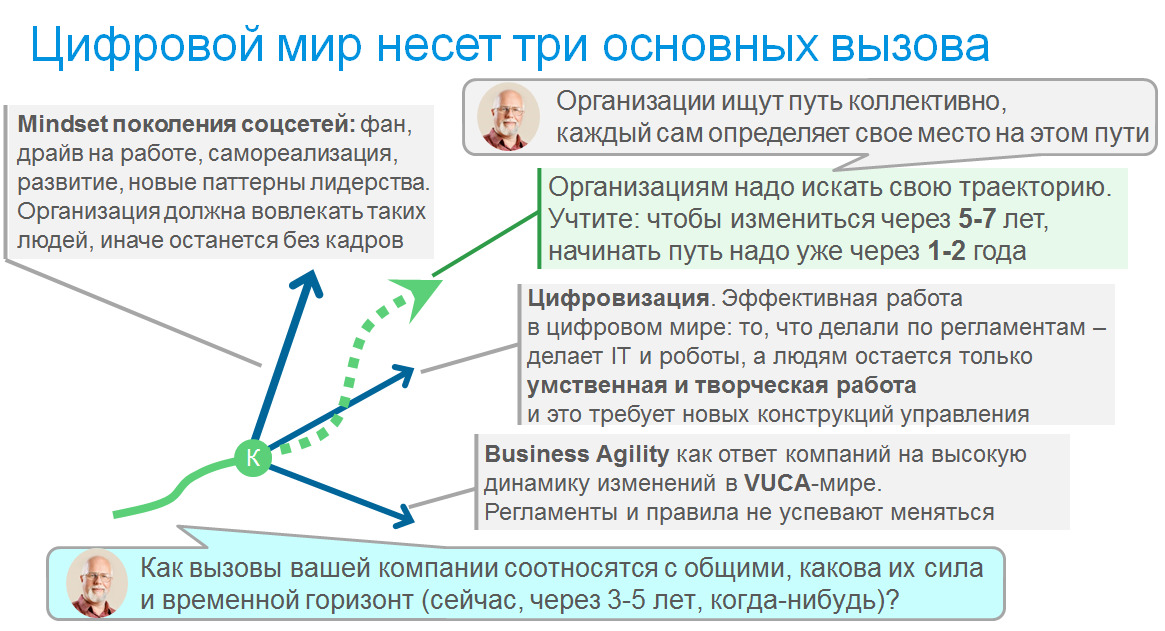
Разные отрасли развиваются в разном темпе, поэтому сила вызовов различна. И даже на разные подразделения одной организации эти вызовы могут действовать в разную силу. IT их ощутило уже более 20 лет назад, и Agile возник как ответ на них, это мы будем подробно разбирать в отдельных статьях дальше. И уже лет 5—7 назад свободный график, гибкая организация и отсутствие бюрократии стали стандартом де-факто не только в небольших стартапах и IT-компаниях, но и в IT-отделах крупных корпораций и банков. В 2012 я слышал, как руководители проектов Сбербанка, в котором тогда IT было организовано традиционно, жаловались, что не могут найти опытных разработчиков на интересный проект, несмотря на зарплату +30% к рынку: как только те узнавали, что работа с 10 до 17, и много бюрократии — они теряли интерес к предложению.
Сейчас в уже говорят о новом социальном контракте сотрудника, который приходит на смену старому «зарплата в обмен на компетентное выполнение своих обязанностей». Этот контракт звучит так: «искренняя работа на цели компании в обмен на условия для счастья на работе». И это — всерьез, услышав на AgileDays-2019, как Александр Горник говорит об этом контракте и призывает «не стесняйтесь требовать от компании выполнения ее части контракта», я написал об этом статью «Социальный договор цифрового мира: работа должна обеспечивать счастье, а не только деньги». И меня позвали сделать об этих изменениях доклад на конференцию РИТ++, собирающую более 3000 участников, где счастью на работе был посвящен отдельный трек. Конечно, это пока первые ласточки, но ориентироваться на темпы, которыми в IT распространялся Agile, то можно предположить, что лет через пять или чуть больше новый контракт распространится по IT, включая IT-отделы корпораций, заинтересованные в квалифицированных разработчиках. А практически это означает все корпорации. Потому что даже авиакомпании сейчас конкурируют не самолетами и не пилотами, они конкурируют бонусными программами привлечения пассажиров и логистикой самолетов, снижающей оплату стоянок в аэропортах и повышающей часы полета, а и то и другое обеспечивается IT-программами.
Если учесть, что пять лет на изменения в большой компании — это очень быстро, то получается, что готовиться к этим изменениям надо уже сейчас, ну, через пару лет максимум. Тем более, что Agile уже завоевывает не только IT, но и R&D отделы корпораций, да и на основном производстве тоже применяется. Например, на AgileDays-2019 был доклад о применении его методов на литейном заводе, и делал его не Agile-коуч, а заместитель генерального директора. И было много других докладов, интересующиеся могут посмотреть программы конференций или мои репортажи с конспектами докладов можно по ссылкам AgileDays-2019, AgileDays-2018, AgileBusiness-2018. К докладам на этих и других конференциях мы еще не раз будем обращаться в этой книге, и почти после каждого доклада есть ссылка на мой отчет, где есть его конспект, поэтому QR-коды этих отчетов собраны отдельно в конце книги.
Компаниям стоит вырабатывать свою траекторию движений в цифровой мир с учетом контекста изменения рынков, цифровизации и изменения рынка персонала в ее сегменте. А вам, мои читатели, стоит задуматься про ваше место на этом пути, в вашей нынешней компании или, быть может, за ее пределами. Цифровой мир — это не только мир IT и роботов, но и мир самоопределения. И счастье в нем — зависит от самого человека.
На этом я завершаю первую главу, которая была посвящена вызовам нового мира. Вторая глава будет рассказывать про Agile — не только про процессы и методы, но и про логику развития, и про изменение культуры IT-проектов в целом, включая современный этап. И это может быть интересным не только тем, кто хочет применить Agile в своей компании, но и тем, кто активно взаимодействует с IT-шниками и хочет понять их логику управления проектами. Отметим, что вокруг Agile-методов сейчас множество мемов и профанаций, вызванных общим дефицитом компетентных специалистов, так что разбираться самостоятельно — полезно. Я знаком с Agile более 10 лет, и активно участвовал в сообществе AgileRussia с самых первых собраний в 2009.
Третья глава будет посвящена модели Спиральной динамики, которая раскрывает логику развития систем ценностей, и при этом применима как к отдельному человеку, так и к организованностям: командам, компаниям, сообществам, странам и обществу в целом. И, что особенно важно, она описывает не только логику развития человека и общества в прошлом, но и логику совершающегося перехода в цифровой мир и дает достаточно уверенные предсказания относительно будущего. И потому, на мой взгляд, она является наиболее подходящей моделью для работы с ценностями человека и культурами компаний на современном этапе.
Так же мы подробно рассмотрим развитие менеджмента в модели спиральной динамики, включая развитие agile. Немного затронем игрофикацию как способ адаптации к mindset поколения соц. сетей в областях, где регламенты по-прежнему позволяют организовывать работу. Впрочем, в организациях цифрового мира игрофикация тоже оказывается уместной. А затем перейдем к бирюзовым организациям, холакратии и социократии, как альтернативной ветви развития менеджмента цифрового мира. Отметим, что хотя логика развития — иная, практики хорошо дополняют друг друга и могут применяться совместно — в IT сейчас это происходит. И в заключении будет рассмотрена трансформация организаций. Естественно, вопросы трансформации и применимости разных методов для решения задач.
Agile
Краткая история IT-менеджмента
В первой главе я раскрывал вызовы, которые приход цифрового мира принес менеджменту, которые обесценивают методы классического менеджмента и требуют принципиально новых подходов. Эти вызовы первыми пришли в IT-отрасль. Вернее, они были там с самого ее начала, но первые десятилетия на них пробовали ответить в рамках регулярного менеджмента. И это были сильные попытки, которые, в том числе, развили проектный подход и привели его в современное состояние, PMBOK во многом основан именно на практиках IT-проектов. Но в целом эти попытки потерпели неудачу, гарантировать успех проекта — не получилось. И именно поэтому в начале нулевых появился Agile как альтернатива регулярному менеджменту, и за прошедшие годы завоевал IT-мир, став стандартом де-факто, а теперь идет в другие отрасли. Развитию Agile-менеджмента будет посвящена вторая глава, а начну я с истории культур и методов ведения IT-проектов.
Отмечу, что я, естественно, не первый, кто обращается к истории развития IT-менеджмента и показывает ее как историю развития культур. В 2008 была опубликована книга Энтони Лаудера «Культуры программных проектов». В духе времени он решил не публиковать бумажную книгу, а выложил текст в интернете. Перевод на русский был сделан Альбертом Мустафиным и выложен в блоге happy-pm по главам и целиком в pdf. А здесь рецензия Стаса Фомина, от которого я в свое время узнал про книгу.
Энтони выделяет в истории развития четыре культуры: научную, заводскую, дизайнерскую и сервисную. Для каждой из них характерен свой подход к ведению ИТ-проектов: представления об успехе, критерии качества и организации работ. Каждая культура породила своих авторитетов и свои учебники, основанные на представлениях и задачах того времени и согласованные между собой.
Мое деление культур — отличается от того, что увидел Лаудер. В моей классификации тоже четыре культуры, но она доведена до нашего времени, и переход к последней около 2012 года, уже после публикации книги Энтони. Моя периодизация культур представлена на схеме.
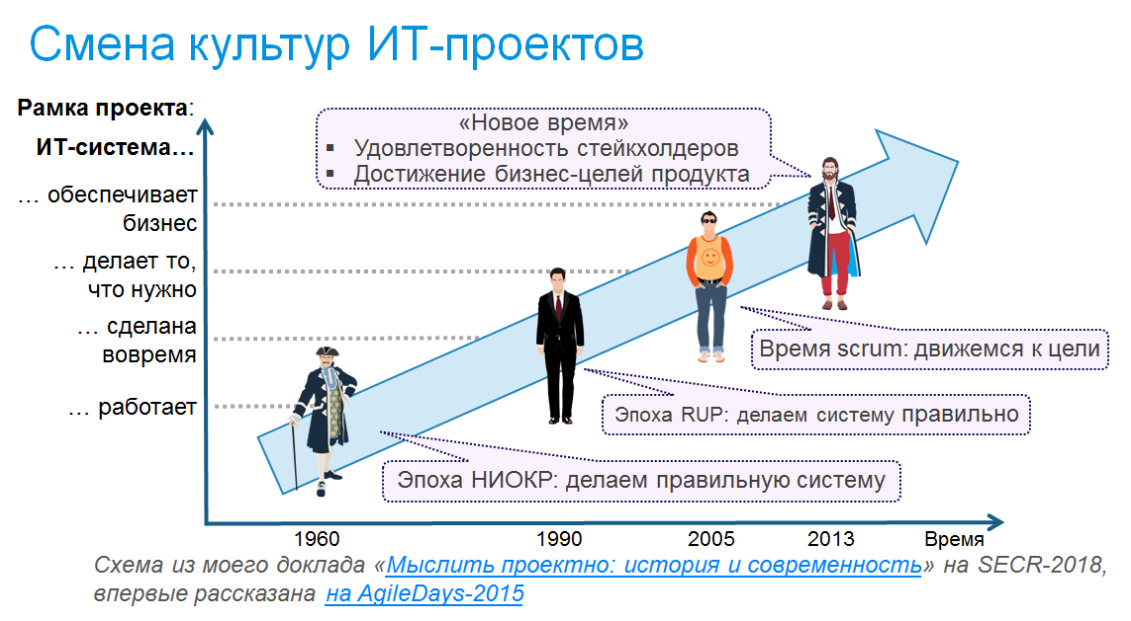
Каждая культура изменяет не только способ реализации проекта и управление им, она также расширяет рамку проекта. Эпоха НИОКР. Это период становления IT-отрасли, программы разрабатывались в университетах и институтах так же, как ведут конструкторские работы. Они и сами были частью более масштабных проектов, обеспечивая расчеты для военной, космической, атомной и других отраслей. Дело было новое, и основная проблема — добиться, чтобы программа работала, выдавала правильные результаты.
Эпоха RUP — классическое управление проектами. По мере развития отрасли возрастала потребность не просто разрабатывать программы, а делать это с предсказуемыми сроками и затратами, в соответствии с планами. Это пробовали делать методами классического менеджмента, и на этом пути были многочисленные неудачи, а успех так и не был достигнут. И в принципе в 1980-х уже поняли причину: ключевым фактором успеха IT-проектов являются не процессы, а человеческий фактор. Но плохие новости редко принимают и в 1990-е годы был предпринят значительный рывок в этом направлении — были собраны реальные гуру IT и создан Rational Unify Process (RUP), из которого позднее в значительной мере вырос современное проектное управление с его руководством PMBOK (Project Management Body of Knowledge). Но успеха достигнуто не было, предсказуемого результата получить не удалось, несмотря на многократно возросшую стоимость тяжелой процедуры.
И как альтернатива тяжелым методам RUP на рубеже 21 века появились легкие Agile — подходы, наступило время Agile и Scrum — первого из Agile-методов. который и принес ему успех. Формально зарождение Agile — 2001, год подписания Agile-манифеста (на русском). Идеи очень простые: раз человеческий фактор — главное, то построим процесс на сотрудничестве людей, а не на регламентах. А раз результат все равно гарантировать нельзя — будем наблюдать за продвижением к нему.
В это же время произошло принципиальное изменение в IT: появились персональные компьютеры. И дело не в том, что они появились дома — компьютеры появились в небольших компаниях и сразу возникла потребность в разработке множества программ, учитывающих особенности конкретных компаний. Гибкие виндовские системы, типа современного 1С появились много позже. И возникла большая потребность в разработчиках. Отметим, что на постсоветском пространстве эта потребность была закрыта за счет развала оборонки, когда множество инженеров ушло в IT, а на западе этого не было. Так вот, оказалось, что Scrum позволяет за счет командной работы достигать результата даже при недостатке компетенций, или хотя бы наблюдать за траекторией движения.
А еще изменились условия проекта: пока проект разрабатывается — бизнес-процессы живут и изменяются и это надо учесть при разработке. Прежде проекты делали для гораздо более стабильных условий, изменением которых за время разработки было можно пренебречь. В бизнесе, особенно в небольших компаниях, это невозможно, бизнес-процессы меняются постоянно и программа, разработанная по требованиям годовой давности, оказывается ненужной. Эту проблему Scrum и другие Agile методы хорошо решают.
Все это определило успех Agile, сначала он завоевал небольшие компании, а в конце нулевых пошел в крупные компании и IT-отделы корпораций. К тому времени, помимо Scrum был Kanban, гибридный Scrumban, и еще ряд методов и практик, несущих больше IT специфики и потому менее известных (XP, FDD, TDD, DDD и другие).
По мере того, как IT все больше входило в жизнь компаний и обеспечивало их бизнес-процессы, произошел следующий сдвиг рамки проекта: результатом проекта должно быть не просто разработка и внедрение софта, а решение в результате внедрения конкретных бизнес-задач и достижение возможностей бизнеса, при чем достижение результатов определяется не формальными критериями, а удовлетворенностью стейклолдеров. Принципиально изменился характер задач, которые бизнес ставит перед IT: не «разработать конкретный набор фич», а «доработать продукт так, чтобы доля занимаемого им рынка в Латинской Америке возросла с 3 до 7%», не «внедрить новую систему управления складом», а «добиться вместе с логистиками, чтобы пропускная способность склада в пиковую нагрузку увеличилась вдвое». И это по времени совпало с развитием интернет и ориентацией для продукты для конечного пользователя, а не для компаний, что вызвало свое семейство методов ведения проектов, основанных на User Experience. Которые, кстати, сейчас становятся актуальными и в других отраслях. Эта культура пока не имеет общего названия, потому что она не осознается как нечто цельное. Однако, составляющие ее концепты широко известны: UX, продуктовый подход, DevOps. Поэтому на слайде она просто обозначена как «Новое время».
Таким образом, каждая культура имела свои представления о том, что такое хороший проект и качественный продукт, которые кратко отражены выше на схеме. Но самое главное отличие возникает, когда что-то пошло не так, когда в ходе разработки оказалось, что проект невозможно сделать в запланированные сроки и бюджеты, или что разрабатываемая система не будет решать ту задачу, которую на нее возлагали. Культуры регулярного менеджмента предлагают заказчику смириться: НИОКР — потому что всякие исследования и конструкторские работы могут быть окончиться неудачей, а RUP — потому что заказчик ведь сам согласовал то задание, которое было выполнено и возможные риски. Естественно, исполнитель всегда готов открыть новый проект и попробовать еще раз решить задачу с учетом полученного опыта. Но после оплаты ранее сделанного, а процесс устроен таким образом, что неудача обнаруживается близко к завершению. Типичная ситуация в IT — когда после того как бюджет израсходован на 90% выясняется, что задача сделана наполовину, и надо еще столько же. И так — несколько раз. Agile не дает гарантии результата, но в нем это явно оговорено, в то время, как регулярный менеджмент результат обещает. Однако он предлагает заказчику постоянно следить за движением проекта и корректировать направление, чтобы прогнозы становились более реалистичными. А еще — начинать с зон наибольшей неопределенности, а не откладывать их на потом, чтобы, встретив там существенные трудности, заказчик мог быстро свернуть проект — это принцип Fail fast. А современные подходы, помимо раннего обнаружения проблем и культуры постоянных экспериментов и проверки гипотез нацелены на партнерство IT и бизнес-заказчика в решении проблем и достижении возможностей.

Мы рассматриваем конструкцию Agile, так же упомянув о развитии и провале регулярного менеджмента в управлении IT-проектами. Во-первых, для того, чтобы вы понимали, где и почему они не сработали в IT, и могли оценить — изменилась ли с приходом цифрового мира ситуация у вас в отрасли так, что регулярный менеджмент тоже перестает работать. В во-вторых, чтобы выступая как заказчик IT-проектов, вы могли оценить уместность классических методов. Потому что, несмотря на многолетний опыт отрасли, показывающий ограниченность методов регулярного менеджмента, светлая идея проектов, сделанных «качественно и по уму в настоящей инженерной культуре» продолжает быть крайне привлекательной. Культуры уходят, а учебники остаются, и часто используются для обучения молодежи, в и результате получается эклектика несогласованных концепций, противоречащих друг другу. Культуры уходят, а учебники остаются, и часто используются для обучения молодежи, в и результате получается эклектика несогласованных концепций, противоречащих друг другу.

Развитие и провал регулярного менеджмента в IT
Сейчас я подробно рассмотрю развитие регулярного менеджмента в IT и причины его провала. Как пишет Эдвард Йордан в книге «Смертельный марш», история IT — это история безнадежных проектов. К этой книге мы еще вернемся, а пока отметим, что с развитием цифровизации эта же ситуация воспроизводится в других отраслях, и потому этот материал интересен не только IT- шникам. Тем более, что миф о том, что существует правильный способ выполнения IT-проектов, обеспечивающий гарантированный результат, и он точно известен компетентным инженерам, которых просто надо найти, является чрезвычайно распространенным и заманчивым, и в эту ловушку неоднократно попадались и продолжают попадаться и те, кто заказывает IT-проекты, и те, кто их делает.
Итак, эпоха НИОКР. На заре IT, когда компьютеры были большими и стояли в только научных центрах, университетах и крупных корпорациях, разработка софта была похожа на опытно-конструкторские разработки, да еще со значительной исследовательской составляющей. Целью проекта было создание совершенной системы в единственном экземпляре. И выполнялись методами, характерными для НИОКР. Тогда была разработана принципиальная схема V-модель для описания этапов процесса разработки и ее разомкнутая линеаризация в виде водопадной модели (Ройс, 1970). Отметим, что итерации обратной связи, которые представлены на V-модели, принципиально отличаются от современных итераций большой длительностью и тщательной проектированием системы. Ни о каком выделении минимального продукта (MVP) речи не шло, проекты длились годами. А условия для большинства из них были стабильными, потому что речь шла о расчете физических процессов, таких как полет ракет и самолетов, которые происходят по неизменным законам.
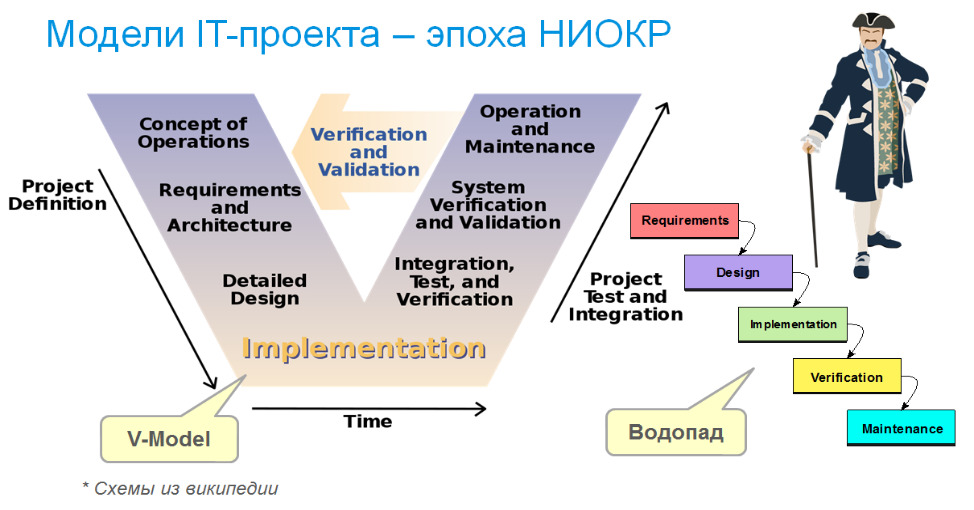
Что касается организации работ, то характерную метафору для описания команды разработки дал Фредерик Брукс — бригада главного хирурга, состоящая из компетентных специалистов разных областей, дополняющих друг друга, всегда готовая к проведению сложных операций и успешно их выполняющая. И сразу понятно, что успешные разработчики — специалисты высокого класса, настоящие профессионалы, которых не может быть много. Правда, проблема заключалась в том, что практически такую команду, создающую софт примерно с такой же уверенностью, с которой бригада хирургов проводит операции собрать было невозможно. Очень много проектов в этой метафоре квалифицировались как экстраординарные операции, успех которых не гарантирован.
По мере того, как потребность в IT-проектах возрастала, а область использования IT начала включать не только военные и научно-исследовательские проекты, но и коммерческие проекты, росло желание каким-либо образом обеспечить результат. И менеджмент пошел по известному ему пути ввода правил и регламентов, ресурсного планирования, нормирования работ и учета рисков. Вот тут-то проявилась особенность IT — регулярный менеджмент плохо работает для организации умственного труда. Как общий вызов современности мы ее обсуждали в ранее, в главе «Цифровой мир: от физического труда — к умственному». А тогда, в 1960-х она ярко проявилась в проекте IBM разработки новой операционной системы OS/360. Результаты попыток применить привычные менеджменту подходы в IT-разработке были хорошо проанализированы Фредериком Бруксом, который как раз руководил этим проектом, в книге «Мифический человеко-месяц» (1975), обобщающей опыт многих проектов и ставшей бестселлером. В частности, он сформулировал парадоксальных закон «Если проект не укладывается в сроки, то добавление рабочей силы задержит его ещё больше», и этот закон не является единственным результатом.
Собственно, в чем смысл подхода проектного управления? В том, чтобы всю неопределенность движения по V-диаграмме перенести на стадию проектирования, а то, что не получается — явно выделить как риски, оставив на стадии разработки только типовые операции с предсказуемой трудоемкостью. Тогда после завершения проектирования ход разработки становится предсказуемым, и менеджеры смогут управлять им в классическом треугольнике объем (scope) — сроки — стоимость в одном из его вариантов.
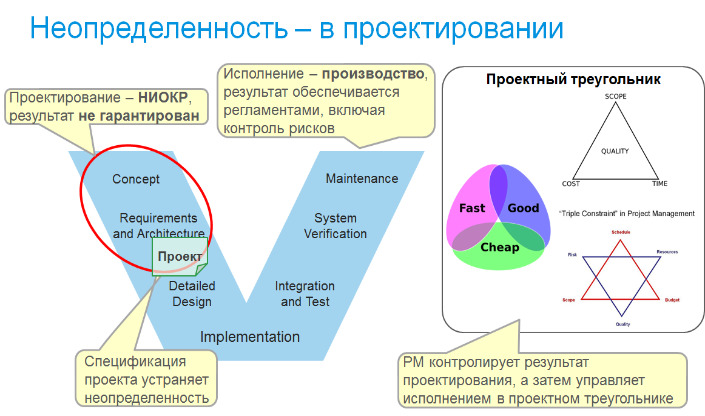
Почему это не работает? Причина — в том, что работа в IT нормируется очень плохо, скорость ее выполнения существенно зависит от человеческого фактора. Не просто от конкретных людей, а от людей в конкретных условиях, знания о том, как человек раньше решал аналогичные задачи не помогает предсказать, как он решит очередную. Влиянию человеческого фактора на ход проектов посвящена классическая книга Тома ДеМарко «Peopleware» (1987), которая в русском переводе так и называется «Человеческий фактор».
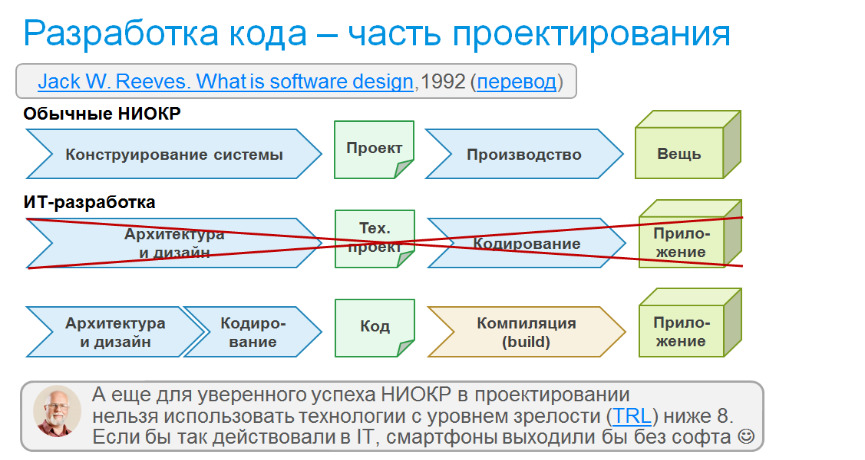
Почему же построить процесс проектирования самолетов, исключив человеческий фактор, так, что после принципиального проектирования новый самолет можно контрактовать Боингу удалось, а вот решить аналогичную задачу в IT — не получается? Причина заключается в природе IT-разработки. Это тоже было выяснено давно, этому посвящена статья Джека Ривза (Jack W. Reeves) «What is software design» (1992, перевод). Дело в том, что при сопоставлении разработки софта с НИОКР в других отраслях, например, проектирование самолетов, мы должны отнести написание кода не к производству, а к низкоуровневому проектированию. То же, что делают заводы на опытном производстве в IT делает среда разработки, собирая проект, делает быстро и дешево и потому ошибки проектирования не критичны, их исправляют не тщательной предварительной проработкой, а тестированием и отладкой. Это сильно дешевле статистически, но делает выполнение конкретной задачи слабо предсказуемым, вернее, получается распределение с жирным хвостом, так, что для срок для 90% уверенности в три раза превышает мат. ожидание. Об этом был интересный доклад Андрея Бибичева «Пуассоново горение сроков». Схематично это изображено на рисунке. А я отмечу, что задачу IT-разработка оказалась как раз той областью, где Боинг тоже постигла неудача: множество скандалов вокруг его самолетов связаны как раз с бортовым софтом.
Впрочем, и менеджеры и инженеры редко верят в то, что какие-либо вещи являются невозможными. И невзирая на статистику проектов и объяснение причин в 1990-х была предпринята масштабная попытка создать предсказуемый процесс. Компания Rational Software собрала гуру IT-разработки и поставила такую задачу. В результате появился Rational Unify Process (RUP), универсальный процесс, включающий все возможные варианты, из которого надлежало выбрать нужное для проекта и использовать. В дальнейшем он послужил основой PMBOK. Эксперимент окончился неудачей: стоимость разработки с соблюдением всех процедур возросла многократно, а гарантий успеха — не получилось.
Одним из громких провалов проектов в IT является история нового денверского аэропорта (1993—1995). Его пуск в эксплуатацию был задержан на полтора года из-за того, что не была готова система управления автоматической доставкой багажа к самолетам. При этом проектировщики аэропорта не заложили возможности доставлять багаж вручную: доставка должна была осуществляться по подземным туннелям, диаметр которых не позволял использовать средства с водителем. Представьте размер убытков: все эти полтора года новый построенный аэропорт не могли запустить, а старый, в центре города и уже проданный инвесторами — продолжал работать. История рассказана в книге Тома ДеМарко и Тима Листера «Вальсируя с медведями», а я ее услышал от авторов, когда они в 2012 приезжали в Москву.
Еще одна провальная история регулярного менеджмента в IT — свежая, 2013 год — это история ObamaCare. Создание сайта для регистрации страховок национальной программы HealthCare.gov по первоначальным оценкам требовало 94 млн$, еще до старта работ сумма выросла до 292 млн$, а фактически сайт обошелся в 1.7 млрд.$. И при этом на момент старта сайт был практически не работоспособен: при планируемой нагрузке в 60000 посетителей тесты показывали максимум 1100, только 1% посетителей в первом месяце смогли завершить регистрацию из-за множественных ошибок и так далее. Интересно, что провал проекта в некоторых статьях приписывают как раз применению agile-методов отдельными подрядчиками. Но факт состоит в том, что это — государственный проект, в нем участвовало более сотни подрядчиков, генподрядчиком была одна из крупных IT-компаний с мировым именем, и его вели по тем методикам проектного управления, которые были приняты в США как стандарт, там есть регулирование. И блистательно провалился. Провал имел политические последствия и Обама после него озверел и организовал US Digital Service, который начал разрабатывать нормативку для ведения госпроектов по гибким методологиям. Историю я услышал в 2015 на AgileKitchen по применению Agile в госпроектах (мой отчет), а в комментариях к моему посту (Agile — это Карнавальная ночь как способ производства),подробно разбирались со ссылками на источники — люди хотели быть уверенными в достоверности. Потому что подобные истории подрывают веру в проектный менеджмент, что для многих людей является потрясением основ…
Непредсказуемость IT-проектов имеет еще одну причину — быстрое развитие технологий. Есть шкала Technology rediness level, разработанная NASA для оценки технологий, закладываемых при проектировании космических кораблей. И для гарантии детального проектирования и разработки самолета Боинг разрешает закладывать при принципиальном проектировании в новый самолет со зрелостью не ниже 8 из 10. Если же мы посмотрим на современную IT-разработку, то там активно используются технологии уровня 4—5. И не из-за тяги к новизне и риску, а потому, что технологии не успевают созреть, и без этого мобильные телефоны оставались без софта несколько лет после изготовления, а новые возможности железа не были задействованы софтом. Как легко догадаться, такая картина невозможна. А использование незрелых технологий чревато непредвиденными рисками при осуществлении проекта, потому что задачи, которые оценивали как легко решаемые с помощью каких-либо новых фреймворков или библиотек, вдруг оказываются сложными, и не потому, что сама технологий не подходит в принципе, а потому что в рамках фреймворка эта задача еще не является стандартной, и надо не просто воспользоваться готовой библиотекой, а дописать эту библиотеку в процессе решения. Кстати, сейчас это достаточно распространено: вендоры не успевают за развитием технологий, поэтому по многим новым подходам, например, реактивному программированию, разработчики используют open source библиотеки, дорабатывая их в ходе проекта.
Я хочу в конце вернуться к тому, с чего начал — к книге Эдварда Йордана «Смертельный марш». Эта книга написана в 1997 и подводит почти 40-летний опыт IT-менеджмента, и он заключает, что «безнадежные проекты являются нормой, а не исключением», несмотря на то, что каждое новое поколение менеджеров, вооружаясь новыми методологиями, обещает этого не допустить. Безнадежный проект — это такой, вероятность провала которого более 50%, иногда существенно, ввиду дефицита одного или нескольких ресурсов в два или более раз по сравнению с нормальными оценками или по другим причинам. Как он пишет, наиболее простой ответ на то, почему так происходит, состоит в том, что люди — идиоты. Но поскольку «слишком тягостно представить себе, что вы идиот, окружены идиотами и руководят вами идиоты», то он приводит более развернутый список причин, по которым появляются безнадежные проекты.
— Политика, политика, политика
— Наивные представления маркетинговых служб, высшего руководства, менеджеров проекта и др.
— Наивный оптимизм юности: «Мы сможем сделать это за выходные!»
— Менталитет первопроходцев у неопытных предпринимателей
— Менталитет «Морского Корпуса» (Marine Corps): Настоящие программисты не нуждаются в сне!
— Высокая конкуренция, порожденная глобализацией рынков
— Высокая конкуренция, вызванная появлением новых технологий
— Сильное воздействие неожиданных правительственных решений
— Неожиданный и/или незапланированный кризис — например, ваш поставщик оборудования/ПО только что обанкротился, или три ваших лучших программиста только что умерли от бубонной чумы
И далее он подробно разбирает эти причины и логику развития проекта. И, поскольку попытки сделать проекты в логике «настоящего проектного управления» не прекращаются до сих пор, эта книга тоже сохраняет актуальность.
Отметим, что Agile-методы не изменяют ситуацию с предсказуемостью проектов. Она объективна и кроется в природе IT. Поэтому они предлагают признать это, и действовать сообразно устройству мира, а не вопреки ему. Конструкцию Agile-менеджмента мы начнем разбирать далее.

Agile — ответ IT на вызовы цифрового мира
Agile появился в IT рубеже 21 века в IT как альтернатива регулярному менеджменту в ответ на вызов цифрового мира: обеспечить организацию проектов умственного труда при дефиците кадров и высокой динамике развития. Я хочу подчеркнуть, что Agile — он не про то, как сформировать индивидуальную траекторию развития компании, о необходимости которой я писал ранее, а он про то, как по этой траектории двигаться. Потому что старые способы движения, которые предлагал, говорил регулярный менеджмент — точно не подходят, принципиальную неспособность регулярного менеджмента организовать умственный труд.
Итак, в 1980-х при анализе опыта IT было осознано, что ключевым фактором успеха IT-проектов является человеческий фактор, а не организация процессов. Об этом — классическая книга Тома ДеМарко «Peopleware» (1987). В 1990-х была предпринята попытка найти решение хотя бы для крупных проектов, в которых стоимость не имеет принципиального значения, гуру IT разработали Rational Unify Process (RUP), но даже для них гарантировать успешную реализацию в соответствии с планами не получилось. Параллельно в с 1980-х шло интенсивное развитие персональных компьютеров, которые стали доступны средним и мелким фирмам. Это вызвало большую потребность в разработке софта для автоматизации бизнес-процессов. учитывающих специфику конкретного бизнеса — обобщенных конфигурируемых решений, подобных 1C тогда не существовало. При этом такие проекты обладали значительно более скромными ресурсами. Кризис доткомов также ярко показал необходимость найти решение для скромных проектов и стартапов. Отметим, что автоматизация мелкого и среднего бизнеса, а также разработка для стартапов имеют принципиальную особенность: среда, в которой должен работать софт, сильно изменяется за время разработки. Если вы принесли продукт, разработанный по требованиям годовой давности, он оказывается никому не нужен, в отличие от военных или научных проектов, касающихся моделирования физического мира или автоматизации крупных корпораций, процессы в которых относительно стабильны. По сути, это — можно рассматривать как предвестие VUCA-мира, в котором IT начал существовать.
Каким же образом Agile удалось ответить на вызовы организации умственного труда и разработке для VUCA-мира? А очень просто: раз ключевым фактором успеха IT-проектов является человеческий фактор, значит не надо ставить на процессы, а надо сделать ставку на команду, которая сама организует свою работу. А чтобы команда объединилась в движении к общим целям, необходимы ценности, которые послужат основой. Так появился Agile-манифест (2001) (на русском). Заметим, что ответ ассиметричный: проблема лежит в области процессов, а решение — в области культуры. Это явно видно на схеме, приведенной ниже, где конструкция Agile помещена на схему кораблика.
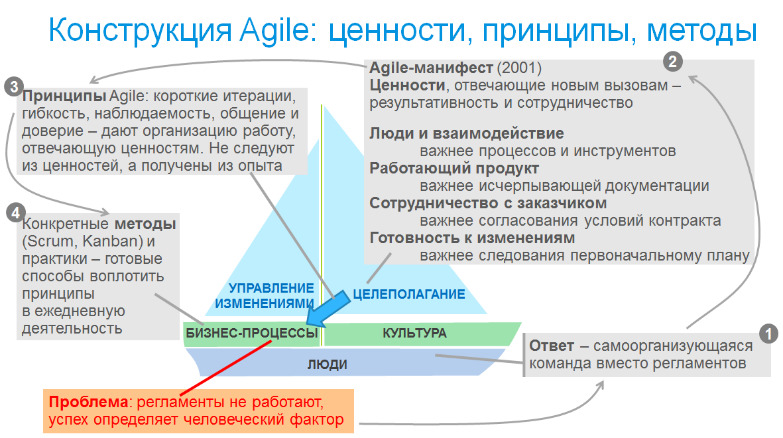
Итак, ценности Agile-манифеста:
— Люди и взаимодействие важнее процессов и инструментов
— Работающий продукт важнее исчерпывающей документации
— Сотрудничество с заказчиком важнее согласования условий контракта
— Готовность к изменениям важнее следования первоначальному плану
Что тут важно? Как я показывал ранее, есть системные причины, по которым IT-проекты не развиваются в соответствии с планами. Столкнувшись с такими ситуациями, менеджеры шли по понятному им пути — пробовали взять под контроль все что только можно. Но это — не помогало. И в результате в других проектах жесткий контроль пробовали вести с самого начала. И Agile-манифест родился именно как противодействия этим бессмысленным попыткам тотального контроля. И поэтому он делает особый акцент как раз на ценности сотрудничества и результативности, в противовес тем формальным вещам, на которые делали акцент менеджеры озабоченные, быть может, не столько успехом проекта, сколько попытками избежать ответственности за неудачу. Есть еще один аспект, связанный с американским концептом универсального менеджмента, не зависящего от предметной области, который лучше всего выразил MBA. Правая, менее важная часть ценностей представляют собой то, что не зависит от предметной области, и с чем менеджеров учили работать. В то время как левая представляет значительно более зыбкие понятия, следование которым, к тому же, во многом противоречит урокам менеджмента. И в результате в условиях ограниченных ресурсов и сроков менеджеры реально выделяли ресурсы на документацию и работу с условиями контракта, а не на решение вопросов работоспособности софта или совместному с заказчиком решению проблем. А опыт IT-проектов однозначно говорит, что если делать акцент на вторую часть ценностей в ущерб первой, то проект точно не будет успешен. Понятно, что когда качаешь маятник, то он качается гораздо дальше, чем хотелось бы. С ценностями Agile-манифеста это тоже произошло, в некоторых командах начали вести проект без документации и процессов вообще, не работать с условиями контракта и откликаться на любые изменения мгновенно так, что к ходу проекта вполне возможным было применить поговорку «нас невозможно сбить с пути — нам все равно, куда идти». И потому в современных условиях обязательно надо помнить о ценности обоих частей, но не забывать о сравнительной важности, которую задает манифест, она по-прежнему актуальна. Но ценности остаются пустыми декларациями, если организация работы не позволяет их достигнуть. И потому помимо ценностей Agile-манифест включает принципы организации работы. Важно, что принципы не следуют из ценностей, они опираются на обобщенный опыт ведения IT-проектов, и несут довольно много специфике отрасли. С этим связана сложность при переносе Agile-методов в другие отрасли: ценности перенести относительно просто, в их основе лежит результативность и сотрудничество, которые носят общезначимый характер. И я видел адаптации ценностей Agile-манифеста для продаж, маркетинга, образования и ряда других отраслей. А вот принципы, по которым следует организовывать работу для достижения успеха, могут значительно отличаться из-за специфики отрасли. Именно из-за отраслевой специфики я не разбираю принципы подробно: IT-шники их и так знают, а остальных надо будет излишне погружать в контекст отрасли, обосновывая их.
Однако, необходимо отметить самую главную составляющую принципов — постоянную оценка достигнутого результата, продвижения проекта к намеченным целям и актуальности этих целей, соответствия ожиданиям заказчиков и пользователей. Именно в этом состоит замена традиционной концепции подробного планирования и далее — просто оценке следования плану, которую можно проводить механистично. Вместо этого мы постоянно смотрим: получено ли в результате разработки то, что действительно несет ценность и решает проблемы, как задумано? Как далеко мы продвинулись и сколько еще осталось? Каков прогноз достижения результата к бизнес-срокам, не пора ли существенно пересматривать состав работ? В целом, это достаточно естественный подход к ведению проектов со значительной долей неопределенности и Agile просто фиксирует, что IT-проекты именно таковы.
И, наконец, самая известная часть Agile — конкретные методы организации работы, такие как Scrum. Они дают способ воплощения принципов в виде некоторых процессов. Они обладают простотой и наглядностью, и потому привлекательны. Казалось бы, ничего сложного: берешь руководство и воплощаешь в организацию компании. Однако, будучи конкретной реализацией принципов, они обладают ограничениями, касающимися класса проектов, для которых они эффективны. Про это часто забывают, пытаясь применить их для совсем других категорий проектов. А еще забывают о том, что применение организационных фреймворков типа Scrum в IT поддержано большим количеством инженерных средств и практик, таких как Continious Integration, автоматические тесты, Task tracker и многих других. Если мы переходим в другую область, то эти средства тоже следует забирать. Одни из них забрать легко, например, Task tracker или доски, Jira сейчас применяется для любых задач, а не только в IT. Другие перенести невозможно, и надо вырабатывать альтернативные способы, чтобы обеспечить организационному фреймворку необходимую поддержку.
Так что простота Agile-методов — кажущаяся. Курсы и тренинги для начинающих обычно показывают ту часть, которая необходима для освоения фреймворка и трансформации организации под руководством опытного Agile-коуча, а не самостоятельно. Для самостоятельной работы надо разбираться в их конструкции глубже. Это и будет предметом следующих статей, начнем мы со Scrum, потом будет Kanban и более сложные конструкции, а дальше рассмотрим варианты применения для решения разных задач и конкретные кейсы Agile-трансформации. Естественно, это теоретическое знание все равно не заменит практического опыта, который есть у Agile-коучей. Но, я думаю, он позволит вам лучше разобраться в спектре Agile-методов и разумно выбирать варианты и стать квалифицированным заказчиком внедрения Agile. Тем более, что универсальных специалистов, знающих и способных внедрять все Agile-методы, практически не существует, а значит необходимо выбирать того, кто владеет методами, подходящими для вашей организации. Особенности вашего бизнеса знаете вы и потому конкретные решения принимать вам самому или совместно с ним. Вариант трансформации по готовому решению тут не работает.
Так же мы будем рассматривать Scrum — метод организации работы команды, который определил успех Agile-подхода. Да, он — не единственный, не самый первый, и далеко не самый общий, но именно его эффективность привела к широкому распространению Agile. Одна из причин — оказалось, что за счет разделения ответственности менеджера и командной работы в Scrum удается преодолеть дефицит компетентных руководителей групп и компетентных разработчиков. С появлением персоналок, доступных мелким и средним компаниям, и вызвавший большую потребность в IT-проектах этот дефицит был очень острым и именно он, на мой взгляд, способствовал быстрому распространению Agile-подходов на Западе. На постсоветском пространстве появление персоналок совпало с развалом оборонки и в IT пришло очень много квалифицированных инженеров, поэтому потребность была не столь острой. Следы этого сохранились и сейчас, но в целом современная IT-разработка основана на Agile-методах и на Западе и в России. Более того, если кто помнит главу о развитии IT-менеджмента в целом, с тех пор произошел еще один сдвиг культуры, о котором мы тоже будем говорить. Еще один фактор состоит в том, что в Scrum вставлены специальные предохранители против возврата к обычному менеджменту, и потому он способствует пониманию командой ценностей и принципов Agile. Но по этой причине его внедрение — всегда революция. В отличие от Kanban, который имеет гораздо более широкий диапазон применения. Он внедряется эволюционно, и его удерживает культура, а не процессы, а это всегда сложнее. Kanban мы тоже рассмотрим, как и выбор конкретных методов в разных ситуациях Agile-трансформации.

Scrum — метод, принесший успех Agile
Scrum — пять изменения организации команды
Мы начинаем рассматривать Scrum — метод, которому Agile обязан своим успехом. И начну я это со списка пяти принципиальных изменений организации команды, которые он принес, а затем буду рассматривать их подробно.
— Кроссфункциональная команда вместо функциональных отделов
— Разделение ответственности менеджера на три части: Product Owner, Команда и Scrum Master
— Закрепление в процессе управления через самоорганизацию команды с предохранителями против микроменеджмента
— Визуализация продвижения к результату с помощью доски и burndown chart
— Короткий цикл поставки ценности с обратной связью — это обеспечивает результативность
Итак, первое изменение — кроссфункциональная проектная команда вместо функциональных отделов специалистов. Отметим, что проектные команды были достаточно распространены в IT. Но не менее было распространено и деление специалистов на функциональные отделы с передачей задач от отдела к отделу. И делали это в полном соответствии с учебниками менеджмента, чтобы обеспечить равномерную загрузку специалистов. Проблема лишь в том, что такое преобразование эффективно лишь в условиях, когда технология работы обеспечивает гарантированный результат, и возвраты по фазам работ — редки. В IT это не так, проект развивается в условиях неопределенности, а возвраты возникают часто. В этих условиях команда, обладающая всеми компетенциями, чтобы решить задачу — наиболее эффективный способ организации. Даже если в результате не все члены команды будут загружены полностью. Отмечу, что это — совершенно общий принцип: в стабильных условиях выигрывает специализация и технологии, и выгодно строить длинные цепочки создания ценности с разделением на операции. А в условиях неопределенности результата и отсутствия технологий, дающих гарантию, эффективны короткие цепочки, в пределе — одна команда, которая доводит задачу до результата. Команда также может компенсировать недостаток компетенции отдельных специалистов за счет коллективного поиска решений. Отмечу, что вызовы цифрового мира — возрастание неопределенности VUCA-мира и цифровизация регулярных процессов, сохраняющая на людях только работу в особых случаях существенно повышают неопределенность в задачах и в других отраслях. И потому отказ от функциональных отделов в пользу команд, обеспечивающих решение задач с сокращением цепочек создания ценности — часть естественной перестройки организаций.
Надо отдельно остановиться на том, что такое «кроссфункциональная команда», каких специалистов в нее надо включать? Общий ответ звучит так: всех, чьи действия существенных для комплексного решения задач, возлагаемых на команду. Команда может зависеть от внешних специалистов только в тех работах, которые нормированы и предсказуемы, и службы выполнения которых представляют инфраструктуру, то есть не являются ограничением для потока задач команды. В IT хорошим примером являются специалисты баз данных. Обычно разработчики имеют ограниченные компетенции по работе с базами данных и в команде специалист высокого уровня не нужен. Однако, когда идет разработка высоконагруженного приложения, для которой технические решения по работе с базой данных существенно влияют на его работоспособность, такой специалист в команде необходим. Аналогично и вне IT. Например, если решение задач включает заключение договоров, при этом договора — типовые, а юристы и бухгалтерия имеют налаженный документооборот, обеспечивающие прохождение договора в удовлетворительном темпе, то они могут быть за пределами команды. А вот если команда занимается уникальными сделками, требующими привлечения юристов и бухгалтеров для грамотного оформления, включая, возможно, переговоры с клиентом, то они должны быть в команде.
Возвращаясь к истории IT, надо сказать, что функциональная ориентация сотрудников проявлялась не только в организации отделов, но и в том, что даже будучи включенным в проектную команду каждый специалист ориентировался на решение только своих задач. Эта привычка, подлежащая искоренению. Да, мы ценим те компетенции, которые необходимы для проекта, и которые привели к включению в команде, но при этом полагаем, что конечная цель по решению задачи, которая стоит перед командой — важна и ожидаем сотрудничества и вклада даже в том случае, если профессиональные компетенции в моменте не востребованы. В IT вопрос стоял остро, и в ранних работах по Agile были жесткие формулировки: любой член команды может и готов решить любую из задач. А, чтобы вывести людей из функциональных границ, рекомендовалось, как возможная практика на начальном этапе внедрения, просто распределять задачи по жесткой очереди или даже по жребию, чтобы все быстро получили нужные компетенции. Позднее от этого отказались, и сейчас определение кроссфункциональной команды именно такое, как я написал выше. При этом приветствуется умение решать задачи из смежных областей, а не узкая специализация, чтобы команда могла справляться с неоднородным потоком задач. И, более того, узкие специализации бизнес-аналитиков и системных аналитиков объединились в просто аналитика, который заодно может являться в команде тестировщиком, аналогичные процессы можно проследить среди специализаций разработчиков. А в целом это соответствует общему современному тренду перехода от I-людей с одной специализацией к T-людям, умеющим работать и в смежных областях, и даже к m-людям, имеющим несколько глубоких специализаций.
Просто в IT это началось лет на 10—15 раньше, чем в остальных отраслях и не называлось таким образом.
Второе изменение организации — разделение ответственности менеджера, на мой взгляд, является ключевым. Его часто не акцентируют, а просто сообщают, что согласно Scrum Guide, команда включает в себя Владельца продукта (Product Owner), членов команды разработки (Development Team) и Скрам-мастера (Scrum Master). Product Owner отвечает за продукт, то есть за содержание той ценности, которую команда создает, команда разработки создает эту ценность, а фокус Скрам-мастера — помощь команде в ее самоорганизации для того, чтобы поставлять эту ценность быстро и качественно. Такое разделение решило старый спор о том, кто лучший руководитель в инженерных проектах — специалист в предметной области, или универсальный менеджер, который в предметной области не разбирается, зато обладает нужными soft skill, которые отсутствуют у предметника.
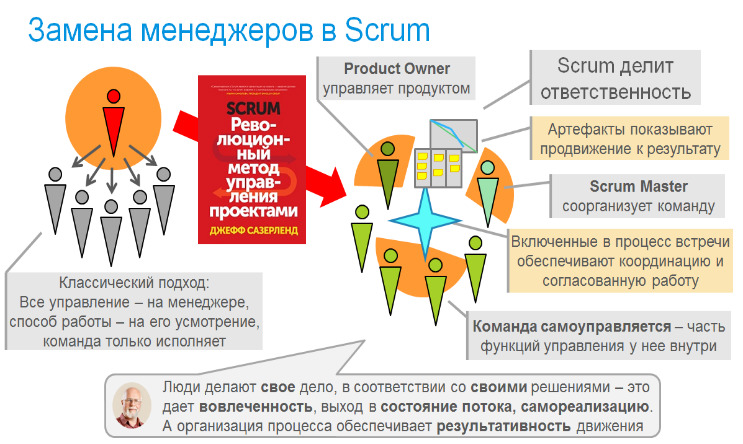
Отметим, что ответственность Product Owner за время развития Scrum претерпела эволюцию, связанную с изменением рамки проекта. В те времена, когда Scrum зарождался, заказчики софта обычно заказывали конкретный функционал, который необходим им для поддержки бизнес-процессов, а Product Owner при переговорах со стейкхолдерами оценивал техническую возможность разработки в разумные сроки, и от него требовалось больше компетенций именно в технической стороне. В настоящее время гораздо больший акцент в заказе — возможность решения конкретных бизнес- задач, и потому Product Owner должен быть специалистом в бизнесе. Впрочем, такое разделение сильно зависит от характера проектов и взаимоотношений с заказчиком, эти границы подвижны. Просто надо учитывать, что в разных книгах эта граница проведена по-разному, в зависимости от опыта автора.
В целом ответственность за технические решения по реализации лежит на команде. Scrum не говорит, как именно она устроена, однако он явно выделяет мероприятия, на которых реализация должна быть прояснена достаточно для уверенной оценки ее трудоемкости. И детали отдает на самоорганизацию команды. При этом, если компания устроена так, что в командах много новичков с недостаточным опытом, то часто выделяется роль технического лидера (Tech Lead) или архитектора — опытного специалиста, отвечающего за технические решения. Но это должно быть обосновано, и не случайно это не проявлено в Scrum Guide: если команда включает опытных самостоятельных разработчиков, то выделение ответственного за технические решения наоборот. является вредным и демотивирует других членов команды, превращая их в исполнителей. Поэтому лучшая практика — когда технические решения готовит исполнитель, а по существенным вопросам предлагает их членам команды на review. Отдельно надо подчеркнуть, что основная ответственность за организацию работ лежит на команде, а не на Scrum Master, который лишь помогает команде соорганизоваться. И это третье изменение — управление через самоорганизацию, блокировка микроменеджмента. Во всех учебниках по менеджменту говорят, что микроменеджмент не эффективен, что руководитель должен организовать работу так, чтобы не быть поглощенным операционной системой, ежедневно раздачей задач. А в Scrum это просто сделали на уровне процесса — в нем нет места, где можно отдать указания. Вообще. И если у члена команды с решением задачи возникают трудности — то он тоже не идет к кому-либо за указаниями, а запрашивает помощь по своему выбору, не отдавая при этом ответственность. А чтобы он не забыл и не стеснялся это делать, в процедуру ежедневных встреч (Daily Scrum Meeting) включен вопрос — что мешает продвигаться к решению задач.
Примерно таким же образом делится ответственность, если мы говорим о внедрении Scrum за пределами IT, например, в продающих подразделениях. Руководители, которые отвечали за определенные сегменты рынков становятся владельцами продуктов и ставят задачи. И команды продавцов уже сами решают. каким образом эти задачи выполнять. на чем концентрировать свои усилия, где есть перспективы. А роль Скрам-мастеров начинают выполнять руководители групп, отвечающие за организацию работ менеджеров по продажам, если они были в компании, а если их не было — то опытные из числа продавцов, кто может обучать других.
Отметим, что предохранители против микроменеджмента внутри процесса не будут работать, если окружение этому не способствует. Системы мотивации и оценки должны быть адекватны такой организации, а не противоречить ей. И в целом ценность самоорганизации должна быть признана руководством и командой, без нее в Scrum нет смысла. Раз мы разделили ответственность, возникает задача синхронизации представлений всей команды о продвижении проекта. И успех Scrum обусловлен тем, что он предложил простые инструменты для этого — доску и burndown chart, а также необходимое количество встреч для синхронизации. Это — четвертое изменение. Отметим, что одному руководителю такие инструменты не нужны, он вполне может работать диаграммами Ганта или другими сложными средствами, а вот требования для инструментов, используемых всей командой — гораздо выше. Техника работы с досками далее развивалась, и сейчас может дать эффект даже без изменения процессов, внедрение Kanban, например, начинается именно с визуализации на доске потока работ. В следующей статье мы ее обсудим подробнее.
А последнее, пятое изменение — итеративная поставка ценности. Это та самая схема Scrum, которая очень популярна, и с которой обычно начинают рассказ. Но которую часто понимают упрощенно — мы просто квантуем поток. Впрочем, иногда это уместно, потому что Scrum могут использовать как эффективный инструмент перестройки культуры компании, благодаря тому, что в процесс встроены предохранители против старого менеджмента, и Agile-коуч может не просто заметить, а явно и обоснованно указать команде на возврат к старому. Ну а через некоторое время это начинают делать Скрам-мастера и другие члены команды. И их замечания невозможно отвергнуть — есть Scrum Guide, который надо выполнять. Да, можно не выполнять — но тогда надо честно признать, что Scrum у вас — лишь вывеска, а не содержание.
Схема Scrum — сложная, она включает в себя и функциональную схему процесса и реализацию его элементов, и я ее тоже буду разбирать отдельно, уже после статьи про доски. А сейчас надо сказать, что Scrum-процесс — он на уровне команды. И он ничего не говорит, как синхронизовать работу разных команд, организовать управление компанией в целом. Это можно делать с помощью Kanban для потока ценности компании в целом, или использовать другие фреймворки, или строить собственные конструкции.
Доска — визуализация текущего состояния работы
Итак, разделение ответственности руководителя группы, при котором ее значительная часть передается всей команде, потребовало средств синхронизации представления о текущем состоянии работ для всех членов команды. Прорыв Scrum стал возможен благодаря тому, что в него включены простые и наглядные способы визуализации продвижения внутри спринта: доска и burndown chart, а также встречи, на которых эти представления обсуждаются и синхронизируются у всей команды. С момента появления техника работы с досками развивалась, довольно много в нее внес Kanban, который используется не только для организации работы небольшой команды, но и для больших подразделениях. И сейчас накоплено множество техник, позволяющих наглядно представить на доске ситуацию в проекте. Опыт внедрения Agile-методов показывает, что сама по себе визуализация работ на доске позволяет существенно повысить эффективность работы даже без перестройки других механизмов управления, просто за счет прозрачности ситуации для всего коллектива.
Для начала определим, что такое работа? Выполнение любого проекта, да и вообще работа любого подразделения представляет собой выполнение некоторых задач. Задачи могут быть простые, выполняемые одним человеком, или сложные, распадающиеся на подзадачи. Выполнение задачи включает в себя несколько стадий, каждую из которых может выполнять отдельный исполнитель. Одновременно в работе может быть от десятка задач для небольшой команды, до нескольких сотен для большого подразделения. И все это надо наглядно представить. Все это достаточно хорошо проработано в классическом менеджменте, и тут нет ничего нового.
Отметим, что когда проект ведет менеджер, то ему доска не обязательна. Он может пользоваться различными сложными средствами слежения за ходом проекта, такими как диаграммы Ганта или просто списками дел в Excel, тем более, что это является одни из его основных фокусов внимания. А вот требования к визуализации для командной работы много выше: за краткое время ежедневной встречи все члены команды должны включиться в контекст, понять ситуацию и оценить ее. А еще хорошо бы, чтобы решая, какую взять очередную задачу они тоже могли адекватно оценить текущую ситуацию с задачами сделать выбор.
На рисунке показано, как устроена доска. Она по вертикали разделена на несколько колонок, каждая из которых соответствует своему этапу выполнения задачи. При этом, как правило, есть разделение колонки на область задач в процессе выполнения, и выполненные, ожидающие следующего этапа. Первая колонка содержит задачи, которые еще предстоит сделать, последняя — уже выполненные. В простейшем виде колонок всего три ToDo — Doing — Done. Однако, важно, чтобы набор колонок соответствовал реальным стадиям работ. Для каждой из них должен быть понятен набор выполняемых действий, и быть сформулирован набор условий, при которых стадия считается завершенной. Хорошая практика — когда этот набор условий сформулирован как чек-лист.
На доске располагаются карточки, которые соответствуют задачам. Карточки различаются по цвету и размеру, и можно использовать дополнительные отличия. Очевидно, что надо различать отдельные задачи, задачи в составе сложных задач, и сами сложные задачи или минипроекты, в которых выполняются составляющие их простые задачи, но которые тоже путешествуют по доске, показывая интегральное состояние, и у которых тоже есть ответственный за продвижение минипроета в целом. Но полезными также являются другие различения, выделения различных потоков работ, например, отделение текущих операционных задач от работы на стратегические цели и от работы по заказам других подразделений. А еще — выделить сверхсрочные поручения от руководства компании или вызванные особыми причинами, при этом к таким карточкам можно приклеивать какие-то дополнительные символы для привлечения внимания, например, ракету. И вот здесь различие по цветам и формам позволяет, просто кинув взгляд на доску понять, что команда что-то совсем не работает на стратегические цели, а поглощена текучкой. Или что важные проекты практически стоят, а выполняются только мелкие задачи. При этом человек может оценивать на глаз, просто сравнивая количество разных карточек на доске, без пересчета, это важно.
Помимо различных форм и цветов карточек потоки различных типов задач могут быть выделены за счет горизонтальных дорожек (на схеме этого нет). Преимущество в том, что каждая дорожка, в общем случае, может иметь свой набор стадий. Зато это требует больше места, а в случае, когда потоки неоднородны по мощности — еще и является сильно не оптимальным. Поэтому обычно применяется комбинация обоих вариантов.
Как понять, какие именно стадии, дорожки и типы карточек должны быть у вас на доске? Казалось бы, все просто: возьми регламент и выпиши из него этапы работ. Однако, практика показывает, что реальные потоки задач оказываются достаточно разнородны, при обработке возникают различные особые случаи, которые скрыты внутри фазы. А для того, чтобы доска могла служить рабочим инструментом, она должна адекватно отражать ситуацию. Поэтому доска требует отдельного проектирования, которое не является тривиальной задачей. При внедрении Kanban проектирование доски является составной частью процесса STATIK (Systems Thinking Approach to Introducing Kanban), в ходе которого анализируют реальный поток задач, выделяют их фазы и классы обслуживания. Часто при этом выясняют много интересного о том, как же на самом деле сотрудниками выполняется работа. Впрочем, доски не отливаются в чугуне, поэтому могут быть доработаны позднее. На карточке должно быть написан код задачи, если есть привязка к электронной системе ведения дел, если она есть, и ее краткое название. Важно, чтобы содержание задачи было опознаваемо по названию большинством сотрудников, чтобы за содержанием не требовалось заглядывать в отдельную систему, а люди и так понимали, о чем идет речь.
У каждой задачи есть ответственный, и он должен быть на карточке. И хороший современный прием состоит в том, чтобы указывать ответственного не инициалами или именами-фамилиями, а с помощью опознаваемых фотографий, достаточно крупных, чтобы при взгляде на доску можно было узнать человека. Фотографии печатаются заранее, а когда человек берет задачу он ее просто прикрепляет степлером. Не аватары или мелкие изображения, а именно фото лица — дело в том, что в мозгу у нас есть отдельная система узнавания лиц, которая работает весьма эффективно. И если ее задействовать, то эффективность работы с доской сильно повышается. Появляется возможность простым взглядом на доску увидеть, кто из сотрудников сильно загружен, может быть перегружен, а кто, наоборот, загружен мало. А по фото в области сделанных задач примерно видны сравнительные результаты.
При анализе ситуации всегда важно представлять, что какая-то задача задержалась на определенной стадии дольше обычного. И есть очень простой прием, как это сделать наглядным: каждой колонке сопоставляем свой цветной маркер и регулярно, например, ежедневно для коротких итераций или еженедельно для досок, используемых для более долговременных задач, ставим на карточки точки маркером нужного цвета. Число точек показывает, как долго задача находилась в определенной стадии. Как и в случае с фотографиями важно, чтобы точки были видны, когда окидываешь доску взглядом.
Еще один прием связан с задержками, которые возникают при выполнении задачи, если они не зависят от исполнителя, а связаны с внешними взаимодействиями. Хороший способ — клеить на карточку стикер, где фиксировать причину задержки и ожидаемое время ответа. И, естественно, использовать стикеры различного цвета и формы визуального выделения, а также ставить точки на них, а не только на карточку.
Различные примеры досок легко ищутся и интересующиеся наверняка видели много разных вариантов. Поэтому я хочу привести пример большой доски — доску одного из департаментов Центрального Банка, о которой в докладе на AgileDays-2018 «Банк России: знать путь и пройти его — не одно и то же» рассказывали Светлана Иванова, Дарья Корнеева и Николай Арапов.

Я не только слушал доклад, но и был в этом подразделении на экскурсии и доска реально впечатляет — 8 метров, она занимает всю стену в переговорной перед кабинетом директора департамента, на нее вынесено около 150 важных задач департамента, при том, что в отделах департамента есть собственные доски. И в ней как раз использованы приемы, о которых я писал выше. Как говорили в докладе, доски становятся «информационными радиаторами», излучая информацию на все подразделение, и давая представление о прогрессе работы. Люди учатся общаться, просить и предлагать помощь. И приемы визуализации тоже этому способствуют. Например, сотрудники оценивают, что операционных задач слишком много, а задач из проектов на стратегические цели маловато и они медленно двигаются. Или, видя на доске, что какая-то задача чересчур зависла на согласовании с внешним отделом, предлагают ответственному обходные пути для ускорения процесса, которые есть в каждой крупной организации. И в целом они сами были удивлены значительностью того эффекта, который принесла визуализация. Доска вовлекает людей в работу отдела в подразделения, побуждает не ограничиваться только своими задачами, а задумываться о работе в целом.
Стоит сказать про обсуждение статуса работ у доски. Частая практика состоит в том, что члены команды по очереди рассказывают, какими задачами они занимались, чего достигли и какие препятствия. При этом перемещение по доске идет в произвольном порядке. А хорошей практикой является обсуждение от задач, а не от людей, начиная от тех, которые находятся справа, то есть дальше других продвинулись по доске. Потому что продвижение по доске означает, что в задачу уже вложено много работы, и потому она более важна для завершения. Заметим, кстати, что по этой причине задача на доске не возвращается на предыдущие стадии, даже если были обнаружены недоделки, например, если при тестировании выявлены ошибки разработки, или при финальном согласовании договора с клиентом были обнаружены проблемы юридического характера, которые юристы должны были решить ранее. Не задача возвращается на предыдущую стадию, а компетентный специалист вызывается для помощи в решении проблем. и это для него более приоритетная работа. В целом важно, чтобы обсуждение у доски для новой команды вели опытные люди, которые умеют читать доску и понимают работу с ней и показывают другим. Тогда у людей, участвующих в обсуждении, через некоторое время возникает эмпатия к доске.
Еще один важный такт обсуждения — это снятие с доски завершенных задач. Это не должно быть технической процедурой, это повод отпраздновать завершение работы и вспомнить, что было сделано. Это может быть по-разному включено в процесс, но позитивный праздник — важен. Но и техническую часть тоже не следует забывать — в случае использовании физической доски это момент обработки метрик по сделанным задачам.
Я не сказал про еще один важный элемент, который был на схеме — это WIP-лимиты, ограничивающие Work In Progress — незавершенную работу. По понятной причине — это достаточно продвинутая техника, которую стоит вводить не на первом шаге, постепенно и экспериментально проверять эффекты, которые приносит изменение лимитов. Техника WIP-лимитов основана на теории ограничений (TOC) Голдратта. Важно, что в случае неоднородного потока работ, которым характеризуется IT-разработка и другие задачи умственного труда точки ограничений могут перемещаться по стадиям обработки, поэтому и есть смысл ставить лимиты на все колонки.
Механизм действия лимитов следующий. Как мы помним, колонка стадии делится на части, где отражаются выполняемые задачи, и уже выполненные, готовые к переходу дальше. Если в какой-то стадии возникло бутылочное горлышко, то на предыдущей колонке задачи накапливаются в состоянии «выполнено». При этом лимит — общий, и потому освободившиеся сотрудники не могут взять очередную задачу. И это служит сигналом о том, что надо перестать забирать в работу все новые задачи, а надо коллективными усилиями начать разбирать бутылочное горло. Да, это может провести к простою сотрудников, но теория ограничений четко говорит, что даже простой лучше, чем увеличение незавершенной работы, так как в целом это ведет к повышению пропускной способности системы. Правда, надо отметить, что такой простой часто негативно воспринимается и в том числе может негативно влиять на метрики и KPI, если они спроектированы традиционным образом. Кстати, это — известная проблема применения теории ограничений, и правильный подход — изменить соответствующие метрики, если вам интересны детали, то об этом есть книга: Томас Корбет «Учёт прохода. Управленческий учет по теории ограничений», оригинальное название — «Throughput accounting» (есть русский конспект).
Отметим, что WIP-лимиты можно накладывать не только на колонки, но и на определенные классы задач, например, на срочные поручения руководителей высокого уровня. В уже упоминавшемся кейсе департамента Банка России они решили, что срочных поручений не может выполняться больше пяти одновременно, а чтобы их отличать от остальных клеили на карточку ракету. Может показаться, что это наивно, дескать, нельзя же отказать высокому руководителю, когда он дает поручение потому, что у вас, мол, установлен WIP-лимит. Но на самом деле это работает, просто надо весте коммуникацию по-другому: когда вам дают задачу вспомнить о тех, что уже в работе, напомнить о них руководителю, и попросить позиционировать относительно них. Если ее можно выполнить после завершения других, то она получается и не сильно срочная, а если новая задача действительно срочная, то он сам укажет, чем надо пожертвовать ради нее. Просто он вполне может не помнить, какие задачи уже в работе.
Ну и в заключении поговорим о том, какую доску следует использовать — физическую или электронную. На самом деле, ограничение тут единственное: если у вас распределенная команда, то физическую доску использовать невозможно. У каждого варианта есть свои плюсы и минусы. Опыт показывает Физическая доска гораздо лучше для команды, у которой вообще не было навыков работы с досками и таск-трекером, она способствует коллективным обсуждениям и коммуникации в команде, и к ней быстрее возникает эмпатия. А еще физические доски обладают гораздо большей вместимостью, приведенная в качестве примера доска в центральном банке в электронном варианте была бы невозможна. С другой стороны, использование только физической доски без электронной и таск-трекера не позволяет работать с метриками на длинных временных горизонтах. В целом опыт развития Agile говорит об одном: это решение должна принимать сама команда. При этом, хотя использование таск-трекера в IT является стандартом, есть случаи использования физической доски с поддержкой синхронности различными методами: первичным источником при этом может быть как доска, так и таск-трекер. Кстати, в Банке России наряду с физической доской был список задач, и тоже проводилась синхронизация, это входило в обязанности отдельного сотрудника. Таск-трекеров существует громадное количество, и большинство из современных умеют представлять задачи в виде досок. И есть много обзоров этих инструментов, которые, впрочем, как обычно не дают однозначного ответа. Так что выбирать вам самим.

Итерации Scrum — целостная схема, а не прикольная картинка
Я хочу начать со схем итерационного процесса Scrum. Собственно, наличие такой схемы, в которой собраны связанные и дополняющие друг друга элементы, обеспечивающие целостность процесса, и делает Scrum фреймворком, а не просто методом организации работы. Схема показывает, как функционально следует устроить процесс, чтобы он работал, чтобы его элементы взаимодействовали между собой и в комплексе обеспечивали результат. Функционально, а не процедурно — наполнение конкретных функций может быть различно, оно сильнее зависит от условий и содержания конкретного проекта или потока работ, и его надо адаптировать. А вот рассказывают схему часто в сильно упрощенном варианте, делая фокус не на функциях элементов схемы, а на процедурах, которые могут их обеспечить в простом случае. Вред понятен: люди видят, что конкретную процедуру в их проекте применить нельзя, и не понимая функциональной схемы, заменяют упрощенным вариантом и в реализации получаются функциональные дыры, в результате «Scrum не работает». Так вот, не работает не Scrum, а его плохая адаптация. И потому дальше я буду подробно останавливаться на функциях элементов и вариантах адаптации.
Отметим, что создатель Scrum Джеф Сазерленд в своей книге «Scrum — революционный метод управления проектами» пишет о том, что он был скептически настроен по применению Scrum за пределами IT, потому что полагал, что фреймворк сильно нагружен IT-спецификой. Однако, по мере того, как его пробовали использовать и достигали успеха, его скепсис развеялся, и в книге он приводит различные примеры использования. Кстати, я рекомендую эту книгу всем, кто хочет понять дух и культуру Scrum и Agile в целом. При этом Джеф описывает сам фреймворк, логику и историю его создания, и дает множество кейсов применения. А еще книга достаточно очищена от IT-специфики, так что может быть обобщенным руководством. Кстати, говорят, что это — одна из двух книг, прочитав которые Герман Греф проникся новым менеджментом. Вторая «Открывая организации будущего» Фредерика Лалу.
А вторая книга, которую я хочу порекомендовать — Хенрик Книберг «Скрам и XP: заметки с передовой», в оригинале «Scrum and XP from the Trenches». Русский перевод был сделан энтузиастами и долгое время лежал на infoq.com, потом был оттуда убран, но в сети остался, например, здесь. а английский там доступен уже во втором издании. Книга — про IT, очень популярна и в свое время именно по ней изучали Agile-методы. Я тоже впервые детально познакомился со Scrum именно по ней в 2007, а когда в 2011 Книберг приезжал на AgileDays, то проходил у него тренинг, заметки и конспект сохранились у меня на сайте. Книга актуальна не только для IT-шников, но и для заказчиков софта, особенно в корпорациях, она помогает понять логику разработки и наладить сотрудничество. Отмечу, что и Сазерленд и Книберг — не спикеры или тренеры, они ведут реальные проекты, в том числе разбираются и спасают проблемные проекты, когда критерием успеха является успех самого проекта. Поэтому их книги, выступления и тренинги так интересны.
Перед тем, как начать разбор схему Scrum я хочу сказать несколько слов о том, почему распространены именно упрощенные рассказы. Дело в том, что задачей спикера часто является не показ сложной функциональной схемы, а вовлечение слушателей в Scrum. И это может быть уместно в ситуации рассказа, например, на ознакомительном тренинге или докладе. Предполагается, что адаптацию при внедрении слушатели будут делать не самостоятельно, ее сделает опытный Agile-коуч, сопровождающий внедрение, который понимает функциональное устройство. Ну а потом и участники процесса сами разберутся на собственном опыте. И вот, для вовлечения рассказ ведут на плюшевых схемах, несколько из которых я привел на рисунке. И все они несут сообщение «Scrum — это просто, весело и прикольно», хотя достигается это разными методами.
Данная схема предельно упрощена. В свое время она была очень популярна даже в более простом виде, без ролей. Впрочем, в официальных источниках я ее не нашел, но в инете она распространена очень широко. А роли являются позднейшей чужеродной вставкой. Визуально несет только одно сообщение «все очень просто».
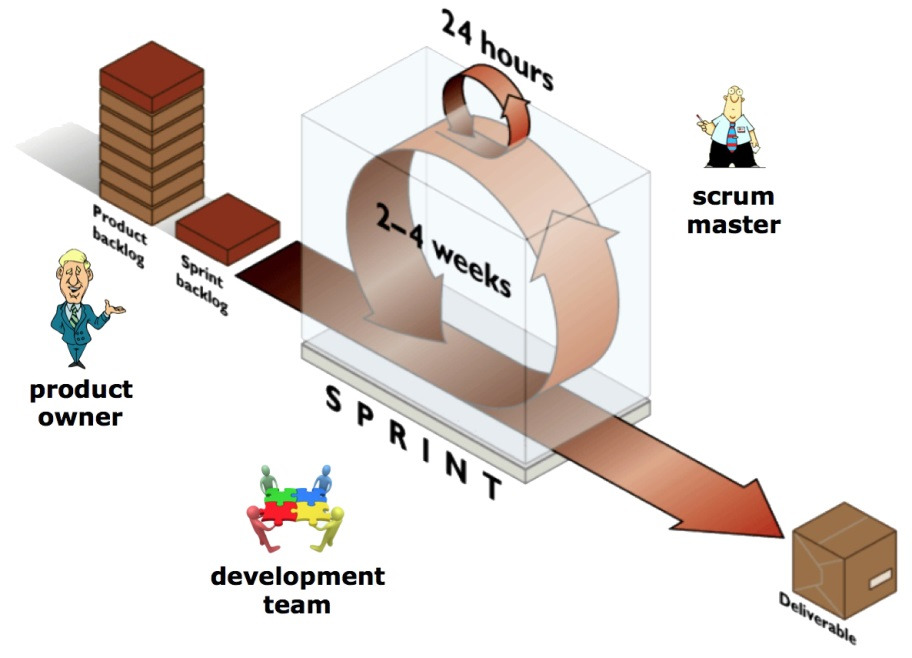
Далее визуальный ряд совершенно не дает разобраться в содержании: внимание сосредотачивается на красивых персонажах, и к тому же все надписи сделаны мелким фонтом и почти не различимы. Однако, отмечу, что формально схема очень точная, все элементы — есть, и если ее рассматривать внимательно, то она — читаема. И в надписях есть самая важная для формального менеджера информация — не о содержании элементов и, конечно, не о функциях, а о часах, которые следует потратить
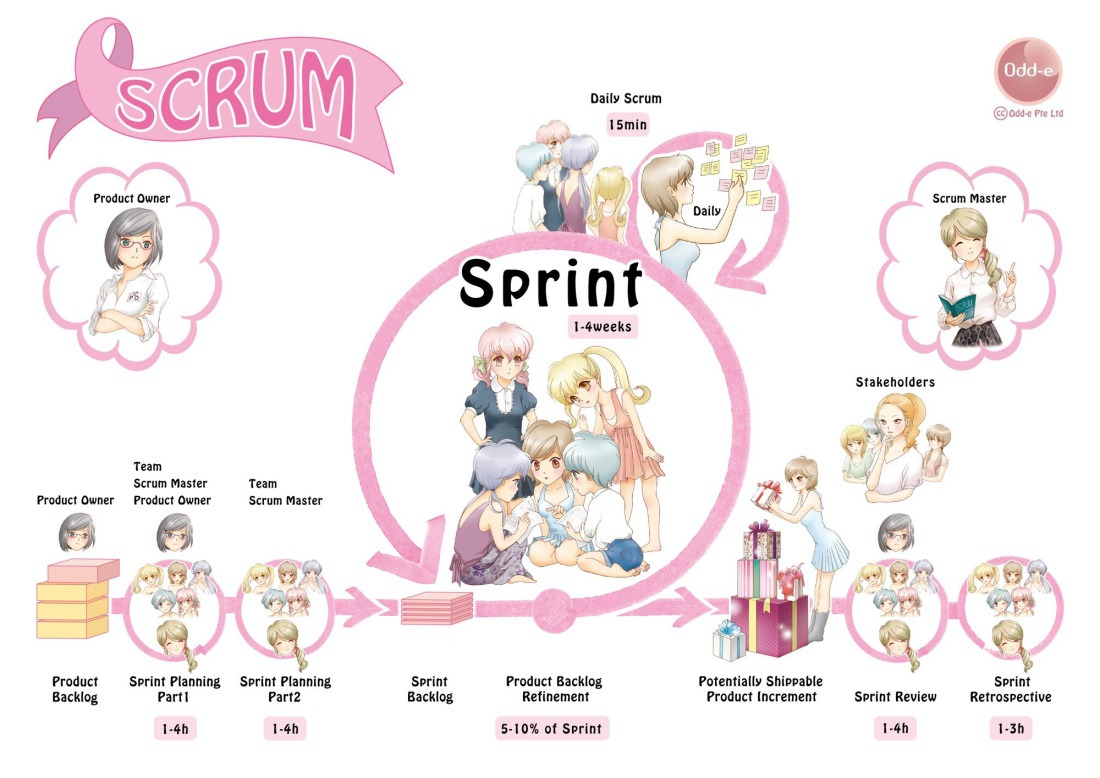
Ну а на последней схеме авторы поместили много визуальных элементов, перешли к трехмерной конструкции и решили практически отказаться от надписей, поэтому прочитать ее невозможно, если не знать содержания.
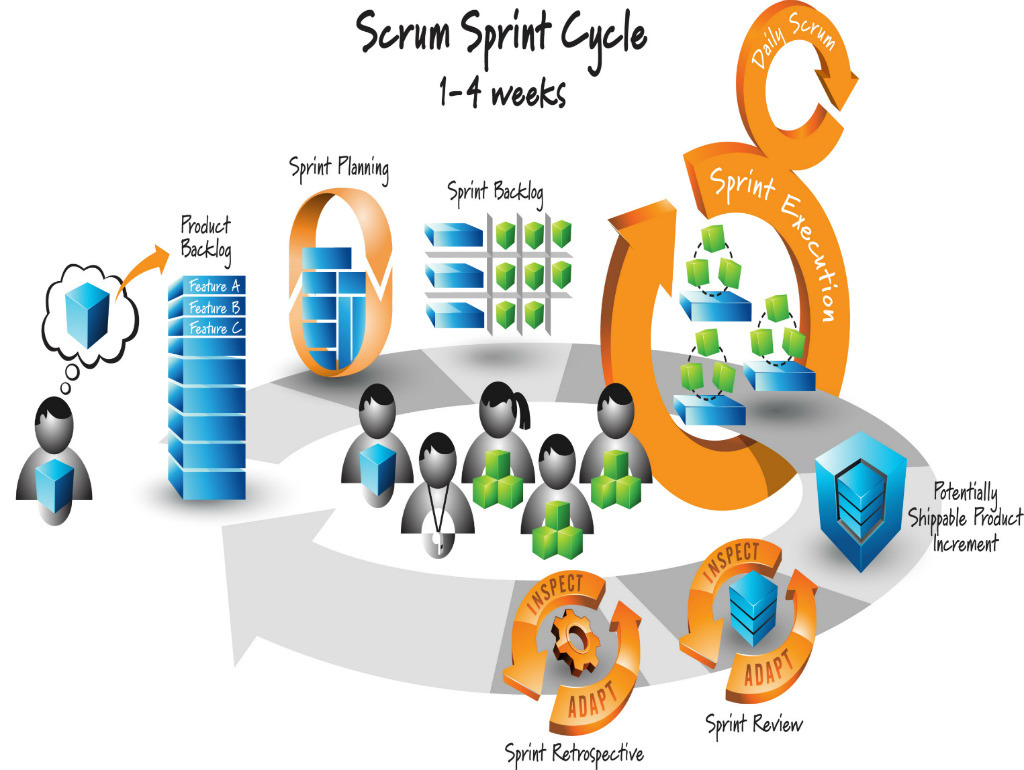

Схема Scrum — деление на спринты и подготовка к ним
Ну а теперь перейдем к устройству фреймворка Scrum. Для начала отметим, что Scrum — нормированный процесс, и он описан в Scrum Guide. Он описан очень аккуратно: в нем четко определены функции элементов, и рекомендуется их процедурное содержание. При этом предполагается, что возможна и даже необходима адаптация для конкретного проекта. Однако, надо понимать, что с некоторого момента адаптации становятся настолько большими, что вы уже не можете говорить «мы работаем по Scrum», а должны говорить «у нас собственный процесс на основе Scrum». Об этом часто забывают, и в результате Скрамом сейчас по факту называют самые различные вещи.
Однако, в своем рассказе не буду строго следовать Scrum Guide. Основная причина в том, что он по-прежнему в значительной мере наполнен спецификой IT-проектов, в то время как Scrum применяется гораздо шире. Да и в самом IT характер проектов значительно изменяется. Я не выверял текст по Scrum Guide.
Я тут хочу оговориться, что текст далее в значительной мере посвящен IT. Сделано это не только потому, что, я думаю, много читателей будет из IT и им это интересно, но и потому, что если вы будете переносить процесс в другие отрасли и другие виды деятельности, то следует понимать те изменения, которые в IT потребовались для успешной реализации — вам придется делать аналогичные адаптации или смириться с недостаточной эффективностью процесса, или отказаться от него. Это касается не только Scrum, но и комбинированных процессов. И несмотря на все эти оговорки, можно сказать, что применение Scrum за пределами IT является более эффективным, чем регулярный менеджмент, и это дает компаниям преимущество — что и объясняет интерес к применению.
Начнем с сокращенной схемы.
Итерации: создаем ценность в каждой, а не просто квантуем поток
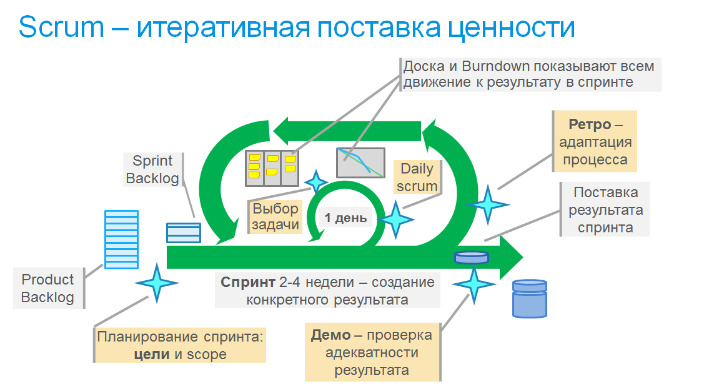
Основное изменение, которое принес Scrum в проектную работу — это деление потока работ на итерации, который и представлен на схеме. Рекомендуемая продолжительность итерации 2—4 недели, при том, что на практике встречаются и недельные итерации, а вот большая продолжительность не является эффективной, происходит размывание фокуса. Предполагается, что у нас есть список задач, которые следует выполнить для достижения цели — Product Backlog, и задачи там упорядочены по важности и приоритетам. О том, каким образом наполняется этот список, мы поговорим дальше. Перед стартом итерации из этого списка выбираются задачи, которые планируется выполнить в Sprint Backlog. Но, что важно, мы не просто выбираем некоторое количество задач из начала списка. Дело в том, что в конце итерации должен получиться целостное приращение к продукту, несущее ценность потребителю и пригодное к использованию. Собственно, в этом состояла основная революция: при традиционном проектном подходе команда работала несколько месяцев и продукт в понятном для потребителя и пригодном для использования виде собирался только в самом конце, а о пригодности для потребителя промежуточных сборок никто не заботился, даже если применялись практики continuous integration и проверка работоспособности сделанного.
Важная разница: пригодный для потребителя или в принципе работающий. Пригодность для использования означает выполнение некоторого полного цикла задач. С этим многие сталкивались при ремонте в квартире или строительстве загородного дома: для жизни требуются некоторый набор функций: место, где спать, место для еды с возможностью ее минимально приготовить, места для личной гигиены и для хранения личных вещей. И последовательность ремонта существенно отличается в зависимости от того, надо ли в доме жить. Когда не надо — сильно проще, делаем последовательно. В общем-то с софтом тоже самое. Зачем же делать сложнее? Засада в том, что когда мы потом приходим в построенный дом, то могут выясниться очень неприятные вещи, например, с отсутствием розеток в нужных местах. И в софте они тоже выясняются. И если в случае дома это обеспечивается грамотным проектированием и представлением проекта, то, как показывает опыт разработки софта, адекватно оценить это по проекту — почти невозможно. Пользователям нужен работающий софт — приложение, которое можно запустить, понажимать на кнопки, попробовать решить в нем свои задачи, и только в этом случае они могут дать адекватную обратную связь о пригодности приложения.
Переход к инкрементальному созданию приложения в IT потребовало кардинального пересмотра способов работы с требованиями и проектирования приложения. Появились новые форматы, такие как user story, каждая из которых описывала ценную для пользователя функциональность и была относительно мала, так, что можно было легко ими маневрировать при планировании, в отличие от цельных проектов большого функционала, с которым работали в прошлом. И первая версия Scrum Guide (можно скачать здесь) рекомендовала использовать именно их в качестве элементов бэклога. По мере распространения Scrum другие форматы ведения требований и проектирования тоже адаптировались. Например, Ивар Якобсон адаптировал формат use case и появился Use Case 2.0, пригодный для инкрементальной реализации. Ссылка ведет на сайт Ивара, где книга бесплатно доступна после регистрации, а здесь мой конспект мастер-класса Ивара о них в 2013. Так что сейчас для элементов бэклога могут применяться разные варианты.
Отметим, что далеко не в любых проектах можно перейти к инкрементальной реализации с поставкой ценности. Понятным примером являются строительные проекты: мост или здание надо построить целиком и запустить в эксплуатацию. Другим примером является организация конференции или другого мероприятия — тут есть финальный релиз и нет промежуточных этапов, приносящих ценность. Однако, есть большая зона, где преобразование возможно в том или ином объеме. И надо отметить, что хорошо поддаются преобразованию проекты НИОКР. Например, концерн Калашникова на одной из встреч, что они применяют Scrum для разработки новых видов оружия. При этом за две недели получается сделать в железе некоторый очередной прототип, демонстрация которого позволяет увидеть ошибки проектирования и неверные пути, которые при традиционном способе были бы проявлены только через полгода, и это дает большую экономию и средств и времени. На AgileBusiness-2018 применении Scrum для разработки новых материалов рассказывала Северсталь (мой конспект), а для создания коллекций одежды — 12Storeez (видео), можно найти много других примеров. Отмечу также, что Scrum может применяться и для организации работы в случае, когда существенную часть работ вообще нельзя запланировать. Например, на AgileDays-2018 Марина Симонова (Marina Alex) рассказывала о применении Scrum в сети стоматологических клиник (видео), в которых работа состоит в обслуживании пациентов, и не может быть запланирована. В этом случае спринты Scrum использовались только для задания еженедельного ритма работы. Но при этом сознательно был выбран именно фреймворк Scrum для того, чтобы путем резких изменений организации работы и переходе к командам обеспечить изменение культуры в коллективе и наладить сотрудничество между врачами, медсестрами и немедицинским персоналом, которые обычно в медицине сильно разделены. Там были образованы именно смешанные команды, включающие все роли.
Таким образом, далеко не всегда переход к итеративной работе Scrum означает поставку конечному потребителю в конце каждой итерации из-за особенностей бизнеса. Однако, отступая от этого, вы повышаете риски того, что создаваемая ценность окажется ложной, и, как следствие, работа будет бесполезной. И принимать меры для компенсации этого риска.

Планирование — цели и контракт на каждый спринт
А теперь перейдем к деталям схемы. Каждая итерация начинается с Планирования. Это встреча, на которой определяются цели на спринт и scope работ. Цель фокусирует работу спринта и в идеале формулирует ту ценность для потребителя, которая будет в рамках спринта создана. Но может задавать и вектор движения, по которому намечается значительное продвижение. Вообще, говоря, про цель следует иметь ввиду все, что сказано выше про разные варианты итераций Scrum, обусловленные особенностями деятельности.
Далее происходит выбор задач для достижения целей. При правильной работе с бэклогом именно эти задачи будут самыми приоритетными в нем, или, во всяком случае, находится рядом с его началом. И они обычно достаточно крупные, поэтому начинать стоит именно с них, чтобы посмотреть, помещаются ли они в спринт и можно ли достаточно уверенно говорить о том, что цели спринта будут достигнуты. Помимо этих задач в начале бэклога обычно находятся задачи, связанные со срочными доработками или с устранением замечаний по ранее реализованному функционалу, полученными на Демо (Sprint Review). Если их относительно немного и они помещаются в спринт вместе с основными, то они могут быть включены. Однако, если срочных задач и замечаний достаточно много, то возникает вопрос выбора: сократить количество основных задач или отложить срочные задачи? Ответ — основной scope сокращать нельзя, цель спринта должна быть руководством к действию, а не декларацией. А если срочных задач накопилось действительно много, сделайте отдельный спринт, целью которого будет как раз выполнение срочных задач и устранение замечаний. Только ее тоже надо сформулировать сфокусировано, например, «дорабатываем систему, чтобы отдел Z стал счастлив». Третья категория задач, которые должны попасть в спринта — это задачи для подготовки к последующим спринтам. Эти задачи подробнее обсуждаются в следующем разделе, в котором речь идет о подготовке бэклога. И, наконец, следует рассказать о четвертой категории задач и связанных с ними дополнительными целями спринта. Это задачи, направленные на повышение эффективности самого процесса работы команды или снижение его рисков. Типичным примером является увеличение bus factor — уникальных специалистов команды, болезнь которых или отсутствие по другим причинам может остановить работу команды полностью или над конкретными видами задач. Название, собственно, это и объясняет: речь идет о числе членов команды, попадание которых под автобус остановит проект. Близкой к этому является задача устранения бутылочных горлышек, возникающих, если в спринте оказываются задачи определенного типа, по которым у команды компетенции недостаточны или сосредоточены у одного человека. Если такая ситуация зафиксирована и устранение Product Owner и члены команды признали важным, то она может быть включена как дополнительная цель в какой-либо спринт со средствами решения. Средства решения могут быть различны — обучение сотрудников, выполнение каких-то исследований и прототипов, или просто выполнение задач определенного типа не опытными, имеющими необходимые компетенции, а теми, кто таких компетенций не имеет. Цель должна звучать конкретно, например «Петя учит Васю делать отчеты, чтобы снизить bus factor», и, естественно, в спринте должны быть задачи по отчетам. Дальше такая цель учитывается внутри спринта, а на планировании оцениваются и закладываются накладные расходы, связанные с ее достижением.
В четвертую категорию относятся также другие задачи по улучшениям, которые были сформулированы на ретро. Они могут касаться как перестройки процессов внутри команды, например, внутренней автоматизации команды, снижающей операционную трудоемкость, так и взаимодействия со смежными подразделениями. Важно, чтобы было не просто запланировано выполнение определенной задачи, а было сформулировано ожидаемое улучшение каких-либо наблюдаемых показателей как критерий успеха.
Описанные категории задач свойственна не только IT, но и другим областям, хотя наполнение может сильно различаться. Например, в IT-разработки целью спринта может быть реализация целостного набора функций, ориентированного на определенные группы пользователей, которые привлекут их к продукту, называемых фичами (от feature, это уже есть в словарях!) или эпиками (от epic story, а этого в словарях еще нет). А для отдела продаж целью может быть реализация определенной промоакции, сфокусированной на некоторой группе потребителей и сопровождаемая массовыми предложениями, или фокусное продвижение на определенном рынке, или работа над заключением определенного крупного контракта.
Срочные задачи в IT связаны с потребностями пользователей, которые уже пользуются системой, особенно если они только начинают это делать потому что функционал был сделан в предыдущем спринте, и есть риски разочарования, а для отдела продаж — это сопровождение клиентов, привлеченных на предыдущем такте, которые так же не должны разочароваться.
В IT для того, чтобы довести к планированию задачи до нужной подробности могут быть нужны дополнительные обсуждения с техническими специалистами, исследование технологий, подготовка легких прототипов, показываемых стейкхолдерам или что-то еще. А для отдела продаж — предварительные исследования рынков, связанные с предполагаемыми целями 1—2 будущих спринтов, или предварительные переговоры по поводу каких-то будущих рекламных компаний и поиск контрагентов для реализации. Аналогично и в других отраслях. Задачи обучения членов команды или улучшений процесса тоже. естественно, могут ставиться в любой области.
Scrum — ежедневная работа внутри спринта
Мы обсудили изменения, которые потребовал переход к инкрементальной поставки ценности, и процедуру планирования, начинающую спринт. А эта посвящена организации работы внутри спринта. Казалось бы, что об этом писать? Делаешь себе задачи и делаешь, и получаешь результат. На самом деле, там тоже много интересных особенностей, обеспечивающих успех метода.
Ежедневное выполнение задач
После запуска спринта идет период ежедневного выполнения задач, в котором люди работают самостоятельно и автономно. Средством организации является доска Scrum, на которую помещены задачи. Сотрудник берет себе задачу, помечает на ней себя как ответственного и перемещает ее на доске в колонку, соответствующую выполняемым задачам, и затем ее выполняет. Колонок с выполняемыми задачами на доске может быть несколько, при этом в зависимости от разделения труда в команде, сотрудник может выполнять несколько этапов, или передавать задачу другим сотрудникам. Передача тоже происходит посредством доски, а не в прямой коммуникации: задача перемещается в колонку готовности к следующей фазе. И так — пока задача не окажется в колонке сделанных. О способах организации доски я подробно писал ранее, в главе «Доска — визуализация текущего состояния работы» и здесь останавливаться не буду.
Хочу подчеркнуть, что такая организация работы — через доску, а не путем прямой коммуникации представляет собой один из предохранителей против возврата к классическому менеджменту, встроенных в Scrum. Он физически устраняет место, в котором сотруднику могут дать прямое поручение, все коммуникации инициируются самими сотрудниками.
Возникает вопрос: а какую задачу член команды должен взять с доски, когда он закончил предыдущую? Ответ: ту, взятие им которой наилучшим образом продвинет спринт к завершению. Это вопрос личного выбора, при котором он учитывает текущую ситуацию, представленную на доски, свои собственные компетенции и компетенции других членов команды. При этом, естественно могут быть приняты определенные правила, которые призваны облегчить выбор, сделать его быстрым. Например, правило выбирать самую важную задачу. Но правила могут быть и более сложными, например, в начале спринта приоритет может отдаваться задачам, которые на планировании оценили как наиболее рискованные по реализации, в том числе длительным, а в конце спринта, наоборот, небольшим задачам, чтобы уменьшить количество незавершенных задач. Могут быть правила, по которым при скоплении на поздних этапах исполнения часть членов команды переключались на них. То есть, если говорить об IT разработчики начинали заниматься тестированием, если тестировщики вдруг не успевают. Особую остроту это приобретает, если используются WIP- лимиты. Могут быть и другие правила.
Срочные задачи
Как правило, sprint backlog фиксируется при планировании. Однако, в конкретных командах может быть необходимо уметь включать в спринт дополнительные задачи, например, если команда не только создает новый функционал, но и устраняет ошибки в старом, или обрабатывает какие-то срочные обращения клиентов или поручения руководства. Если срочные задачи появляются регулярно, то на такие задачи обычно выделяется резерв мощности команды при планировании спринта. Сгорание этого резерва можно отдельно рисовать на Burndown Chart снизу-вверх. Управления срочными задачами также желательно вести через доску, а не прямыми поручениями. Задача может быть просто повешена на доску, если ее содержание ясно. Если требуются дополнительные пояснения, то хорошая практика — подождать до очередного Daily Scrum для информации всей команде.
Если задача имеет большой объем, то с Product Owner обсуждают не только ее содержание, но и изъятие соответствующего объема запланированных задач из числа тех, которые еще не начали выполнение. При этом важно, чтобы эти изменения не нарушили достижения целей спринта. Если изменения столь велики, что цель спринта не достигается, то имеет смысл текущий спринт прервать, и начать новый спринт, восстановив осмысленность движения.
Нет прерываниям!
Начатое выполнение задачи не прерывается. Предполагается, что они достаточно малы, чтобы любые срочные задачи могли подождать, пока кто-нибудь завершит свою и увидит на доске новую. Понятно, что это — идеальная картина. Реально коммуникации не запрещены, в каких-либо срочных случаях сотрудника можно и нужно отвлечь, в том числе если при выполнении очередного этапа обнаружились проблемы в ранее сделанном — тот, кто делал может быть призван на помощь. Однако, запрету отвлекать есть важная причина, характерная для любых задач умственного труда: их выполнение требует погружения и сосредоточения, и нарушение этого представляет собой существенные накладные расходы. По опыту, задача на 2—3 часа требует около получаса погружения, поэтому если исполнителя пару раз отвлекли, то время выполнения возросло в полтора раза. Эти цифры — из моего опыта, но я слышал аналогичные цифры в разных докладах на конференциях, а быстрый поиск выдал, например, эту статью «Почему, отвлекаясь от работы на 2 минуты, мы тратим все 25», в которой приведена близкая цифра со ссылкой на исследования.
Если члены команды видят реальные потери производительности из-за частых отвлечений, это следует обсудить на ретроспективе и договориться о правилах работы. Отметим, кстати, этот прием: если кто-то увидел проблему, он начинает немедленно возмущаться и пытаться решить, а фиксирует возникшее напряжение. А потом высказывает его на соответствующей встрече, в данном случае это ретроспектива, а в случае острой проблемы — daily scrum. А результатом обсуждения чаще является не просто выраженное намерение исправиться, похожее на детское «я больше не буду» или «я буду стараться», а правило, учитывающее разные классы ситуаций: «отвлекать можно в случаях 1-2-3, а в остальных не надо», или «отвлекать можно, если отложенное решение несет такие-то риски».

Daily Scrum
Хотя работа каждого члена команды идет автономно, необходима синхронизация движения. Для этого служит ежедневная встреча — Daily Scrum. В свое время он назывался StandUp meeting, потому что рекомендовалось проводить его стоя вокруг доски. Эта рекомендация по-прежнему актуальна, если команда сидит вместе, но в случае распределенной команды это невозможно. Отметим, сидеть в одном помещении, лучше — отдельном для команды также крайне важно. А проведение митинга стоя, а не сидя способствует, во-первых, тому, чтобы члены команды оторвались от своей текущей работы, а, во-вторых, не затягивали митинг. Это — статус, а не обсуждение работы.
Если на встрече выяснилось, что какая-либо задача требует отдельного обсуждения, то надо зафиксировать, и далее ответственный за задачу должен его отдельно организовать, например, сразу после митинга. Превращение Daily Scrum в обсуждение задач, а не статус — наиболее распространенная ошибка. Рекомендация продолжительности для Daily Scrum — 15 минут, и если команда систематически превышает его, то стоит подумать о причинах и способах сокращения. Что касается времени проведения, то его команда выбирает самостоятельно, с учетом индивидуального расписания работы ее членов. В те времена, когда все начинали работу одновременно, следуя корпоративным традициям хорошим вариантом было утро сразу после начала рабочего дня, но эти времена ушли в прошлое. Может быть выбрано время перед или после обеда, если команда обедает примерно в одно время. На Daily Scrum важно участие всех членов команды, и даже если по каким-то причинам они не могут быть лично, желательно дистанционное участие. Процедура Daily Scrum следующая: люди говорят о том, что было сделано накануне с прошлой встречи, о том, чем предполагают заниматься, и о том, какие есть препятствия для движения вперед. Коротко. Как легко догадаться, при 15 минутах на команду из 7 человек каждому будет не более 2 минут. Поэтому препятствия — фиксируются и назначаются нужные обсуждения. В каком порядке говорят люди? Есть два подхода, наиболее простой — говорить по кругу. Другой порядок — на основе расположения задач на доске, начиная от крайне правой колонки, поскольку чем задача продвинулась дальше по этапам, тем важнее ее завершение.
Кроме статуса по текущим задачам Product Owner информирует команду о срочных задачах, включенных в спринт, и других важных изменениях. Но это не должно существенно увеличивать размер Daily Scrum, если требуется длительное обсуждение, то о его времени надо отдельно договориться.
Доска с задачами должна быть актуальна в любой момент для того, чтобы член команды мог выбрать очередную задачу. Но это относится к основной доске. Если команда использует электронную и физическую доску одновременно, или физическую доску и таск-трекер, то Daily Scrum является также точкой синхронизации досок, и по его итогам принято обновлять Burndown Chart. Процедура здесь произвольна, это вопрос самоорганизации команды, но забывать об этом не следует.
Завершение спринта в Scrum — демо и ретро
Продолжим рассмотрение схемы скрам и поговорим про завершение спринта — Демо, оно жа Sprint Review и Ретроспективу.
Демо — оцениваем результат
Назначение Демо — показ результатов, достигнутых командой, и их оценка стейкхолдерами. Именно получение оценки от стейкхолдеров и является основной функцией демо: соответствует ли это их ожиданиям, решает ли поставленные задачи и приносит ли ценность. И официальное название в Scrum Guide — Sprint Review это подчеркивает. Но термин «Демо» является устоявшимся в сообществе, гораздо более коротким и я предпочитаю использовать именно его, тем более, что исторически именно это название я узнал первым, прочитав в 2007 книгу Хенрика Книберга «Скрам и XP: заметки с передовой», которую уже упоминал ранее.
Возникает вопрос: а почему, собственно нужна такая обратная связь? Ведь задачи в процессе исполнения перемещались по доске, каждая смена статуса имела свой чек-лист завершения, включая, естественно, критерий сделанной задачи, Definition of Done (DoD)? Разве этого недостаточно? Ответ — нет, недостаточно. Если бы ценность задачи можно было бы обеспечить выполнением чек-листа, то никакой бы Agile был не нужен, с организацией IT-проектов хорошо бы справились методы классического менеджмента. Проблема состоит в высокой сложности социотехнических систем, в результате чего все представления о необходимых функциях и о работе пользователей — не более чем гипотезы, подлежащие проверки. А на бытовом уровне эта ситуация хорошо описывается словами «заказчик сам не знает, чего он хочет». Именно поэтому разработанный софт требует постоянной проверки: несет ли он ценность пользователям. Впрочем, тоже самое можно сказать о любых других продуктах — проверить, полезен ли он потребителям, нужен ли им можно только экспериментально.
Обычно Демо проводится в виде встречи, на которой присутствует команда и все заинтересованные стейкхолдеры: члены команды демонстрируют созданную ценность и получают обратную связь. Именно такую форму рекомендует Scrum Guide. Процедура кажется простой, однако практически с таким способом связано несколько проблем, которые мы обсудим далее.
Проблемы получения релевантной обратной связи
Итак, какие же проблемы могут быть связаны с простой демонстрацией?
Во-первых, далеко не всегда на Демо удается обеспечить присутствие необходимых стейкхолдеров, среди них часто встречаются реально занятые люди. Во-вторых, далеко не всегда стейкхолдеры в принципе могут оценить ценность сделанного на основе демонстрации. Например, если вы разрабатываете продукт, отдел из отдела маркетинга, который является внутренним заказчиком, поступают предложения о новых необходимых фичах, которые, однако носят статус гипотез, восприятие пользователями которых неизвестно, и в задачу команды входит не только разработка, но и оценка реакции пользователей, доработка по ней.
Да и при заказной разработке софта случается, что заказчиком является руководитель бизнес-подразделения, который приносит проблему не эффективного выполнения каких-либо операций, которую должен решить новый функционал, и, не выполняя операционную работу непосредственно, он часто не может оценить реализацию, а пользователям, которые могут это сделать, надо для оценки самим попробовать функционал на реальных данных… В-третьих, далеко не всегда получается организовать продуктивную коммуникацию на демо, вовлекающую и членов команды и стейкхолдеров из-за культурных различий. Впрочем, тут работает легкий метод: часть коммуникации со стейкхолдерами ведет аналитик, владеющий их языком. Часть, а не всю: полезно, чтобы показ выполнял не он, а те, кто разрабатывал, комментируя свои действия и получая обратную связь, ощущение ценности собственной работы важно.
Отметим, что далеко не всегда эти проблему могут быть в конкретно вашем проекте. Наоборот, в большинстве проектов демонстрации стейкхолдерам достаточно, иначе бы в Scrum Guide не было бы рекомендованного способа. Ну или так было, когда Scrum формировался. Отметим, кстати, что переход от функциональных требований к user story отчасти проблемы демонстрации решал: мы вместо выполнения функций описывали цели пользователей, и демонстрация, как пользователи будут их достигать, работая используя разработанный софт, должна быть достаточна. Однако, что делать, если проблема в вашем проекте существует? Правильный способ решения этих проблем — придумать альтернативные механизмы получения релевантной обратной связи и встроить в процесс именно их, чтобы обеспечить выполнение основной функции демо. Например, в цикл выполнения задачи может быть включено не только тестирование, но выкатка на боевые сервера и A/B тестирование на пользователях. Или установка его на тестовые сервера заказчика с приближенными к боевым данными, и проведение обучения и демонстрации конечным пользователям. Таким образом, есть различные варианты. Но на практике вместо разработки механизмов часто просто назначают формального ответственного «ты будешь смотреть и оценишь результат». И в результате команда идет по неверному пути, а выясняется это только на внедрении функционала. Я слышал истории, когда эти проблемы возникали даже когда таким ответственным стейкхолдером был руководитель проекта от заказчика: он был на демо, был очень доволен, команда была вдохновленной. А потом оказалось, что он не слишком давно работает у заказчика, и его представления о процессе были основаны на опыте работы в другом месте. Поэтому, когда функционал принесли конечным пользователям, то выяснили его слабую пригодность для реального процесса. Заметим, что техническая выкатка изменений на боевые сервера не спасает, так как пользователи, не зная о новых функциях им просто не пользуются. А вот изменение работы пользователей в любом случае надо отдельно организовывать.
Отмечу, что примерно те же проблемы возникают и при применении Scrum для не IT-проектов: новые продукты или новые материалы недостаточно просто сделать и предъявить, могут быть необходимы испытания, тестирование на пользователях или у заказчиков. Типичный пример — маркетинг, конечным результатом маркетинговой компании тут являются привлеченные пользователи или покупатели, а вовсе не публикация рекламы, и именно по ним можно определить ценность.
Что делать с долгой обратной связью?
Как было отмечено выше, в ряде случаев получение релевантной обратной связи подразумевает долгий по времени процесс. И далеко не всегда это может решено внутри спринта по объективным причинам. Если такие задачи встречаются изредка, то можно получение обратной связи выделять в отдельный поток, при этом может быть допустим перенос их в следующий спринт. Если же такие задачи составляют большинство, то надо придумывать другие механизмы.
Один из них — splitting sprint, при котором команда живет в двух спринтах, сдвинутых относительно друг друга, например, на неделю, в первом происходит разработка и тестирование вплоть до выкатке на боевые сервера, которое носит предсказуемый характер, а во втором –тестирование на реальных пользователях и экспресс-доработки по его результатам. Планирование учитывает оба процесса и связано с первым циклом спринтов, а демо может проходить дважды или быть связано со вторым циклом. Отметим, что команда при этом остается общей, и хотя разработку и тестирование на пользователях часто делают разные специалисты, экспресс-доработки и решение проблем требуют участия всей команды. Другой вариант — вынести получение обратной связи от пользователей за пределы Scrum в отдельный Kanban-процесс. Он целесообразен в том случае, если с ним связаны длительные временные лаги, не укладывающиеся в короткий Scrum-цикл.
Отметим, что оба этих механизма могут применяться так же для предварительной подготовке бэклога к разработке.
Отметим, что независимо от выбранного способа, должны быть сделаны механизмы, реализующий еще одну функцию демо: обратная связь по ценности результата должна быть не только получена, но и донесена до всей команды. И не только отрицательная, но и положительная. Об этом часто забывают, успех очередной фичи маркетинг празднует у себя, а на команду транслирует только проблемы. Важно, чтобы команда тоже ощущала успех. То же касается и механизмов, описанных ранее, например, когда выделенные сотрудники из команды обучают новому функционалу пользователей заказчика — обратную связь надо донести до команды. В том числе положительную эмоциональную обратную связь, чтобы люди ощутили ценность сделанного, а не просто приняли это к сведению. Бывают очень тяжелые ситуации, когда реальная обратная связь может запаздывать на месяц-другой из-за реально длительного процесса, включающего, например, производство конечного продукта на основе того проекта, который разрабатывает Scrum-команда. В этом случае все равно надо заботиться о механизмах обратной связи, хотя готовых рецептов у меня тут нет…
Другие задачи демо
Помимо описанной выше задачи получения обратной связи от стейкхолдеров о ценности созданного продукта, Демо решает еще пару вопросов.
Во-первых, на демо идет оценка достижения целей спринта со стороны стейкхолдеров. И связанное с этим позиционирование достигнутого результата как часть более крупных циклов планирования или целеполагания: вклад спринта в разработку релиза, в продвижение к квартальным или годовым целям. Подробнее о цикле релизного планирования я буду говорить в следующей статье, рассказывая полную схему Scrum. А вот работа с квартальными и годовыми целями находится за пределами обеспечиваемого Scrum, для этого можно применять OKR (Objectives and Key Results). До OKR я тоже доберусь в будущих статьях, хотя, наверное, без подробностей. Но независимо от метода, в демо полезно включить оценку продвижения к целям по мнению стейкхолдеров. Во-вторых, на Демо стоит получить обратную связь от стейкхолдеров по работе и восприятию команды в целом. Не по созданной ценности, а по характеру коммуникаций и другим аспектам взаимодействия. Впрочем, обе этих задачи следует ставить только в том случае, если стейкхолдеры достаточно квалифицированы в высказывании такой публичной обратной связи, а команда — достаточно зрелая, чтобы ее принять. В противном случае вместо конструктива можно получить негатив и демотивацию команды.
Однако, как и в случае оценки ценности, если эти виды обратной связи на Демо получить нельзя, необходимо обеспечить другие механизмы ее получения. Ответственным за получение и донесение до команды обратной связи по целям является Product Owner, а по взаимодействию — они делят эту ответственность со скрам-мастером. Почему делят? Потому что к части стейкхолдеров Product Owner все равно пойдет по первому вопросу, и может заодно выяснить второй, нет смысла в двойной коммуникации. В то же время, взаимодействие Команды со стейкхолдерами может не ограничиваться теми, кто получает ценность от созданного продукта, это могут быть смежные и обслуживающие подразделения и команды, и задача взаимодействия с ними в целом лежит на скрам-мастере. И всю обратную связь надо получить до Ретро, чтобы там команда могла это обсудить. Эти циклы обратной связи можно делать и более редкими, не обсуждая это каждый спринт, а проводя большие внешние ретроспективы с участием стейкхолдеров и оценкой ими достижений команды. Это — тоже работающая практика.
Что делать, если сильно не успели?
Стоит поговорить о том, что происходит, когда спринт окончился неудачно, и видно, что команда сильно не успела сделать запланированные работы. Тут следует явно сформулировать принцип, который я в свое время услышал от Хенрика Книберга: не бывает медленной скорости, бывает неверное планирование.
В моменте необходимо решить, что делать с задачами незавершенного спринта. Вернее, необходимо сделать заранее, когда Product Owner явно увидит из Burndown Chart и доски, что в спринте не будет завершено существенное количество задач. Это может быть видно уже в середине спринта, и точно становится явным за два-три дня до окончания. Product Owner должен оценить масштаб проблемы, и провести коммуникацию со стейкхолдерами и командой, выработать решение — на каких задачах делаем фокус, а какие — оставляем не сделанными. В некоторых случаях спринт может быть продлен на один-два дня, если такое решение может существенно повысить создаваемую ценность за целостности набора решенных.
Но в целом это — исключительная ситуация. О том, как проводить планирование и оценку, что именно поместится в спринт мы разберем далее.
Ретро — улучшаем процесс
В заключении стоит поговорить про Ретроспективу — встречу, на которой команда сама оценивает прошедший спринт и достижение целей и работает над улучшением процесса. Непрерывный процесс улучшений — неотъемлемая часть любого Agile-метода. Отсутствие реального ретро часто означает, что команда погрязла в самодовольстве. О проведении ретроспективы есть достаточно много книг и докладов, но в ней, наверное, наиболее сильно проявляются особенности культуры команды и компании, а я никогда на ней не фокусировался, поэтому я не готов рекомендовать конкретные книги и доклады.
Однако, я немного расскажу о полезных практиках, которые, на мой взгляд, не являются тривиальными.
Первое — это позитивное мышление им нацеленность на улучшения. Не «что было хорошо, а что плохо», а «что было хорошо, что нам мешало и как это устранить, и что можно улучшить». Второе — не стоит побуждать всех высказаться, люди стесняются, у них могут быть разные другие причины молчать. Лучше предложить каждому написать тезисы о том, что было хорошо, препятствия и идеи улучшений на стикерах и вывесить. Стикеры можно использовать разных цветов, в зависимости от вида тезиса и эмоционального отношения к ней: для позитива оценивать его вид — счастье, сюрприз и так далее; для препятствий — силу возмущения, для улучшений — накал желания. А потом обсудить по порядку: что хорошо, какие препятствия и как можно устранить, что можно улучшить. Обсуждение тоже можно начать не всем вместе, а в парах — это стимулировать высказаться всем, а не самым активным. Третье — в результате должен быть план улучшений, в котором выделены те, которые считаем наиболее важными и берем в работу на следующий спринт. Важность стоит определять не в обсуждении, а голосованием точками. Можно оценивать не только рациональную важность, но и эмоциональное отношение к идеям, тоже какими-то смайликами. Четвертое — идея изменений может быть сложной, и предполагать несколько шагов, как и в любой задаче, в том числе включать взаимодействие со стейкхолдерами для получения одобрения действий. А реализация может быть достаточно длительной. Их можно включать в общий список задач, или вести на отдельной Kanban-доске со своими фазами.
В случае отдельной доски препятствия и идеи можно вешать на нее не только на ретро, но и течении спринта, немедленно, как оно обнаружено. Но даже если доски нет, полезной является список, который в течении спринта все могут дополнить, или личные списки. Но все равно, это не должно быть единственным входом для ретроспективы. Ретроспектива требует выйти из основного потока работ и перейти из позиции специалиста, который делает работу, в позицию наблюдателя, который эту работу оценивает. И это — отдельное мыслительное усилие и действие. Шестое. Реализация идей требует ресурсов команды, и тут может быть различная политика взаимодействия со стейкхолдерами: может быть договоренность о некоторой квоте на улучшения на каждый спринт, или политика, отличающая мелкие улучшения, которые может делать команда и крупные, о которых надо договариваться. Для взаимодействия со стейкхолдерами часто необходимо сформулировать идеи на их языке: в виде измеримого препятствия для скорости команды, или возможности повышения ее скорости, потенциальных рисков, которые несет ситуация.
В IT частным случаем работы с препятствиями является работа с техническим долгом. Очень часто при реализации принимаются решение о том, что необходимо быстрое частичное решение по ситуации (костыль), а полноценное будет сделано позднее. А потом сделать хорошо забывают. Об этом есть даже сленговая шутка «IT- единственное место, где на костылях быстрее, чем без них». И полноценные решения не делают, но скрытые в коде костыли несут риск. И важно уметь донести его стейкхолдерам в томвиде, вкотором он покажется нестерпимым… То же относится и к другим идеям.
В заключении я хочу сказать, что ретро — внутреннее собрание команды. На нем не должно быть стейкхолдеров для открытого разговора. Однако, помимо внутреннего ретро можно проводить внешнее, со стейкхолдерами, оценивающими работу команды — я писал о нем ранее, рассказывая о дополнительных задачах демо. Однако, несмотря на то, что на ретро есть только члены команды, не все вопросы могут быть подняты. Если какие-то претензии и препятствия носят личный характер, люди могут их не высказывать. И вот тут начинается ответственность скрам-мастера: поговорить с людьми индивидуально, выявить проблему, а потом решить, что делать — выносить ли в какой-либо форме на ретро, или работать через индивидуальную коммуникацию.
Полная схема Scrum — работа с бэклогом и релизный цикл
Я расскажу откуда появляется бэклог и как с ним работать для получения реалистичного прогноза на итерацию, а также про планирование цикла релизов, и этим завершу рассказ про схему Scrum. Отмечу, что это будет расширенный вариант схемы, по сравнению с тем, что я рассказывал в предыдущих статьях, и он обычно не входит в рассказ для начинающих и тренинг для скрам мастера. Тем не менее, он не является каким-то секретным знанием, все это можно найти в материалах для Product Owner и даже в продвинутой версии тренинга для них. Я в 2013 услышал все это как раз на тренинге Джефа Паттона, и был уверен, что это входит в стандартную версию. Но потом мне объяснили, что это мне просто крупно повезло, а стандартные тренинги на сертификат Product Owner, который проходило несколько моих знакомых содержит гораздо меньше материала. Собственно, в этом и состоит смысл проходить даже начальные тренинги у топовых специалистов-практиков — они расскажут много больше, чем обычный тренер. И мне повезло учиться Scrum у Джефа Паттона и Хенрика Книберга, я им очень благодарен, как и другим специалистам, на тренингах которых я был — Ивару Якобсону, Джеффу де Люка и другим.

Начальное наполнение бэклога
Как мы говорили, в Scrum деятельность состоит из выполнения задач, помещенных в Product backlog. Каждая из них несет некоторую ценность и имеет содержание — набор работ, которые надо выполнить. Откуда же появляется бэклог?
Вначале у вас есть идея продукта, который завоюет весь мир, потому что принесет ценность человечеству. Очевидно, что ценность человечеству заключается в принесении ценности конкретным людям и группам людей и ее надо описать. Для этого хорошо подходит формат user story: «Как <роль>, я хочу делать <это>, чтобы <достигать цели>».
Достижение цели — и есть ценность. Формулировки — важны. Классический примеры из новейшей мифологии касаются Стива Джобса. «Я хочу слышать музыку, чтобы получать удовольствие», а вовсе не иметь 100500 записей в своей коллекции — идея, которая породила iPod. «Как менеджер я хочу иметь телефон, работающий долго без зарядки и выполняющий нужные мне функции, и чтобы у моих подчиненных такого не было — это подчеркнет мою значимость» — идея, породившая iPhone, телефон для топов, которые не так много от телефона надо, а вот статус — очень важен. И это было достигнуто не только ценой, но и сознательным отсутствием функций, которые тогда были у навороченных телефонов, которые использовали технари, но не использовали менеджеры. Поэтому для менеджеров телефон получился классным, а для технарей это был отстой, меньше функций за больше денег.
Как легко заметить, в формулировке для iPod часть про роль — отсутствует. Это не значит, что она не обязательна, просто она появится на следующем уровне детализации — вам надо описать представить пользователей, и для этого есть техника персонажей: вы описываете типичного представителя социальной группы и его потребности относительно продукта, в случае iPod — какую музыку любит, где и как много слушает, какое нужно разнообразие и так далее. Техника персонажей требует олицетворения и именования конкретного человека, за которым будет стоять группа, соотнесение его с социумом, очень полезно, чтобы у него появилось лицо, и вообще вы могли говорить от его имени. Эта техника возникла с развитием массового web при работе с User eXperience (UX), но может применяться для любых продуктов и услуг, а не только в IT.
В целом вы детализируете свою ценность по группам пользователей и по составу, но при этом придумываете принципиальный способ реализации, это как раз часть о том, что именно делает пользователь и каким образом. Без особых подробностей, но идея должна быть реализуема, иначе это фантазии.
Для уже существующего бизнеса вместо ценности для пользователей можно использовать продвижение по векторам Objectives and Key Results (OKR) для развития бизнеса. Например, если стоит задача захвата регионального рынка, то вы планируете разные рекламные и маркетинговые акции с целевыми аудиториями и ожидаемым эффектом, но при этом не надо забывать о насыщении рынка количеством товара, адекватным прогнозируемому росту спроса. И так далее.
Предварительный план релизов
Далее есть интересный такт — последовательность захвата мира. Вы определяется последовательность, в которой группы людей начнут использовать ваш продукт, и причины, по которым они это сделают. При этом учитываете, что люди начинают использовать новое по разным причинам, каждому персонажу нужна своя киллер фича: одним важно, чтобы было прикольно, другим — чтобы лучше, чем у аналогов, а третьим — чтобы было в тренде. Для того, чтобы определить последовательность, есть хорошая техника — story mapping, в которой вы раскладываете на доске карточки с фичами, привязывая их к релизам.
Заметим, что фичи бывают трех категорий: одни привлекают пользователей, другие обеспечивают основной функционал, а третьи — обеспечивают целостность работы. Прием платежей в интернет-магазине вовсе не нужен покупателям, для них ценность — товар и доставка, но без оплаты оно не работает и оплата должна быть удобна. Фичи разных категорий реализуются по-разному, киллер фича должна привлекать пользователей, а поддерживающая — лишь не раздражать. Поэтому полагания о классе фичи тоже надо запомнить.
Дальше идет такт оценки трудоемкости. Оценка идет по придуманной принципиальной реализации, и обычно выполняется по аналогии, детализация для более точной оценки на этом этапе отсутствует. Технически это может быть planning poker, о котором я расскажу дальше, или оценка экспертами. Оценка приближенная, поэтому единицы оценки — грубые, обычно в человеко-неделях. Из оценки получаются сроки релизов, в которые необходимо заложить резервы, учитывая приближенные оценки и высокую степень неопределенности в реализации. Они обычно оказываются слишком долгими, особенно для первого, и идет несколько итераций по свертыванию плана. Особенно важно на этом этапе не свертывать план за счет уменьшения резервов, потому что такой план будет не реалистичным.
Важно, чтобы на такте оценки, а лучше — раньше в процессе участвовало ядро будущей команды разработки. Если же ядро команды появляется позже, то с ним нужно заново пройти такт оценки, получить совсем другие цифры и разобраться с расхождениями — это лучше сделать до старта проекта. Впрочем, даже если этого не сделать, итерационная разработка по Scrum или другим Agile-методам за 2—3 итерации проявит проблемы планирования, в отличие от классического проектного подхода, в котором они обычно выясняются к концу проекта.
В целом начальное наполнение бэклога и планирование релизов занимает не так много времени, не больше недели работы нескольких экспертов и стейкхолдеров, часть из которых войдет в ядро будущей команды. Важно, чтобы в составе были не только реализаторы, но и те, кто представляет потребителя и рынок. Для начального планирования часто проводят отдельную сессию на 1—2 дня, центром которой является story mapping. Но это хорошая техника, а вовсе не обязательная часть метода. Возможна просто работа группы экспертов, вместо story mapping можно применять сортировку списка функций. Однако, чего нельзя делать — это заменять ценность на функции и забывать о группах пользователей, которым релиз несет ценность.
Заметим, что в описанной выше технике практически нет специфики IT, ее можно применять для планирования рекламных компаний, создания коллекций одежды и в целом развития бизнеса, особенно при использовании OKR вместо ценности, о котором я писал выше. Однако, что описанное выше нельзя рассматривать как исчерпывающую инструкцию по созданию продукта. Это лишь часть, создание продукта имеет много других аспектов, о которых можно посмотреть бизнес-модель Александра Остервальдера или другие.

Полная схема Scrum
В результате описанного выше процесса, который иногда называют нулевой итерацией, у вас появляется начальное наполнение бэклога и теперь можно запускать спринты, которые объединяются в более крупный релизный цикл, как это изображено на полной схеме Scrum.
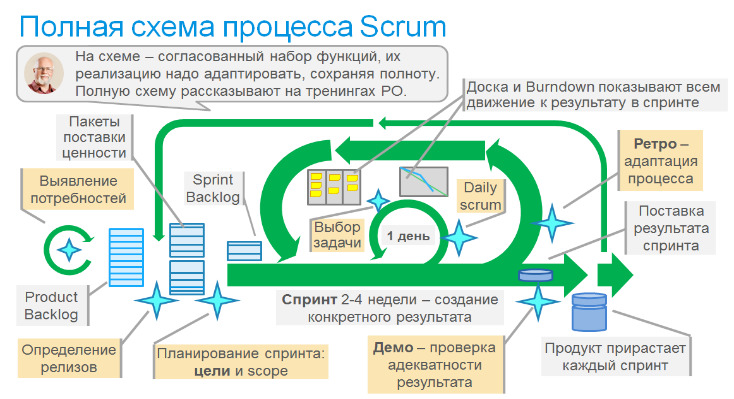
Почему релизы не выпускаются каждую итерацию, если она итерация должна поставлять ценность? Дело в том, что темп выпуска релизов определяется не внутренней скоростью разработки, а характером взаимодействия с рынком — проведением рекламных компаний, привлечения групп пользователей и так далее. Все это разворачивается в собственном темпе. То же можно сказать и про корпоративную разработку: внедрение нового функционала требует изменения бизнес-процессов и обучения пользователей, и эти процессы разворачиваются в собственном темпе. При этом технически новый функционал уже может быть в продукте.
Релизный цикл накладывает свой отпечаток на спринты, могут появляться отдельные спринты стабилизации и выпуска релизов, в некоторых проектах после выпуска может быть предусмотрен спринт срочных доработок по запросам пользователей, или даже переключение в потоковую обработку задач до стабилизации.
Подготовка бэклога к спринту
Как написано выше, предварительный бэклог наполнен крупными задачами, для которых известен только принципиальный способ реализации. Они несут значительную долю неопределенности, которая недостаточна для уверенного планирования спринта. Поэтому до планирования задачи бэклога, которые с большой вероятностью будут включены в спринт, необходимо дополнительно детализировать. Возникает естественный вопрос: а насколько подробно необходимо прорабатывать задачи, кто именно их оценивает. На этот вопрос есть следующий функциональный ответ: содержание задачи должно быть проработано настолько, чтобы (а) Product Owner был уверен, что выполнение этих работ принесет стейкхолдерам желаемую ценность и (б) Команда могла оценить трудоемкость выполнения этих работ на планировании. Не меньше, но и не больше. Потому что именно на основании оценки задач и принимается решение, что помещается в спринт, а что — нет. Однако, использование только функционального ответа недостаточно, потому что разные люди будут по-разному давать ответ на этот вопрос. Поэтому хорошей практикой является разработать чек-лист Definition of Ready, формулирующий критерии готовности задачи к планированию.
За подготовку и необходимую детализацию задач отвечает Product Owner. Как уже говорили, Она выполняется не заранее, а по мере продвижения проекта только для ближайших спринтов. Потому что детальные проработки проекта целиком имеют печальное обыкновение сгнивать раньше, чем добираются до реализации, и оказываются бесполезной работой.
Если такая подготовка задач к будущему планированию требуют заметных трудозатрат, то их надо планировать в предыдущим спринте, а если ограничивается обсуждениями, то отдельное время не выделяется, оно учитывается как общие накладные расходы. Процесс такой подготовки называется backlog grooming или backlog refinement. Груминг — первоначальное название, и оно соответствует сути, однако у него есть негативные сленговые коннотации, поэтому в официальных документах оно было заменено на refinement, подробности можно прочитать в этой статье.
Подготовка бэклога показана на моей рисовке схемы отдельным процессом, хотя часто ее помечают просто надписью на содержании спринта. Этот процесс требует организации. Простой способ — добавить к скрам-доске три колонки слева, в первую из которых Product Owner будет вывешивать задачи, ожидающие подготовки, во второй — те, которые готовятся на данный момент и в третьей — готовые к включению в будущий спринт. Но если процесс более сложен и требует внешних согласований, то такой способ может оказаться недостаточен. Тогда для подготовки бэклога можно организовать отдельный Kanban-процесс — об этом есть хороший доклад Алексея Пименова на SECR-2016 «Discovery Kanban для управления беклогом Scrum-команды».
Еще один вариант организации подготовки бэклога — уже упоминавшийся в главе «Завершение спринта в Scrum — демо и ретро» splitting sprint, разделение спринта на два со сдвигом.
Что происходит, если бэклог не был подготовлен к планированию должным образом? В лучшем случае это будет сделано на самом планировании за счет увеличения сроков встречи. Но вполне может оказаться, что подготовка требует не только обсуждения внутри команды, но и коммуникации со стейкхолдерами или небольших исследований, и тогда задача будет не только оценена неверно, но и сделана таким образом, что результат окажется непригодным к использованию. Если проблема возникает у малого числа задач, то это может быть допустимым риском, только следует учесть, что необходимы уточнения. А если проблема возникает массово, то может быть целесообразно отложить начало спринта и сосредоточиться на подготовке.

Оценка работ
Об оценке трудоемкости следует сказать отдельно. Она может выполняться в физических единицах, например в человеко-часах, в том числе в разрезе конкретных специалистов. В этом случае понятно, как определять, сколько задач поместиться в спринт: у нас есть общий ресурс часов команды, с учетом текущих отпусков, есть нормированные накладные расходы и резерв на регулярные потоки работ, если команда их делает, и дальше мы просто учитываем загрузку специалистов. Такая оценка практикуется, при этом, однако, важно не стремиться к излишней точности оценки. Обычно это достигается применением карточек, где оценка дана в числах Фиббоначи (1, 2, 3, 5, 8, 13, 20, 40) или степенями двойки. Но практика показывает, что при относительно однородном потоке задач не менее точной, зато гораздо более быстрой является оценка не в часах, а условных единицах Story Point или в условных размерах: S, M, L, XL. При этом на нескольких спринтах эта оценка калибруется и емкость спринта или скорость команды определяется именно в таких единицах. Практика показывает, что члены команды могут давать оценку в размерах даже для задач, в которых они не являются специалистами-исполнителями, обучаясь на предыдущем опыте работы.
Опишем процедуру оценки, для этого используется planning poker: после представления задачи члены команды выкладывают карточки с оценками, а потом одновременно их переворачивают. При больших расхождениях идет обсуждение, обычно это означает, что разные члены команды поняли задачу сильно по-разному, что и выясняется в обсуждении. Потом следует повторное голосование.
На планировании вполне вероятной является ситуация, когда оценка задачи получается слишком дорогой для ее ценности. Тогда следует такт обсуждения с Product Owner, который на планировании представляет интересы стейкхолдеров. Во-первых, бывает, что у стейкхолдеров есть на этот случае План-Б, и задачу просто не нужно делать. Во-вторых, возможно, команда может предложить какое-то более легкое решение для реализации, которое удовлетворит основные потребности — правило Парето говорит, что чаще всего это возможно. Это — конструктивное обсуждение.
А вот переход в этом случае к различным способам давления чаще всего не имеет смысла. Потому что наиболее распространенный результат — команда соглашается, а потом просто не делает. И в результате вместо четкого представления о том, что какой-либо функционал не будет получен через две недели, стейкхолдеров обнаруживают это постфактум, две недели спустя, когда они рассчитывали его получить. Не обязательно тот, по поводу которого было давление — может оказаться, что его сделали, но не сделали что-то другое. А если не сделали именно его — то на него при этом уже затрачены определенные ресурсы, и далее надо доделывать или выбросить. Конечно, может оказаться, что сознательная команды сделает этот функционал за счет личного времени. Но, как показывает практика, на это может сработать один-два раза, а вот на регулярной основе это приводит к негативным последствиям: либо команда выгорает и производительность падает, а сотрудники уходят, либо команда начинает систематически завышать оценки, чтобы было, куда отступать при давлении. В любом случае, прозрачность процесса и сотрудничество в достижении цели — разрушается, что разрушает эффект использования Agile-подходов.
Планирование — контракт на спринт
Вообще надо отметить, что планирование представляет собой заключение контракта на спринт между командой и стейкхолдерами, при этом интересы стейкхолдеров представляет Product Owner. Этот контракт может иметь разную жесткость. В свое время была популярной идея о том, что «настоящая команда» на планировании всегда дает обещание, commitment, которое потом выполняет почти любой ценой. Такой взгляд очень нравится стейкхолдерам и, на первый взгляд, отвечает их интересам. Однако, практика показывает, что это неверно. В долгую это ведет к выгоранию команды либо к сознательному завышению оценок, в котором еще и не сознаются, тратя выигранное время по своему усмотрению и превращая работу в agile- курорт. И этому есть системная причина — длинный хвост распределения в оценках IT-работы, о чем есть хороший доклад Андрея Бибичева «Пуассоново горение сроков».
Поэтому правильный подход — учитывать такую статистику на планировании и ранжировать задачи по желательности их исполнения. Для этого можно применять шкалу MoSCoW (Must — Should — Could — Would) или ее сокращенный вариант, и не ставить максимальное значение достаточному количеству задач. Кроме того, учитывая статистику, необходимо не заполнять весь бэклог крупными задачами, в нем должен быть достаточный буфер мелких задач. Конечно, планирование спринта обычно не является заключением какого-то принципиально нового контракта, речь обычно идет лишь о целях и объеме работ на спринт. Однако, в общем случае, стейкхолдерами проекта после любого спринта может быть принято решение о прекращении проекта.
Ценность и содержание работ
Так же хочу еще раз обратить внимание на то, что выполнение состава работ, которым наполнена задача, вовсе не означает, что ценность получена. Начинали наполнение бэклога мы именно с ценности, которую выполнение задачи должно принести пользователям, клиентам или потребителям. Ценность — это решенная проблема или предоставленная возможность. По мере проработки бэклога мы придумали способ получить ценность, сначала — принципиальный, потом — детальный, потом реализовали это. Но при этом наш придуманный способ остается гипотезой, и требует экспериментальной проверки реальным потребителем. И может оказаться, что требуются какие-то дополнительные работы.
— Мы думали, что пользователи смогут, увидев названия документов в результате поиска по базе, выбрать наиболее подходящий, а выяснилось, что для очень много запросов выдает совершенно однотипные списки названий, начинающихся с «Письмо Минфина от DD.MM.YY разъяснением по практике применения…», и выбрать совершенно невозможно.
— Мы думали, что пользователь сформирует список из 10—20 любимых песен для запуска по циклу в фоне, а оказалось, что у многих есть несколько списков для разных настроений, и любимое произведение в одном состоянии превращается нестерпимым в другом.
— Мы сделали специальную форму для оформления заказов с доставкой со склада на тренажеры прямо из магазинов, а оказалось, что сотрудники магазинов по-прежнему звонят в офис и резервируют товар по телефону, а только потом заполняют форму. Потому что боятся, что пока они будут оформлять заказ и подробности доставки, тот единственный тренажер уйдет по другому назначению, и не хотят, чтобы покупатель почувствовал тоже самое, что чувствуют многие из вас, когда после заполнения сведений о пассажирах при покупке билетов получают сообщение, что билеты уже проданы или подорожали…
То есть уже после реализации оказывается, что создание ценности требует дополнительных объемов работ. И на это тоже надо закладывать резервы при планировании. Но если у вас задачи похожие, то статистика позволит оценить качество, с которым команда превращает ценность в содержание работ, и требуемый размер буфера.
Отметим, что важно закладывать общий буфер, а не резерв на каждую задачу: дело в том, что имея по задаче оценку с резервом, разработчики всегда испытывают искушение повысить качество реализации, если они сделали задачу быстрее оценки. А если задача оказалось сложной — то превышают оценку. По этой же причине, кстати, детальные оценки на планировании спринта в человеко-часах хуже оценки в размерах или условных единицах.
Место Agile-команд в компании
Сейчас мы поговорим о месте Agile-команд в большой компании. Вполне возможно, когда вся компания состоит из agile-команд. Но если речь идет о большой компании, которая сейчас работает, применяя другие управленческие подходы, то трансформацию стоит проводить постепенно. И, более того, далеко не всегда всю компанию стоит перестраивать. Есть смысл оценивать сравнительную эффективность разных методов, основываясь на характере деятельности и доступном персонале. А можно руководствоваться классическим «солнце всходит и заходит, ничего не надо трогать», в большинстве компаний можно найти хорошо работающие подразделения.
Хотя ранее я писал о Scrum, в этой речь пойдет об Agile-командах, применяющих различные методы. Они все достаточно похожи и имеют общие принципы работы, заложенные в Agile-манифесте — итерационную поставку ценности, сотрудничество с заказчиком и другими стейкхолдерами, самоорганизацию вместо прямого управления, доску или другие артефакты, обеспечивающие прозрачность работы для команды и стейкхолдеров и еще много общего. Все масштабируемые Agile-фреймворки рассматривают команды как единицу организации. В том числе и Kanban, который отличается тем, что целевой образ практики не зафиксирован в методе, а прорастает в ходе эволюционного развития. Кстати, Kanban умеет не только организовывать работу команды, но и оркестровать работу многих команд, которые применяют различные методы организации работ, включая классические. Впрочем, его я еще буду рассматривать в будущих статьях, как и другие фреймворки, а пока поговорим про место Agile-команды.
Успех Agile определяется тем, что он позволяет уверенно работать в условиях большой неопределенности, связанной с динамикой внешнего мира, а также при отсутствии компетентного персонала. Таким образом, можно сформулировать следующее обобщенное правило по выбору способа сделать новый проект или организовать деятельность.
— Если вы в компании собираетесь сделать новый проект или организовать деятельность, и у вас есть компетентные сотрудники для этого — пусть они организуют работу известным им способом и придут к успеху.
— Если в индустрии известны способы, которым можно достичь успеха в новом деле, но у вас нет компетентных в нем сотрудников — попробуйте их найти.
— А вот если нет ни способа работы, ни компетентных сотрудников, то сделайте ставку на самоорганизующуюся вовлеченную команду и используйте Agile-методы или другие способы самоорганизации для организации ее работ.
Отмечу, что бывает еще один случай, когда дело для компании новое и людей с доказанной компетентностью нет, однако есть признанный руководством лидер или команда, которым «любое дело по плечу», и работу доверяют им. На самом деле, это сводится к первому варианту: за людьми признана компетенция «успешно делать ранее неизвестную работу, разбираясь в ней в темпе проекта». Такие люди реально встречаются, хотя и редко. Если надо сделать что-то новое, и у вас нет компетентных сотрудников, и вы не можете их найти — используйте Agile. Или откажитесь от дела.
Кеневин-фреймворк — можно ли найти компетентных сотрудников
Если с компетентностью собственных сотрудников более-менее понятно, то со вторым способом могут быть проблемы. Компания решила начать новую деятельность или сделать проект — как узнать, есть ли в индустрии способы ее успешной организации? Помимо поиска информации об аналогичных проектов есть обобщенный способ получения ответа на этот вопрос — Кеневин-фреймворк (Cynefin framework) из теории сложности.
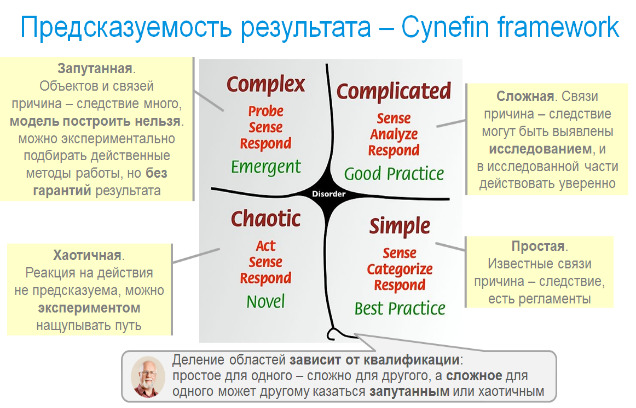
Он говорит о том, что устройство мира можно разделить на четыре области.
— Простая (simple), в которой есть понятные связи и законы.
— Сложная (complicated), в которой причины и следствия могут быть выявлены исследованием и поняты могучим разумом.
— Запутанная (complex), в которой объектов и связей настолько много, что хотя по-отдельности они понятны, поведение системы в целом пониманию не поддается.
— Хаотическая (chaos), в которой поведение системы не предсказуемо.
Отмечу, что извилистые границы областей на схеме — не вольность художника, а отражение замысла автора концепции, Дейва Сноудена, который таким образом подчеркивал нечеткость границ.
Одна из проблем, которую фиксирует эта схема — это ошибочное отнесение запутанной системы к сложной области. Люди видят устройство основных объектов и основные связи, и полагают, что они знают устройство системы и могут предсказать ее поведение. При этом они пренебрегают многочисленными дополнительными объектами и связями, полагая их неважными — и ошибаются в предсказании. Они делают исследования, узнают еще кусочек, и снова надеются, что теперь все знают, но опять ошибаются. Это — типичная ошибка эксперта, особенно начинающего, на котором еще сказывается эффект Даннинга — Крюгера. Аналогично, начинающий специалист, разобравшийся в правила простой области, может вообще не видеть ограниченность своих моделей, полагая применимыми их к любой ситуации. Для каждой области есть свой оптимальный образ действий.
— В простой надо написать регламенты и правила и действовать по ним. И эти регламенты не надо создавать с нуля, они обычно уже имеются в культуре человечества, надо лишь найти нужные и адаптировать к вашей ситуации.
— В сложной — найти высококвалифицированных специалистов, которые поймут область и выработают правильный способ действий. И, опять-таки, исследования уже, вероятно, проведены до вас, и стоит найти результаты и опираться на них, и привлекать тех, кто имел с этой областью дело.
— В запутанной надо постоянно проверять гипотезы и накапливать работающие приемы, которые дальше можно повторять, однако следует быть постоянно готовыми к тому, что известное действие даст неожиданный результат.
— В хаотической можно только экспериментировать, и если получилось удачно — то замечательно. «Попробуй — и получится, а если не получится — попробуешь опять», как поется в известной песенке.
Замечу, что этот список примерно соответствует трем классам проектов Дэвида Майстера: Мозги, Седина и Процедуры.
— Процедуры — то, что компании знакомо, является рутиной и может выполняться с гарантированным результатом. Это соответствует простой области.
— Седина — в этих проектах результат не гарантирован, но может быть достигнут за счет опыта. Это сложная область.
— А Мозги — это принципиально новый проект, в котором опоры на опыт недостаточно для успеха. Здесь мы говорим о действиях в запутанной области.
Так же развитие науки и инженерии неуклонно превращает хаотические области в запутанные, проявляя в них отдельные фрагменты, затем — в сложные, понимая систему в целом, и затем из сложных делает простые, убирая всю сложность в базовые решения. Примером может служить самолетостроение, путь от первых экспериментов с самолетами, которые постепенно перевели область от хаотической к запутанной, к современному уверенному проектированию самолетов с заданными характеристиками, которое относится к сложной области. Впрочем, сложной оно является только при наличии компетенций, и то, что ведущие страны (Россия, Штаты, Европа) делают уверенно в своем военном и гражданском самолетостроении, для Китая и других развивающихся стран является в лучшем случае экспериментальной работой в запутанной области. При этом, как хорошо известно, распределение компетенций в военном и гражданском самолетостроении различно. Классификация по сложности зависит от компетентности специалистов: простое для одних является сложным для других и запутанным для третьих.
Далеко не всегда путь в сложную область является путем уверенного численного моделирования. Это может достигаться за счет активного открытого сотрудничества и накопления практик. Здесь интересен пример дельтапланов: в отличие от самолетов, их нельзя рассчитать на текущем уровне развития моделей, потому что ткань, из которой делают крыло полупроницаема для воздуха, а если сделать ее непроницаемой, то дельтаплан становится неустойчив при резких порывах ветра. Тем не менее, за счет активного обмена опытом дельтапланеристов, накапливающего и распространяющего хорошие решения, дельтапланы сейчас строятся уверенно.

Области использования Agile
Теперь попробуем указать на конкретные области применения Agile-методов. Как легко увидеть из описания способов работы в разных областях, область регулярного менеджмента — простая и сложная области. Специальные люди — бизнес-технологи делают и совершенствуют регламенты и процедуры, а все остальные по ним действуют. Разница лишь в том, что для простой области процедуры известны, а в сложной надо вести исследования. А область Agile-методов — запутанная и хаотическая области, где надо двигаться с постоянными экспериментами и коррекцией курса.
Всякая социальная система обычно является запутанной. И одна из задач регулярного менеджмента состоит в том, чтобы превратить систему с участием людей в сложную или даже простую. На языке менеджмента это называется «исключить влияние человеческого фактора на результаты работы», и достигается с помощью процедур и регламентов. Это достаточно успешно можно сделать, когда сотрудники компании преимущественно выполняют физический труд, который хорошо поддается нормированию, а продуктом компании является физическое изделие, пусть даже очень сложное, но типовое, например, автомобиль.
Однако, если компания оказывает услуги, то окружением, в котором она работает, является социальная система. Конечно, ее тоже можно нормировать, как, например, поступает ряд туристических компаний, продающих только стандартные туры, но при этом вы ограничиваете свой рынок. Кроме того, часть услуг требуют не физического, а умственного труда, например, медицина или образование. В этих случаях регулярный менеджмент организует работу через нормирование компетенций сотрудников и их проверку через тесты, экзамены и сертификацию. Однако, это возможно лишь в стабильных областях — при динамичном развитии учебные курсы и сертификационные программы не успевают за изменениями, и результаты хорошо знакомы каждому по массовой медицине и массовому образованию.
Современный мир характеризуется все большей динамикой развития, которая ведет к изменчивости внешнего окружения компании в VUCA-мире, и к обесценивают компетенций из-за быстрого развития технологий. В результате простые и сложные области превращаются запутанные, и область применения Agile-методов неуклонно увеличивается. При этом, из-за ошибок классификации, эффекта Даннинга- Крюгера и сильной недооценки динамики изменений, очень распространенной является ложная уверенность в том, что регулярный менеджмент может решить проблемы возросшей сложности, стоит лишь несколько напрячь мозг или позвать «настоящих специалистов». Это касается как топов и владельцев бизнеса, так и консультантов.
Основываясь на этом, можно сформулировать следующие условия, при которых стоит применять Agile-методы в операционной деятельности:
— Если область запутана и регулярные процессы все время дают сбои
— Если в области высокая динамика, и требуется частое изменение процессов
— Если в потоке запросов много особых клиентов, которых не хочется терять
— Если не ясны факторы успеха продуктов, надо пробовать и экспериментировать
— Если квалифицированный персонал — дефицитен, недоступен или дорог
Кроме того, Agile-методы стоит применять в процессах поиска мест потенциальных улучшений и при ведении проектов изменений компании — они работают с организацией как с социальной структурой, и потому относятся к работе в запутанной области. Правда, Agile-коучи, проводя трансформацию не часто начинают с того, что вешают доску для самого процесса трансформации и организуют спринты. Причина обычно не в том, что они не используют Agile-методы для организации своей работы, а в том, что в нее часто вовлечены руководители компании, которые привыкли работать более традиционным образом. Они готовы попробовать трансформировать отдельное подразделение в пилотном режиме, но не готовы сами изменить способы своей работы, во всяком случае сразу. Поэтому Agile-коучи применяют Agile для проекта трансформации, но не афишируют это.
Изменения идут итеративно, при этом есть гейты на которых фиксируется, что в процессе изменений не просто поменяли работу, а что эти изменения начали приносить эффект, то есть была создана ценность изменений. Например, Асхат Уразбаев в одном из выступлений так описывал этапы изменений работы команды.
— Сначала команду учим поставлять каждую итерацию что-нибудь.
— Потом учим делать нужное — поставлять ценность.
— Потом учим быть предсказуемыми — поставлять запланированное на итерацию количество ценности.
— Потом учим самоорганизации — умение оценивать свои процессы и улучшать их.
С каждым этапом связаны определенные поведенческие маркеры — изменения работы членов команды и команды в целом, и каждый из них означает определенное изменение культуры команды. И каждый такт — определенный шаг от привычных ранее методов работы к новым. Поэтому Agile-коуч должен не только хорошо знать Agile-методы и практики, но и иметь навыки изменения поведения и культуры групп людей. Почему-то об этом часто забывают руководители, заказывающие трансформацию. Особенно забавно, что эти люди часто знают о собственных проблемах в изменении поведения, например, никак не могут начать заниматься спортом или ходить на фитнесс, но почему-то уверены, что Agile-коуч сможет в заданное время гарантированно изменить привычки их сотрудников…
Не всегда компетенции по Agile и психологии сочетаются в одном человеке. И тут я хочу привести пример трансформации компании InfoWatch, когда кроме Agile-коуча привлекли профессионального психолога. Он использовал групповой вариант методики «Психология позитивных изменений» — метода, с помощью которого в индивидуальном варианте людей отучают пить и курить и проводят другие изменения поведения. Там разработана система оценки — принял человек новые правила, или еще требуется закрепление. Agile-коуч вел команды по известному ему пути, а психолог оценивал: готова команда к следующему шагу, или нужно закрепление. В результате изменения прошли очень гладко, качественно, и, на удивление, не занял много времени.
Создание команд и перестройка цепочек создания ценности в Agile-трансформации
Ранее я рассматривал вопрос о том, в каких областях разумно применять Agile-методы в зависимости от характера деятельности. Сейчас я буду говорить о том, как перестраивается производство компании при организации Agile-команд. Многие слышали и знают, что Agile-команда является кроссфункциональной, то есть в ней собираются специалисты, ранее работавшие в разных функциональных отделах. А значит и производственные процессы, характер цепочек создания ценности принципиально изменяются: работа, которая раньше передавалась из отдела в отдел, теперь собирается в команде. Именно с этого мы начнем рассмотрение.
Зачем нужна кроссфункциональная команда вместо функциональных отделов?
Вообще такое преобразование кажется неверным с точки зрения регулярного менеджмента. Ведь, начиная от Адама Смита «все знают», что повышение производительности достигается за счет разделения труда. В книге «О богатстве народов» он приводит знаменитый пример с изготовлением булавок: разделение изготовление на 18 операций, каждую из которых делают отдельно, приводит к тому, что 10 рабочих изготавливают в день 48 тысяч булавок, в то время как при индивидуальном изготовлении рабочий их делал не более 20 в день: увеличение производительности труда в 240 раз. В эту сторону идет и конвейер Форда, который принципиально повысил скорость изготовления автомобилей — до одного в минуту.
Однако, в этих случаях речь идет о стабильном производстве физического труда. Каждую операцию можно хорошо спроектировать и нормировать время и качество его выполнения: Форд проектировал свой конвейер с учетом физических возможностей человека, чтобы рабочим не нужно было делать шагов, они до всего могли дотянуться руками. Таким образом, организация производства с разделением труда требует специальных людей — бизнес-технологов, которые разложат труд на операции, нормируют их результат, придумают приемы для выполнения и разработают программы для обучения тех, кто будет их выполнять.
Собственно, когда в IT возникла необходимость массовой разработки с появлением персоналок, вызывавшем взрывной рост потребности в программах автоматизации для множества конкретных фирм, то попробовали пойти по такому же пути. Конечно, в отличие от булавок или автомобилей программы — изделия индивидуальные, однако для этого были наработаны методики индивидуализированного производства, применявшиеся, например, в строительстве зданий или других аналогичных отраслях. Конструкторы-проектировщики разрабатывали технический проект, который потом отдавали в производство и получали готовое изделие с более-менее гарантированными стоимостью, сроками и качеством. Аналогичную конструкцию попробовали сделать в IT, и так появился Rational Unify Process (RUP). Не получилось. Для этого есть системные причины, подробнее я рассказывал о них в главе «Развитие и провал регулярного менеджмента в IT» и не буду повторяться.
А здесь хочу отметить, что автоматизация бизнеса имеет еще одну важную особенность: окружение, в котором работает система, динамично изменяется во времени. Конечно, при строительстве индивидуальных домов или ремонте квартир это тоже имеет место: у заказчика могут непрерывно возникать новые пожелания, но если они касаются уже построенного, то ему можно предложить голосовать деньгами. Однако, есть опасность что при бесконечных переделках дом никогда не будет закончен, такие примеры известны. В IT задача успеть за изменениями бизнеса при его автоматизации гораздо более актуальна, речь идет не о произвольных желаниях, а о следовании за изменениями процессов, которые компании продиктовал рынок.
Как и в случае строительства (или ремонта квартиры), выход в том, чтобы собрать всех необходимых специалистов в одну команду, чтобы они вместе преодолевали трудности. И лучше, если каждый из этих специалистов могу выполнять несколько функций, а не одну, чтобы они могли поддерживать и помогать друг другу во время работы. Так вместо функциональных отделов появляется кроссфункциональная команда. Это — первое из тех изменений, которые принес Scrum.

Цепочки создания ценности
Кроссфункциональные команды вместо функциональных отделов изменяют и сам характер производства. Рассмотрим это подробнее. Для этого нам понадобиться обобщенная структура компании. Я буду работать на той схеме, которую Генри Минцберг дает в своей книге «Структура в кулаке» (Structure in Fives). Он выделяет пять частей организации:
— Стратегический апекс разрабатывает стратегию и осуществляет общее руководство
— Техноструктура разрабатывает и налаживает бизнес-процессы, именно там сидят те бизнес-технологи, о которых шла речь выше.
— Срединная линия менеджмента организует работу подчиненных в соответствии с регламентами и процедурами, а также разбирает особые случаи и сбои, вызывающие отклонение от процесса.
— Операционное ядро выполняет основной бизнес-процесс, разложенный на операции, обеспечивая цепочку создания ценности.
— Вспомогательный персонал представляет собой инфраструктуру, поддерживающую работу компании.
В целом это изображено на схеме. При этом условиями является грамотное построение процессов и обеспеченность компетентным персоналом.
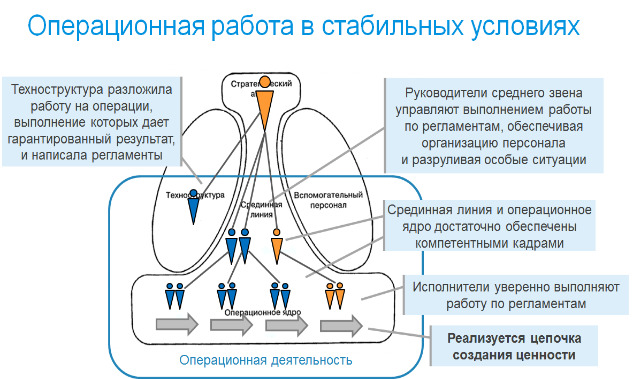
Цифровой мир ломает традиционную структуру
В цифровом мире такая организация работы становится невозможной, это изображено на следующей схеме. Регулярная часть процессов переходит в IT-системы, а персонал занимается только особыми случаями. Ранее их рассматривали лишь опытные сотрудники, которые учились это делать, постепенно набирая опыт, а теперь они сразу должны работать исключительно с такими случаями. Техноструктура не успевает перенастраивать бизнес-процессы в темпе развития технологий и изменения условий работы компании в VUCA-мире. А менеджмент среднего звена при отсутствии стабильных процессов должен совмещать менеджерские и профессиональные предметные компетенции, реорганизуя производство «на лету». Конечно, такие люди есть, но они — дефицитны, и невозможно сделать такими всех менеджеров.
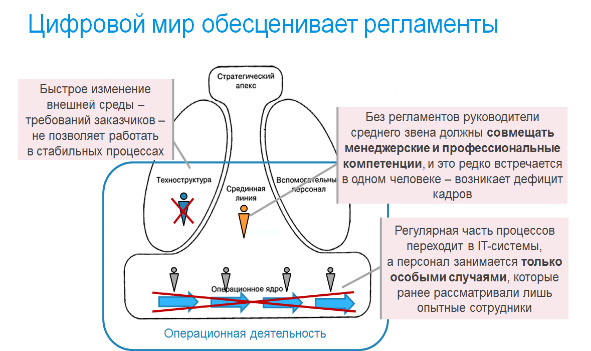
Решение — кросс-функциональные команды
Организация кросс-функциональных команда позволяет решить эти проблемы, как показано на очередной схеме. В команду собираются все специалисты, которые необходимы для выпуска конечного продукта, и она работает, короткими итерациями, непрерывно корректируя свой путь, проверяя гипотезы о продукте на соответствие рынку. Позиция менеджера среднего звена разделяется на две: ответственного за конечный продукт с компетенциями предметной области и ответственного за самоорганизацию команды, обладающими компетенциями по работе с людьми.
Что же происходит с техноструктурой? А ее роль изменяется принципиально: вместо организации бизнес-процессов и регламентов они занимаются организацией качественной коммуникации и обучают людей это делать, фасилитируют совещания и обсуждения, и так же прорабатывают средства, обеспечивающие прозрачность происходящего в командах для руководства и синхронизацию движения в целом. Таким образом, работа с процессами уходит из техноструктуры в команды, которые сами организуют свою работу, а вот работа с персоналом, коммуникациями и культурой из обеспечивающей задачи для инфраструктуры превращается в основную задачу техноструктуры.
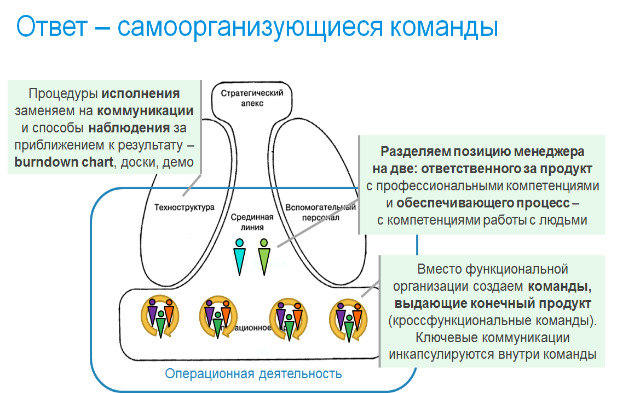
Как я отмечал раньше, типичной является ситуация, когда команды недостаточно обеспечены компетентным персоналом. В IT это случалось неоднократно в связи с бурным развитием технологий, и эти периоды, думаю, помнят не только не только IT-шники. Сначала, в 90-е, всем была нужна автоматизация процессов. Сначала интернет стал доступнее и всем компаниям потребовались сайты. Потом интернет стал быстрее, и множеству компаний потребовались не просто сайты, а интерактивные интернет-магазины. Потом волна, когда всем нужны мобильные приложения. И на этом процесс не закончится — уже сейчас идет волна чат-ботов, которые будут становиться все умнее, вплоть до полноценного искусственного интеллекта. Поэтому в IT наработаны схемы организации работы в условиях некомпетентных команд. При этом выделяются позиции технических наставников из числа людей, у которых получилось быстро освоить новые технологии, они обучают новичков и проводят аудит технических решений. Это изображено на следующей схеме. Наставники организуются в сообщества для обмена опытом. В ряде фреймворков масштабирования Agile на компанию, например, в Spotify, одним из элементов организации являются профессиональные гильдии, объединяющие людей одной специализации из разных команд для решения профессиональных задач.
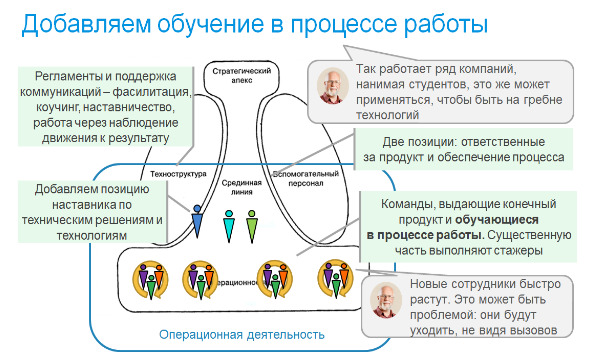
Отметим, что так работают многие компании даже в области относительно устоявшихся технологий, нанимая студентов и обучая их в процессе работы. При этом сотрудники быстро растут, способные остаются в компании, если она расширяется, но большинство через небольшое время уходит в другие компании уже сложившимися специалистами, а компания нанимает новых студентов — это заложено в бизнес-модель. А вот для более традиционных компаний, ранее ориентированных на долгую работу сотрудников, такой быстрый рост и связанный с этим уход сотрудников может стать неприятным сюрпризом.
Гибридная схема частичной перестройки
Как мы видим, основное изменение состоит в том, что длинная цепочка создания ценности заменяется короткой, инкапсулированной в одной команде. Естественно, это не всегда возможно, и, более того, далеко не всегда целесообразно. Возьмем, например, компанию по производству окон. Значительная часть производственного процесса, которая обеспечивает выполнение уже полученного заказа, хорошо организуется методами регулярного менеджмента, и для нее в кардинальной перестройке нет смысла. А вот взаимодействие с клиентами, поиск и предложение новых продуктов как раз могут быть интересным участком перестройки. Такая частичная перестройка изображена на следующей схеме.
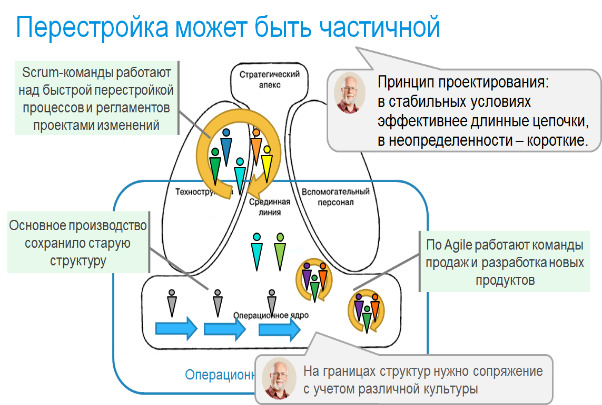
Отметим, что на стыке между Agile-командами и регулярным производством возникает культурный разрыв из-за существенно отличающихся способов организации. И в таком гибридном случае необходимо правильным образом обеспечить, чтобы разница культур не приводила к негативу и враждебным взаимоотношениям, ведущим к потерям для компании. Для этого надо понимать ценности, культуру и образ мышления людей в каждом из участков компании, и организовывать коммуникации с учетом этих различий, снимая понятийные барьеры коммуникации. В частности, надо объяснять производству, что изменения в продуктах компании и заказах клиентам связаны не с неорганизованностью менеджеров по продажам и отдела маркетинга, которые «не могут заранее выяснить, чего на самом деле хочет клиент», а с объективной динамикой внешнего мира. И, наоборот, объясняя продавцам и маркетингу, что производству свойственна определенная жесткость и инерционность, и оно не может перестроиться мгновенно не потому, что там «все ленивы, консервативны и не хотят шевелиться». И не только объяснять все это, а практически работать над решением конфликтов и поиском решений в межкультурной коммуникации.
А еще надо обеспечивать прозрачность и управляемость бизнеса, который разворачивается в такой неоднородной структуре. И тут на помощь приходит Kanban, который не только организует работу отдельных команд, но и позволяет оркестровать работу компании. Но об этом мы поговорим в следующей статье.
Проектируем Agile-трансформацию компании
Опираясь на написанное выше, что Agile-трансформация — это не просто организация команд, и изменение их способов работы, это еще и перестройка цепочек создания ценности. А значит существующие цепочки должны быть проанализированы, и должно быть понятно, какой из вариантов перестройки мы выбираем. Иллюстрацией служит следующая схема.
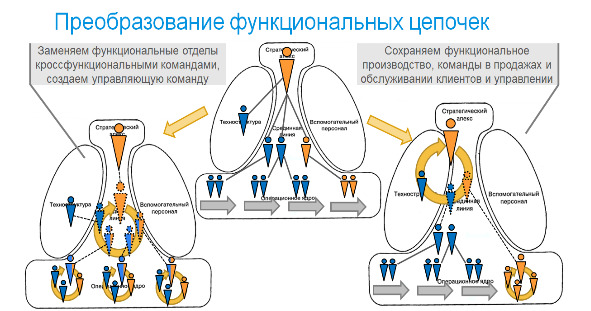
На что опираться в таком решении? Как раз на анализ ситуации компании и ее окружение на рынке и сложность деятельности. При этом надо помнить, что мы работаем с запутанной (по Кеневин, смотри предыдущую главу) социальной системой, поэтому тот образ перестройки компании, который мы получим в результате анализа является не более, чем гипотезой, подлежащей экспериментальной проверке. Гарантированного результата тут получить невозможно. Именно поэтому Kanban вообще предлагает начать стартовать с существующей организации компании, сделать прозрачным поток создания ценности и запустить эволюционный процесс перестройки. Правда, есть опасность, что этот эволюционный процесс увязнет в привычной рутине, и поэтому данный путь сложнее, чем революционная реорганизация.
В любом случае, бывают ситуации, когда переход к кросс-функциональным командам для определенных участков компании является достаточно очевидным решением, исходя из анализа деятельности или просто с учетом сопротивления преобразованиям. В этом случае надо организовать будущие команды. При этом опыт IT однозначно говорит, что их недостаточно организовать логически, просто собрав людей и объявив, что они теперь будут работать одной командой, как иногда делают при организации проектных групп. Надо провести физическую реорганизацию, объединив людей одной команды в единое физическое пространство. Разумеется, сейчас есть техники работы распределенных команд, но, во-первых, они сложнее, а, во-вторых, сохранение привычного окружения надежно останавливает любые новшества. Фраза Питера Друкера, «культура ест стратегию на завтрак» к этой ситуации тоже вполне применима. Должен ли сотрудник работать только в одной команде? Ответ из опыта IT — это крайне желательно. У любой команды должно быть ядро сотрудников, у которых команда является единственным местом работы. Может быть некоторое количество специалистов, занятых частично, и участвующих в 1—2 командах. Но не больше, во всяком случае, сотрудник, разрывающийся между 5—10 проектами — пример вопиющей неэффективности, потому что, как правило, он не помнит ни об одном. Разумеется, бывают исключения, и я сам знаю таких людей, но это — крайне редкие случаи, а обычно такие ситуации возникают потому, что руководители не знают, кем бы сейчас заткнуть дыру в деятельности, и нагружают сотрудников, которые в результате ни с чем не справляются, выгорают и уходят. И в большинстве случаев это все равно иллюзия решения проблемы.
Инфраструктура компании
Разумеется, есть ситуации, когда команде иногда нужна консультация высококвалифицированного специалиста. Но это не означает, что он должен быть постоянным членом команды. Тут мы подходим к интересному вопросу — кого именно из числа специалистов, необходимых для создания продукта компании следует включать в кросс-функциональную команду, и не окажется ли она при этом слишком большой? Ответ на это в различении основной структуры компании и ее инфраструктуры — вспомогательного персонала на схеме Минцберга, о котором мы почти не говорили. Инфраструктура представляет собой подразделения, которые обеспечивают работу основных подразделений и не являются для них ограничением.
Если юридический департамент согласует любой договор в заданные сроки, например, за один день, а бухгалтерия столь же оперативно готова оформить документы и провести платежи, то это — инфраструктура, и их представителей не надо включать в каждую команду, хотя для них вполне может быть выделен курирующий сотрудник. А вот если команда постоянно прорабатывает новые формы договоров или финансовые схемы оплаты, то среди ее членов юрист и бухгалтер соответственно, иначе в процессе работы могут случиться неприятности.
Заметим, что для того, чтобы обеспечить гарантированный отклик на запросы команд в краткие сроки, инфраструктура должна иметь избыточную мощность, то есть дополнительное количество сотрудников. Потому что запросы имеют обыкновение приходить крайне неравномерно. Одной из типичных ошибок классического менеджмента является сокращение мощности инфраструктуры, основываясь на средней, а не пиковой загрузки сотрудников. В результате в периоды пиковых загрузок встают основные бизнес-процессы. Как легко догадаться, происходит это наиболее ответственные периоды пиковых продаж с соответствующими потерями для компании. Печальные истории подобных сокращений юридического отдела, бухгалтерии или службы ремонта оборудования известны и некоторые даже попали в книги и учебники, но люди предпочитают учиться на своих ошибках, повторяя чужие.
Меняем способ организации команды
Как легко заметить, выше в статье шла речь о кросс-функциональной команде и не было опоры та то, что команда применяет для организации своей работы один из Agile-методов, а не управляется руководителем традиционным образом. И действительно, просто преобразование к таким командам без отказа от обычного способа управления способно дать существенный эффект, и рассматривается в регулярном менеджменте. Там это называют «переходом к проектным группам» или, в более сложном варианте, «переходом к матричной структуре» в зависимости от того, какая именно деятельность и модели управления рассматриваются.
Однако, принципиальным вопросом для успеха таких преобразования является наличие хороших руководителей. Если у вас в компании их достаточно, или вы умеете их привлекать, то в сохранении традиционного стиля управления нет проблем. Однако, обычно именно руководители группы являются дефицитной позицией. Особенно когда работа группы предполагает вовлечение всех ее участников и достижение синергии коллективного взаимодействия — а именно это нужно при работе с новыми продуктами в режиме неопределенности VUCA-мира или при недостатке компетенций. Для этого руководитель должен работать через делегирование, в коучинговом или менторском режиме, а в стиле раздачи поручений. Конечно, книги по менеджменту и лидерству полны призывов именно к такому способу управления, но какой процент таких руководителей вы видели на практике? Очень мало.
Agile-методы, особенно Scrum, решают эту проблему не за счет личных качеств руководителя, а за счет организации процесса. Кроме того, Scrum делит обязанности традиционного руководителя на три части: ответственный Product Owner за продукт, ответственность Scrum Master за самоорганизацию команды, и ответственность команды в целом. Разделение ответственности, передача ее части команде используется и в других Agile-методах. И потому требования к каждой позиции снижаются, подобрать подходящих людей становится легче. А прозрачность работы команды в Agile-методах позволяет наблюдать за происходящим и корректировать при необходимости, помогая команде преодолевать проблемы.
Отметим, что развитие IT показало, что при сохранении принципиального разделения ответственности за продукт и за организацию, детальное разделение ответственности в разных компаниях отличается очень сильно. Недавно Егор Толстой и Стас Цыганов организовали в IT-сообществе сбор полного MindMap управленческой ответственности команды, результаты опубликованы на GitHub и доступны. В статье — картинка, а по ссылке можно скачать себе полный mindmap и внести свой вклад в обсуждение. И хотя эта работа сделана на материале IT-отрасли, в ней много общезначимых пунктов и вы можете подумать о применении его в рамках своей отрасли, выполнив адаптацию сами или организовав аналогичное обсуждение в профессиональном сообществе. А потом — подумать о том, как ответственность разделяется в вашей компании: что находится внутри команды и как именно распределено, что передано руководителю следующего уровня, за что отвечает инфраструктура и техноструктура, увидеть упущенные или провисающие фокусы ответственности.
Так же я хочу поговорить о вариантах перехода от традиционной иерархии к организации с разделением ответственности. Пусть у нас есть отдел продаж, и мы хотим в нем перейти на Scrum с тем, чтобы получить эффекты от командной работы и убрать потери от индивидуализма продавцов. Может показаться, что это совершенно бесперспективная задача, чистое теоретический кейс, потому что «всем известно», что продавцы — яркие индивидуалисты, у них к тому же обычно стоит индивидуальный KPI по продажам — какая тут командная работа и сотрудничество? Между тем, эти кейсы — вполне реальны, более двух лет назад я слышал на IT-Spring от Марины Симоновой (Marina Alex) кейс реорганизации отдела продаж, в котором для пилота выбрали самую отстающую команду. Трансформация была успешной, подробности можно посмотреть в выступлении. Кстати, Марина развивает применение Agile в продажах, сейчас у нее разработан собственный SWAY-фреймворк для Agile в продажах https://www.swaysystem.org/ (здесь по-русски), признанный на международном уровне. При этом стиль работы подразделений реально изменяется, появляется сотрудничество и взаимопомощь, которая и обеспечивает эффект от преобразования. Правда, необходимо не только изменить процессы управления и работать с культурой и ценностями сотрудников, но и изменить систему мотивации, уходя от индивидуальных KPI.
Так вот, при agile-трансформации большого департамента продаж, состоящего из нескольких отделов, есть два существенно различных варианта, изображенных на схеме. Если у вас в компании стратегией продаж занимается руководитель департамента, который при этом обычно является директором по продажам или занимает аналогичную должность, а руководители отделов лишь организуют работы сотрудников, то директор по продажам становится Product Owner для всех команд, а руководители отделов — скрам-мастерами. А если отделы продаж работали достаточно автономно, например, по сегментам рынка или разным продуктам, и ответственность за выбор направлений по каждому направлению была на руководителях отделов, то именно они могут стать Product Owner, образуя управляющую продажами команду в стиле Scrum of Scrum, а скрам-мастеров при этом надо выбирать внутри команд. Тщательная работа с культурой сотрудников будет нужна в любом случае, впрочем об этом я уже говорил.
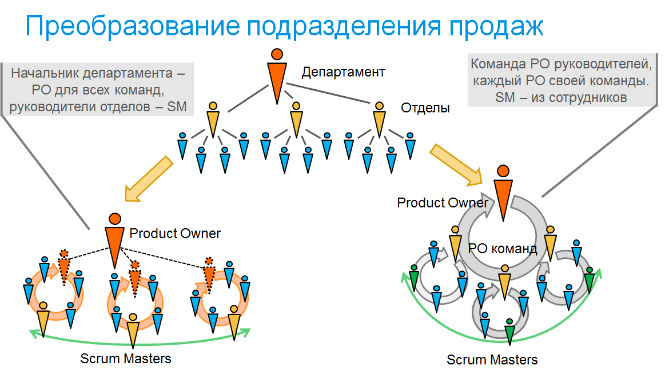

Kanban и Lean — эволюция вместо революции
Распространено мнение, что Kanban является сильно упрощенным вариантом «Scrum без спринтов» для ситуации, когда команда должна просто обрабатывать поток задач. Это неверно. Kanban, в отличие от Scrum, вообще не дает какого-либо фиксированного способа организации процесса. Он запускается на основе существующего процесса и набора ролей, визуализирует поток создания ценности, а затем начинает эволюционные изменения для наращивания потока и исключения лишней работы.
Kanban может быть запущен как для одной команды, организуя его работу, с постепенным расширением области применения на смежные команды, так и для компании в целом, соорганизуя и оркеструя работы многих команд. Его естественным развитием является Lean, ориентированный на оптимизацию цепочек создания ценности. Отмечу, что речь тут идет об IT-вариантах Kanban и Lean, а не об их производственных вариантах, разработанных в Toyota. Kanban Андерсона, насколько я представляю его историю, является оригинальной конструкцией, собранной на основе разных источников. Хотя он и получил свое название от использования Kanban-доски, которая является первым шагом метода и применяется для визуализации потока работ. А Lean является переосмыслением и адаптацией исходного производственного варианта для систем умственного труда, описанным Мэри и Томом Поппендик в книге «Бережливая разработка программного обеспечения» (Lean Software Development). Применяются те же механизмы оптимизации потока создания ценности, однако типы лишней работы для задач умственного труда, принципиально отличаются от типов для физического производства. Чтобы убедиться в этом достаточно сравнить лекции специалистов по производственному Lean и Lean в IT. Сейчас можно говорить о том, что объединение Lean и Kanban в IT, по моей оценке, является наиболее интенсивно развивающимся из Agile-методов, и имеет наибольший потенциал применения во всех отраслях, в связи с приходом цифрового мира, вызвавшего интенсивный переходом от физического труда к умственному.
Начну я свой рассказ с того, что порекомендую замечательный доклад про Kanban Алексея Пименова на AgileDays-2019 «Скрытая механика работы Kanban Method» (мой конспект в отчете с конференции). Алексей является ведущим специалистом по Kanban на всем постсоветском пространстве, включая, естественно, Россию и имеет высокие уровни сертификации от Kanban University и хорошо представляет себе современное развитие метода. Отмечу, что сертификация продвинутых уровней предполагает не просто прохождение курсов и тренингов с проверкой теоретических знаний, а личный опыт практической работы, который проверяется на сертификационном собеседовании — помимо теории ты рассказываешь экспертам-практикам о своих кейсах. Поэтому такой сертификат служит реальным свидетельством квалификации.

Дэвид Андресон. Kanban — альтернативный путь в Agile
Как и большинство Agile-методов, Kanban имеет автора, его придумал Дэвид Андресон и его книга «Kanban — альтернативный путь в Agile» является правильным источником для знакомства с методом, подобно книге книга Джефа Сазерленда «Scrum — революционный метод управления проектами» для знакомства со Scrum. Книги-первоисточники хороши тем, что обычно позволяют проникнуть в замысел автора, показывают логику формирования метода, а не готовый результат. А это очень важно для понимания метода.
Надо заметить, что название «альтернативный путь в Agile» есть только в русском переводе, и, говорят, появилось по настоянию издательства для лучших продаж книги. Оригинал называется «Kanban. Successful Evolutionary Change for Your Technology Business». И в сообществе периодически возникает дискуссия о том, является ли Kanban Agile-методом. С моей точки зрения, безусловно, является. Во-первых, исторически: Андерсон его именно так и позиционировал в своих ранних работах и выступлениях на Agile-конференциях, например, «Agile Management for Software Engineering: Applying the Theory of Constraints for Business Results» (2003). Кстати, она явно показывает один из основных источников — теорию ограничений. Во-вторых, по содержанию: если посмотреть на набор практик, описанный в книге Андерсона, то в целом он хорошо соответствует набору практик Scrum, а также принципам Agile. Что не удивительно, потому что они в целом отражают эффективные методы для IT-разработки. А, в третьих, на уровне культуры: хотя Kanban стартует от существующего процесса и не предъявляет требования какой-либо особой Agile-культуры, прозрачность потока создания ценности, ориентация на его улучшения и сотрудничество со смежниками неизбежно ведет к изменению культуры как раз в том направлении, в котором это сформулировано в Agile-манифесте.
Отмечу, что книгу Андерсона можно читать на двух уровнях. Первый уровень, находящийся на поверхности, показывает набор различных практик, которые постепенно появлялись в методе. А второй уровень показывает логику, в которой эти практики появлялись. В книге Андерсона два уровня: первый показывает набор практик, а второй — эволюционную логику их появления.
Второй уровень значительно важнее первого, потому что именно он показывает логику разворачивания эволюционного процесса улучшений, который и составляет суть Kanban. В книге Андерсон показывает тут путь, который прошли его команды. Следуя духу Kanban, ваши команды пройдут свой путь в той же логике, но стартовав от других начальных условий, и прийдя, естественно, к другому набору используемых практик, потому что этот набор будет зависеть от специфики и условий вашего проекта. И, вероятно, это будут вовсе не простой набор практик, скорее всего, схема процесса будет сложнее, чем фреймворк Scrum, зато она будет отражать вашу специфику. Во всяком случае, то, что получилось у Андерсона и описано в книге — сложнее, поэтому ее и не рисуют.
Доска и проектирование Kanban-системы
Итак, каким образом работает Kanban? Как уже говорили, все начинается с анализа и визуализации на доске существующего потока работ. Об использовании досок в Agile я писал в главе «Доска — визуализация текущего состояния работы», где как раз достаточно подробно раскрывал их работу на примере Kanban. Я не буду повторяться, однако помещу тут картинку из той статьи с описанием основных элементов и приемов, просто чтобы напомнить. Основным результатом визуализации является эмпатия к доске: сотрудники, глядя на доску, понимают текущую ситуацию с работой, и доверяют этому представлению. Отмечу, что такая визуализация иногда сама по себе дает очень большой эффект, проявляя большое количество скрытых проблем: проявляет скрытую работу, выявляя очереди и зависимость команды от смежников, разбираясь с обязательными и не обязательными этапами, а также их последовательным и параллельным выполнением.
Проектирование доски является частью проектирования Kanban-системы в целом. Он выполняется с помощью STATIK — Systems Thinking Approach to Introducing Kanban, описанном в в книге Майка Барроуза (Mike Burrows) «Kanban from the inside». Описывать его я не буду, потому что краткое описание будет достаточно бесполезно. Желающие могут прочесть книгу, или найти и почитать статьи или сходить на первый тренинг «Kanban System Design». Впрочем, если вы любопытны и решите найти статьи с кратким описанием — найдите несколько и сравните.
От функций к сервисам
Самым главным результатом проектирования является вовсе не прояснение потока работ. Главный результат — это ответ на вопрос для кого работает ваше подразделение в компании и какой сервис оно предоставляет тем, для кого работает. Вообще основная идея Kanban — это представить компанию в сервисной структуре. Перейти от представления компании как потока задач, которые выполняются потому что «так надо» и передаются на следующий этап работ соседнему отделу, к представлению компании как предоставляющий сервис конечному клиенту. Это делают подразделения, которые непосредственно с клиентом взаимодействуют, и для этого другие подразделения предоставляют сервис им самим. Основная идея Kanban — это представить компанию в сервисной структуре. Представление через сервисы означает, что у отдела появляется SLA, Service Level Agreement, описывающий условия для обслуживания им внешних и внутренних клиентов, и такие же SLA появляются у его поставщиков и смежных отделов, которых он привлекает для выполнения своих обязательств. Такой характер взаимоотношений принципиально отличается от привычной работы по обработке задач.
Самое существенное изменение касается отношения к простоям. Задача сервиса не в том, чтобы все сотрудники были максимально загружены, задача в том, чтобы все внешние запросы обрабатывались в соответствии с соглашением. Типичный пример, который, я думаю, всем будет понятен — кассы в супермаркете. Нет задачи, чтобы кассир все время выбивал чеки, есть задача, чтобы очередь была маленькой: увидев хвост, покупатели просто пойдут в соседний магазин. Для оказания сервиса требуемого уровня в условиях неоднородного потока запросов нужны избыточные мощности. А когда покупателей мало, кассира можно занять чем-нибудь полезным, но при этом основная его задача — сервис на кассе.
Отметим, что переход к сервисной модели предполагает разделение задач по классам обслуживания. В общем-то, это хорошо известно: всегда есть срочные задачи и поручения от руководства, или важные сделки с VIP-клиентами, которые следует обслуживать в приоритетном порядке. И их тоже следует проявить в ходе анализа потоков работ и сформулировать отдельные SLA. Важно, что сервисная модель предполагает: обслуживание приоритетных задач не должно задерживать обслуживание обычных, поскольку о наличии таких задач заранее известно, и их наличие необходимо было учесть при проектировании сервиса.
С каждым классом обслуживания связан не только SLA, но и правила обработки в команде. По характеру обработки выделяются четыре типа задач: обычные, составляющие основной поток, срочные задачи с отдельными правилами, задачи с фиксированной датой завершения, и необязательные задачи-улучшения, включаемые в работу, когда основной входной поток по каким-то причинам временно уменьшает мощность. Часто именно их и называют классами обслуживания, но это не совсем верно, класс обслуживания прежде всего зависит от назначения задачи для клиента и связанного с этим SLA, а не от внутренних правил обработки, хотя одно с другим безусловно связано.
WIP-лимиты и вытягивание — ограничиваем незавершенную работу
Основными характеристиками сервиса является мощность потока задач, которые он обрабатывает и скорость прохождения отдельных задач через сервис. Как учит теория ограничений Голдратта, для высокой скорости прохождения задач необходимо ограничить количество незавершенной работы. Для этого в Kanban есть механизм WIP-лимитов, которые ограничивают незавершенную работу. При этом используется разные виды лимитов: на человека, на задачу в целом, на классы обслуживания, на этапы работ. Отметим, что в случае обычного производства ограничением является какие-то конкретные этапы обработки. А в IT из-за высокой неопределенности, связанной с исполнением задачи и длинного хвоста распределения вероятности выполнения, мы, как правило, не можем уверенно выделить этапы, являющиеся ограничениями. Поэтому WIP-лимиты устанавливаются для всех этапов.
WIP-лимит служит ограничением не только числа задач, находящихся в работе на конкретной фазе, но и для тех, которые уже готовы для передачи на следующий этап. В этом и состоит суть вытягивания: задача закреплена за фазой исполнения до тех пор, пока на следующей фазе не освободиться для нее место. Таким образом, возможна ситуация, когда завершив очередную задачу сотрудник не может взять следующую, потому что сработало ограничение лимита. И в этот момент возникает вопрос: а что ему делать? Ответы могут быть разными: «отдохнуть и выспаться», «помочь другим», «посмотреть, что можно сделать в других этапах», «почитать книгу». Важно не брать задачу сверх лимита, увеличивая этим незавершенную работу и нарушая, таким образом, производительность Kanban-системы. Теория ограничений говорит: простои сотрудников не ведут к деградации сервиса. Отметим, что переход к вытягиванию и WIP-лимитам поощряет или даже вводит культуру помощи. Сотрудники учатся видеть потенциально узкие места, в которых скапливаются готовые задачи, которые невозможно продвинуться, потому что на следующих этапах образовалось бутылочное горлышко, и помогать в его разгребании. На статусе у доски разбор идет не по сотрудникам, а по задачам справа налево, и следует обращать особое внимание на те зоны, в которых бутылочное горлышко может возникнуть. А еще такой разбор привносит культуру завершения: начиная с задач, которые продвинулись дальше и уже получили больше незавершенной работы, мы даем им больше внимания, фокусируясь на завершении начатого. И, наконец, формируется культура управления через структурирование работы, а не людей, при этом предполагается, что люди сами соорганизуются вокруг работы, которую им необходимо выполнить. Во время перехода к Kanban это делает коуч, а постепенно навык получает вся команда. И таким образом культура сотрудничества, фокуса на завершении задач (ориентированность на клиента) и другие ценности Kanban прорастают в команде. Так же ценностях и культуре Kanban есть перевод хорошей статьи Майкла Барроуза.
Переход к вытягивающей системе выполняется не сразу. WIP-лимиты вводят постепенно, анализируя изменения, к которым их изменение привело для обработки потока задач. И не существует никакой формулы, которая бы позволила вычислить «правильные лимиты» в зависимости от команды: многое зависит именно от конкретного потока задач, а он индивидуален.
Один из простейших лимитов — число незавершенных задач, которые могут быть в ответственности у одного человека. Этот лимит не связан с этапами работ, а призван ограничить незавершенные работы, возникающие из-за внешних согласований. Сотрудник взял задачу в работу, что-то сделал, у него возник какой-то вопрос, он написал письмо — и взял следующую задачу. Когда он так поступил пять раз, то смысл от небольшой начатой работы окончательно потерян. При этом психологически взять следующую ожидающую задачу — гораздо проще, чем разбираться с возникшим затруднением.
Если такие ситуации регулярно возникают и являются типичными, то команда превращается в «отдел ждунов», и это сигнал ситуации, когда никакие внутренние реорганизации не смогут принципиально изменить ситуации. Стоит задуматься о перестройке работы, например, исключении лишних согласований со смежниками или руководством. Сила Kanban-системы в том, что она позволяет увидеть такие ситуации и оценить потери от лишних согласований, а также реальные риски их отсутствия: сколь часто возникают ситуации, когда на согласовании задача была изменена. Алексей Пименов в упомянутом выше докладе рассказывал, что у него было много кейсов, когда согласование занимает 30—50% от времени реализации, и отделу принимать решения без согласования получалось ускорить процесс в полтора раза.
Отдельно стоит сказать про буферную зону входных задач. Для начала можно его не ограничивать, наблюдая за пополнением. И начать регулярно проводить процедуру оценки актуальности задач в буфере: очень часто срочные задачи перестают быть срочными, а не выполненные становятся не актуальными, и нет никакого смысла сохранять их в буфере. И уже после этого вводить ограничения.
Начинать здесь стоит со срочных задач, и не только в буфере, а в целом на обработке, потому что практика показывает, что большое количество срочных задач, которых никто не учитывает, является основной причиной нарушения регулярной работы. Может показаться, что ограничение на срочные задачи — не реалистичное, потому что они часто выполняются по прямому поручениями руководства. Однако, если контролировать их и объяснять, что реально такое количество задач срочно выполнено точно не будет, и надо поставить реальные приоритеты, то получается конструктивный диалог. Практика показывает, что достаточно часто срочность оказывается ситуативной и теряет актуальность, а руководство забывает ее отменить. При этом выполнение в «пожарном режиме» того, что оказалось не нужным является очень сильным демотиватором. Отметим, что выполнение задач, которая стала не актуальной — один из примеров лишней работы, muda в lean.
Отдельно стоит сказать про вытягивание, то есть запуск в работу задач, имеющих фиксированную дату завершения, например, связанных с подготовкой к каким-либо праздникам или датам изменениям нормативных документов. Эмпирическое правило, о котором говорит Андерсон в своей книге, состоит в том, что их следует запускать в работу как можно позже, однако с учетом разумной оценки времени выполнения и определенного резерва времени. Потому что опыт говорит, что чем ближе к дате — тем выше определенность, касающаяся содержания задачи, включая работу смежников. Впрочем, на практике применить это правило довольно сложно, что знают все, кто готовился к экзаменам. Подготовка заранее не имеет особого смысла — ты забудешь выученное. Но вот оценить адекватно время подготовки сложно, в результате последняя ночь перед экзаменом часто проходит вовсе не так, как хотелось бы. Зато это будет одна ночь, а не нервная неделя — время аврала сокращается.

Метрики и индикаторы
Важнейшая составляющая Kanban — культура работы с метриками и показателями. Казалось бы, с их описания следовало бы начать эту статью, ведь ни анализ существующего потока работ, ни, тем более, внедрение обоснованных WIP-лимитов невозможно сделать без работы с метриками. И эта работу там безусловно проводит коуч или менеджеры, проводящие трансформацию. Однако культуру работы с метриками в команде и их понимания следует вносить только после того, как в ней появится культура взаимопомощи и фокусировки на завершении работы. Иначе есть очень большой риск, что работа с метриками превратиться просто в поиск виноватых и взаимные претензии между членами команды. Работа с метриками — это не поиск виноватых, а решение проблем и взаимопомощь в команде
Вообще управление по метрикам — это отдельная компетенция. Она не является специфичной для Agile-методов, легко вспомнить концепцию KPI классического менеджмента. Но на ее примере как раз легко увидеть все проблемы, показывающие практическое отсутствие этой компетенции у большинства менеджеров.
Во-первых, реальное понимание способов работы встречается редко. Распространены примитивные рецепты, которые хорошо показывает анекдот про консультанта:
— Как сделать, чтобы моя ферма давала больше молока, а расходы на корма уменьшились?
— Очень просто, коров надо чаще доить и реже кормить!
Может показаться, что в анекдоте это утрировано, но известны примеры реальных приказов, которые предписывали медицинским работникам снизить смертность в своем регионе, чтобы привести ее к нормативной, без указания конкретных мер.
Во-вторых, очень сильна вера, что достаточно ввести метрики, то все исправится само. А чтобы все точно исправилось, надо просто связать KPI вознаграждение сотрудников — премии, бонусы, а иногда и штрафы, и все наладится само собой. И все, руководитель сделал такую систему — и может больше не думать, жажда полного автомата, вычисляющего зарплату по KPI — очень сильна. И, что интересно, те, кто в это не верят или из своего опыта знают, что так — не работает, очень часто наоборот, отвергают все метрики, объявляя их бездушным измерением, обесценивающим человека. И такое отрицание– третий вариант отсутствия компетенции работы с метриками.
Реально же метрики — это способ отражения текущей ситуации процесса компании. И повод задуматься, если что-то пошло не так. Чтобы было понятно, когда надо задуматься, метрики надо превратить в индикаторы, выяснив коридоры нормальных значений и предельные значения, как это делают с результатами анализов в медицине. При этом полезно применять светофорную модель, устанавливая желтую и красную зону. И в результате получить модель здорового течения процессов.
Приведем пример работы с интересной метрикой «дни касания». Мы берем общий срок, когда задача была в работе, и считаем, какой процент из этих дней задачи реально касались, для чего анализируем следы: записи в таск-трекере или изменения в коде, связанные с этой задачей. Естественно ожидать, что в хорошей ситуации над задачей работают ежедневно пока не сделают. Однако, при расчете реальных метрик часто оказывается, что задача очень долго ожидает выполнения в различных внутренних очередях, и коэффициент касания может составлять 50, 30 или даже 10%. О чем свидетельствует низкий коэффициент? О том, что задачи можно было бы делать гораздо быстрее без дополнительной работы, просто устранив задержки, и это повысит скорость потока. Но метрика тут служит лишь индикатором больного процесса, ведь человек не просто так откладывает задачу. Причины могут быть различны: срочные поручения руководства, ошибки и проблемы эксплуатации, ошибки тестирования ранее сделанного, ожидания внешних работ, ожидания согласований, прояснение постановки на задачу со стейкхолдерами и так далее. И нужен следующий такт анализа — выявить конкретные причины и провести работу по их системному устранению, для которого может потребоваться наладить сбор специализированных метрик, позволяющих различить причины задержки.
Отметим, что часть из перечисленных выше проблем представляют собой примеры тех или иных потерь (waste) в рабочем процессе, то есть работ, не несущих ценности: согласовать без необходимости, сделать оказавшееся ненужным, переделывать ранее сделанное и так далее. В IT-разработке и в любой другой интеллектуальной работе потери тоже присутствуют, как и в физическом производстве, просто они носят другой характер, поэтому производственный lean напрямую не применим. А задача метрик — наблюдать за ходом процесса и потерями, и служить сигналом, что какие-то из них превысили допустимый объем и требуют устранения.
Отмечу, кстати, что встречаются очень простые потери, связанные с незнанием приемов эффективной работы с текстами на компьютере. Наверное, все вспомнили про 10-пальцевую слепую печать. Это верно, но лишь отчасти: слепая печать очень актуальна, когда человек перепечатывает готовый текст, а это встречается относительно редко. В остальных случаях достаточно успевать вводить лишь со скоростью своей мысли. А вот владение hotkey, особенно при работе с буфером обмена для быстрого переноса текстов, чтобы не надо было переключаться на мышь — гораздо важнее. Почему-то на это не обращают должного внимания. А очень жалко наблюдать, как люди медленно делают то, что можно сделать гораздо быстрее… Впрочем, я отвлекся от рассказа про метрики.
Agile-методы предъявляют к метрикам и их визуализации особые требования: работа с ними перестает быть уделом избранных, а становится предметом заботы всех членов команды. А это означает наглядное представление, позволяющее быстро провести анализ ситуации по графикам, с тем, чтобы возникла эмпатия к графикам, подобная эмпатии к доске. Scrum решил такую задачу в частном случае, там придумали burndown chart.
В Kanban тоже есть несколько хороших визуальных представлений. Одно из них — кумулятивная диаграмма потока, на которой каждый день по вертикали откладывают число задач, находящихся на каждой стадии, как показано на рисунке. В результате по горизонтали мы можем увидеть, сколько времени в среднем занимает каждая фаза и, в том числе выделить непропорционально большие фазы, как это показано на приведенном примере диаграммы, на котором видно, что задачи очень долго отлеживаются на согласовании у CEO. Пример взят из уже упоминавшегося выше доклада Алексея Пименова на AgileDays-2019 «Скрытая механика работы Kanban Method».
Другая полезная диаграмма — частотная диаграмма. По горизонтали откладываем срок выполнения задач в днях, по вертикали — число таких задач. Диаграмму строим в разрезе классов обслуживания, выделенных в SLA. Если задачи в потоке однородны, то мы получим пуассоново распределение или его аналог. А вот если у полученного распределения есть несколько максимумов, то значит мы имеем дело с существенно неоднородным потоком задач. В этом случае имеет смысл провести анализ, чтобы научиться заранее разделять классы задач и с этой помощью улучшить предсказуемость их выполнения и учесть это в SLA. Потому что предсказуемость для бизнеса часто имеет гораздо большее значение, чем скорость.
Это все — конкретные примеры, и их можно приводить довольно долго. Но это именно примеры, а не универсальная система метрик. Конечно, было бы очень привлекательно получить именно универсальную систему, однако опыт развития IT говорит о том, что ее не существует. Однако, выработка системы метрик для конкретной компании или конкретной команды — вполне обозримая задача, есть много разных докладов на конференциях о конкретных системах метрик. И основную ценность в них представляет не конкретная система метрик, а логика, в которой к ней шли. Собственно, это — частное проявление пути Kanban: мы внедряем не конкретный процесс, а запускаем эволюционное развитие процесса, в данном случае — экспериментируя с разными метриками и индикаторами для повышения предсказуемости работы и мониторинга здоровья. На этом я закончу разговор метриках.
Каденции и синхронизация
Как известно, в Scrum со спринтом связан ряд встреч: daily scrum, планирование, демо, ретро, а помимо них есть и другие встречи, такие как story mapping для планирования релизов. Все они обеспечивают синхронизацию процесса и взаимодействие со стейкхолдерами. Как легко догадаться, эти функции являются необходимыми для организации потока создания ценности и должны быть выполнены при любом способе организации процесса. В Kanban для выполнения этих функций используются каденции — регулярные встречи, каждая из которых посвящена определенному вопросу и имеет свой собственный ритм, зависящий от соответствующего потока работы.
Выделяется семь типов каденций, связанных с различными фокусами внимания.
— Статус-митинг, как правило, ежедневный для обсуждения текущих задач и решений по заблокированным задачам.
— Пополнение списка задач — обсуждение, какие именно задачи сейчас являются наиболее приоритетны и должны быть включены в работу. Обычно раз в 1—2 недели.
— Планирование поставки — представление сделанного и передача результата клиентам
— Обзор качества сервиса и способов его улучшения.
— Операционная встреча по качеству взаимодействия со смежниками.
— Обзор рисков, связанных с блокировками выполнения задач и их влиянием на работу сервиса.
— Обзор и обновление стратегии.
Заметим, что все они в том или ином виде есть в Sсrum, только привязаны к спринту, за исключением последней.
Однако, Kanban не диктует, что в процессе обязательно должно быть семь описанных выше серий встреч. Набор конкретных встреч зависит от конкретных условий работы. Например, если команда взаимодействует с разными смежными подразделениями, например, юристами и HR по совершенно разным вопросам и в разном темпе, то это можно обсуждать на разных сериях встреч. Если подразделение предоставляет сервис нескольким разным клиентам с разными циклами поставки, то эти встречи могут проводиться независимо. Более того, далеко не все встречи необходимы. Например, по пополнению может быть принято решение, что каждый стейкхолдер ведет свой список срочных задач, а выбор задач для выполнения происходит по очереди, и специальная встреча назначается, только если этот порядок надо нарушить.
Таким образом, к описанному выше списку стоит относиться, скорее, как к списку важных фокусов, которые, как показывает опыт, стоит держать под контролем тем или иным образом. При этом, что важно, каждый из фокусов надо держать отдельно, и потому смешивать их на одной встрече не слишком желательно, даже если состав участников совпадает. Дэвид Андерсон в своей книге показывает, как эти механизмы возникали в его командах по мере эволюционного развития процесса, и как менялась их форма. Делать это в форме отдельных серий встреч — самый простой способ, но вовсе не обязательный. И в любом случае, встречи появляются постепенно, при чем порядок тоже может быть различен. Подробнее об этом узнать в докладе Алексея Пименова на AgileDays-2018 «Канбан! Что новенького?» В отличие от его доклада на AgileDays-2019, на который я ссылался в начале статьи, этот дает обзор новых техник и рассчитан на более глубокий уровень слушателя.

Масштабирование
Первоначально Kanban-система часто проектируется и внедряется для отдельного подразделения, выбранного в качестве пилотной площадке. Далее она может распространяться на смежные подразделения по цепочкам создания ценности, а также вверх на компанию, для организации потока ценности в целом.
Существует и другой способ внедрения, применяемый в ситуации, когда каждое подразделение работает более-менее нормально, однако в целом поток создания ценности буксует на взаимодействии между ними. В этом случае внедрение может быть начато сверху, для получения крупной картины, и для начала проявлена передача крупных задач между подразделениями и их взаимодействие. Способ работы отдельных подразделений и команд при этом может быть сохранен. Такая конструкция может применяться, в частности, для оркестрации работы отдельных Scrum-команд, если из них выстроены длинные цепочки создания ценности с взаимными зависимостями.
Отметим, что при масштабировании Kanban-системы на компанию в целом или на автономные бизнес-единицы помимо метрик, показывающих прохождение потока задач становятся актуальными метрики, показывающие финансовые результаты деятельности. Естественным желанием является взять готовую систему стандартных финансовых метрик. Засада в том, что не всякая система метрик является совместимой с теорией ограничений, которая лежит в основе Kanban. Это подробно разобрано в книге Томаса Корбета «Учёт прохода. Управленческий учет по теории ограничений» (оригинал называется «Throughput accounting», есть русский конспект). И может получиться, что оптимизация потока оценивается метриками и KPI негативно. Эту опасность необходимо представлять, и выбирать метрики правильно.
На встречах по анализу процесса, на основе анализа метрик выполняется выявление проблем и поиск способов их решения. При этом предпочтение отдается эволюционному пути: если есть проблема во взаимодействии двух подразделений, то для начала стоит наладить коммуникацию по рабочим вопросам и регулярный анализ взаимоотношений. Но если проблема носит системный характер, то, возможно, стоит подумать о перестройке цепочек создания ценности с переходом от длинных цепочек к коротким, о котором я писал в предыдущей главе.
Фреймворки масштабирования Agile на компанию
Ячейкой организации в любом случае является автономная самоорганизующаяся Agile-команда, поэтому совместимость способов управления с Agile-культурой является принципиальным требованием. Опыт показывает, что многие подходы менеджмента, основанные на уважении авторитета руководителя, полагаемого безусловным, или следовании за непогрешимым лидером не выдерживают столкновения с Agile-культурой: сотрудники могут просто уйти целой командой. И если руководство привыкло к такому стилю управления, то в Agile нет никакого смысла. С другой стороны, как я говорил в главах «Три вызова цифрового мира» и «Цифровой мир: от физического труда — к умственному» методы регулярного менеджмента в цифровом мире перестают работать, а Agile-методы являются одной из работающих альтернатив, что подробно рассмотрено в главе «Agile — ответ IT на вызовы цифрового мира».
Фреймворки имеют разную сложность и рассчитаны на компании или подразделения разного размера. При этом большинство из них рассчитано на короткие цепочки создания ценности, когда одна кроссфункциональная команда делает продукт, поставляемый потребителям. Как я писал в главе «Место Agile-команд в компании», в условиях неопределенности и быстрого изменения условий работы компании в VUCA-мире короткие цепочки являются естественным способом организации труда, способным быстро реагировать на изменения, в отличие от стабильных условий функционирования, которые ведут к специализации и образованию длинных цепочек из функциональных подразделений.
Большинство фреймворков, о которых я буду говорить, ориентированы на обеспечение только основной операционной работы компании. Однако, следует учитывать, что границы ответственности команд могут быть существенно различны. Достаточно распространенной является практика, когда в ответственность команд передается найм и увольнение сотрудников, их обучение, а также финансовая ответственность за создаваемый продукт, то есть команда становится независимым подразделением. В других случаях HR остаются независимым подразделением, так же как бухгалтерия и юридическая служба, и тогда их работа может быть организована как сервисная инфраструктура для команд, работающая по Kanban или одним из гибридных Agile-методов. Сохранение традиционной организации тоже возможно, однако, важно обеспечить хорошее качество сервиса и не служить препятствием для движения команд основного операционного контура. И перед тем, как перейти к обзору фреймворков я хочу порекомендовать доклад Асхата Уразбаева «Фреймворки масштабирования Agile» на SECR-2017 со сравнением разных фреймворков.

Простые фреймворки: Scrum of Scrum, Nexus, LeSS
Начну я с наиболее простого Scrum of Scrums, который появился раньше других. Он применяется в случае, если у вам в компании есть независимые Scrum-команды, каждая из которых делает свой продукт. Тогда для работы надо общими вопросами достаточно собрать команду Product Owner для обсуждения стратегии развития продуктов и координации усилий, и команду Scrum Master для обсуждения и координации вопросов организации. Если в командах есть Tech Lead, отвечающий за технологии и обучение им сотрудников, то добавляется еще координирующая команда из них. Однако, бывают ситуации, когда одна команда не может обеспечить развитие продукта в требуемой темпе, ее мощности не хватает. Ведь размер команды ограничен, эффективно работает команда в 7—9 человек, а если их становится сильно больше, то необходимо дополнительное структурирование. Есть относительно простой способ нарастить команду до 15—20 человек, представленный на схеме. Это конструкция из мини-команд, каждая из которых состоит из опытного сотрудника и 1—2 стажеров, для которых опытный является наставником для стажеров. При этом операционные вопросы взаимодействия решаются командой из руководителей мини-команд.
Другой относительно простой способ — это собрать Integration Team из представителей отдельный команд, которая будет решать вопросы координации и зависимостей. Это предлагает Nexus и достаточно в случае, когда зависимости являются достаточно слабыми.
Более сложный фреймворк — Large Scaled Scrum (LeSS) (русское описание) — несколько команд на одном продукте с общим Product Owner, BackLog, спринтами, планированием, демо и поставкой, это позволяет объединить до 8 команд. У фреймворка есть huge вариант, применяемый для больших компаний и рассчитанный на работу 1000+ человек.
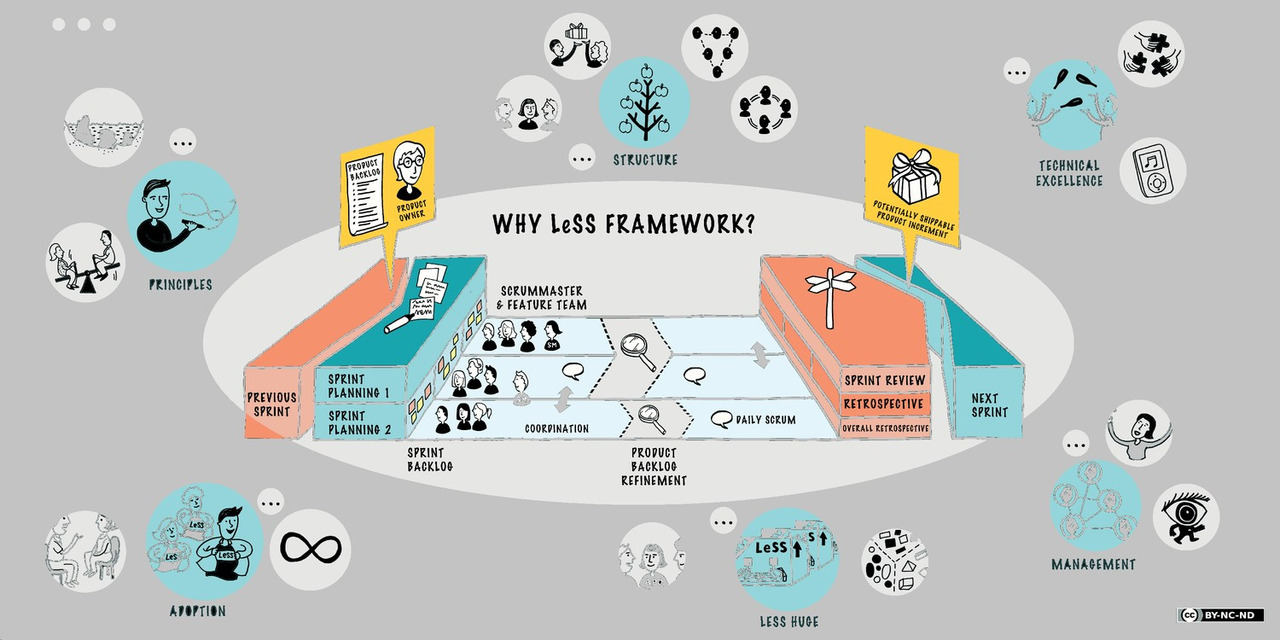
Spotify
Ответственность команды не ограничивается выполнением основных производственных задач, она имеет много планов и фокусов, и логично, когда это реализуется через отдельные организационные структуры. Это мы видели на примере Scrum of Scrum, который организует две структуры управления — продуктовую и организационную, иногда дополняемую третьей, технологической. Более сложной конструкцией является Spotify фреймворк, который заслуживает отдельного рассмотрения.
Основной производственной единицей в ней является клан (tribe) в 100—200 человек, который работает над отдельным продуктом. Он представляет собой матрицу: делится на кроссфункциональные производственные отряды (squad) и функциональные отделы (chapter). Отряды реализуют новый функционал и состоят из специалистов разных специализаций, которые дополняют друг друга. А отделы координируют работы специалистов из разных команд, использующих общие технологии, решая такие задачи, как разработка мобильных интерфейсов в едином стиле, однородная работа серверной части или развитие технологий тестирования. Отметим, что отделы работают над применением технологий в рамках продукта, а вот для развития технологий в целом по компании существуют еще гильдии (guild) по интересам. По мере роста компании над кланами появились структуры следующего уровня — альянсы (alliance) и бизнес-единицы (business unit).
Конструкция — очень сложная и многоплановая и во многом обусловленная контекстом компании. Spotify ей делится, но с предостережением: «используйте наши опыт, но не пытайтесь тупо скопировать, оно не взлетит, мы это точно знаем, потому что у нас самих конструкция развивается и растет». Но много попыток именно механического копирования, обычно неудачных. А вот идеи заложены плодотворные.
При этом в самой компании Spotify организационная структура развивается очень быстро. И я хочу интересующимся порекомендовать доклад Yuliya Kurapatenkava на Saint TeamLeadConf-2018, в котором она рассказывала про логику развития (мой конспект есть в отчете с конференции, а сам доклад по-английски). И вы можете сравнить то, что звучит в докладе с тем описанием фреймворка, которое доступно по ссылке в начале раздела и фиксирует состояние несколько лет ранее.

Пересборка организации
Здесь стоит рассмотреть практическое применение подобных фреймворков. Один продукт, над которым работают несколько команд, далеко не всегда означает единственный продукт в смысле софта, более того, часто речь идет об одном бизнес-продукте, поддержка которого со стороны софта требует общей серверной части и нескольких приложений на разных платформах — web и мобильных. Естественным образом для того, чтобы какой-то новый функционала стал доступен конечным пользователям, он часто должен быть реализован в серверной части и для каждой из платформ. И тут может быть два подхода: сделать команды, каждая из которых сосредоточенна вокруг каждого софтверного продукта, при этом только она работает с кодовой базой продукта и отвечает за его архитектуру. В этом случае для организации могут применяться фреймворки, подобные LeSS.
Однако, то что задача по реализации нового функционала делится на несколько, каждую из которых выполняет своя команда, сильно увеличивает количество необходимых синхронизаций и время разработки. Поэтому часто применяется и другой способ организации, кросс-функциональные команды, включающие специалистов по всем приложениям и делают все доработки для новой фичи. При этом возникает общее владение кодом, и надо дополнительно принимать меры для удержания целостности архитектуры каждого приложения, а также обучения и передачи опыта, потому что внутри команды такие специалисты не могут учиться. И это получается структура, похожая на клан в Spotify.
Так вот, в зависимости от потока задач и этапа развития компании предпочтительная структура может сильно изменяться. И сейчас IT-компании умеют достаточно быстро и успешно перестраивать свою структуру в зависимости от потребностей развития продукта. Я хочу сослаться на опыт ivi. На TeamLeadConf-2018 Евгений Россинский рассказывал как они обеспечивали целостность продуктов и поддерживали знания разработчиков при переходе к кроссфункциональным командам от команд, собранных вокруг отдельных приложений. А через год TeamLeadConf-2019 он же рассказывал как за год они для решения задач реинжиниринга ядра продукта вернулись к командам, организованным по приложениям, провели реинжиниринг, а затем — снова перешли к кросс-функциональным командам. Компания ivi предоставляет чистый цифровой продукт. Однако, похожая бизнес-структура сейчас характерна и для банков и для туроператоров, потому что их продукты сейчас все больше и больше перемещаются в цифровую сферу. Но, насколько я знаю, быстро пересобираться таким образом они еще не умеют, да и для IT опыт ivi является передовым. И, думаю, это может дать хорошее представление о том, какова она — динамично развивающаяся и перестраивающаяся современная цифровая компания, насоклько быстро она умеет изменяться.
Сложные фреймворки — SAFe и Enterprise Scrum
Scaled Agile Framework (SAFe) является самым сложным Agile-фреймворком, но при этом — самым популярным. Это сложная конструкция уровня компании с управлением потоками создания ценности и архитектурой. На мой взгляд, популярность этого фреймворка сродни популярности PMBOK или RUP — в нем есть все и на все случаи жизни, и предлагается просто взять нужное. Кстати, автором фреймворка является Дин Леффингуэлл (Dean Leffingwell), один из авторов RUP.
И, на мой взгляд, это — неработоспособная конструкция, хотя и привлекательная в своем инженерном совершенстве. Фреймворк не будет работать по тем же самым причинам — его сложность превышает разумный предел, при этом обвинить сам фреймворк будет невозможно, всегда окажется, что это вы не смогли его правильно реализовать. И дело не только в сложности фреймворка: SAFe пытается за счет сложных регламентов превратить запутанную область в сложную, а это — невозможно. Подробнее о сложности областей — в описании Кеневин-фреймворка в главе «Место Agile-команд в компании».
Вместе с тем, в силу популярности и привлекательности есть много проектов внедрения SAFe. B эти проекты часто несут позитивный эффект, как и многие проекты внедрения проектного управления. В процессе внедрения компания разбирается с тем, как устроены ее цепочки создания ценности. Таким образом, появляется структурированное описание деятельности компании, при чем не на уровне процессов, а через цепочки создания ценности, что представляет собой значительное методологическое продвижение вперед.
Другая выгода, общая для внедрения большинства Agile-фреймворков — разрушение застывшей бюрократической структуры, разморозка коммуникаций и инициативы в компании. Но она часто уже достигнута, так как до глобальной реорганизации компании через внедрения SAFe следует этап внедрения Scrum или других Agile-методов на уровне отдельных команд. Впрочем, уровень отдельных команд в SAFe тоже специфицирован, там как раз Scrum или Kanban, а вот над ними — несколько уровней управления компанией.
Довольно интересен фреймворк Enterprise Scrum предлагает переход от создания IT-продукта к поставке ценности, управляемой набором связанных метрик. К сожалению, в отличие от всего остального он не завершен. Его создатель Mike Beedle, кстати, один из авторов Agile-манифеста был, к сожалению убит в Чикаго весной 2018 года, и работа не завершена. Однако, на сайте есть достаточно подробная конструкция системы метрик, совместимая с Agile-методами управления, и, возможно, она вам окажется полезной при конструировании собственной, хотя в готовом виде ее, естественно, брать не стоит.
Кейсы Agile-трансформации.
Часть 1 — банки
По опыту лекций об Agile в разных аудиториях, рассмотрение кейсов Agile-трансформации вызывает большой интерес слушателей. В том числе — таких известных, как Agile в Сбербанке или Альфа-банке, хотя, казалось бы, об этом можно найти много публичных материалов. Причина, думаю, в том, что хорошие системные материалы погребены под большим количеством попсовых изложений, которые не раскрывают суть, а иногда ее искажают. Поэтому я начинаю рассказ о кейсах, чтобы в совокупности дать многовариантную картину. Сейчас речь пойдет о трансформации банков, причем не IT-подразделений, а работы бизнеса в целом.
Бесплатный фрагмент закончился.
Купите книгу, чтобы продолжить чтение.