
Бесплатный фрагмент - Компьютерное зрение в лучевой диагностике: первый этап Московского эксперимента
Монография. 2-е издание, переработанное и дополненное
Научные редакторы: Ю. А. Васильев, А. В. Владзимирский
Авторы: Ю. А. Васильев, А. В. Владзимирский, К. М. Арзамасов, А. Е. Андрейченко, В. А. Гомболевский, Н. С. Кульберг, О. В. Омелянская, Н. А. Павлов, Р. В. Решетников, К. А. Сергунова, Д. Е. Шарова, И. М. Шулькин
Организаторы и активные участники первого этапа (2019—2020 гг.) Эксперимента (сотрудники ГБУЗ «НПКЦ ДиТ ДЗМ» и медицинских организаций ДЗМ): Е. С. Ахмад, Р. Н. Ахметов, А. С. Бардин, Е. Г. Бахтеева, И. А. Блохин, О. С. Бухтиярова, Р. И. Волошин, Е. В. Дмитриева, В. А. Дроговоз, С. О. Ермолаев, Д. И. Живоглядов, В. С. Живоденко, С. М. Зайцева, Г. В. Иванова, Е. М. Ильина, С. Г. Киреев, Т. Г. Киреев, Ю. С. Кирпичев, В. Г. Кляшторный, Д. Ю. Кокина, Е. М. Корепина, Н. Д. Кудрявцев, Е. С. Кузьмина, Д. А. Курятников, Н. В. Ледихова, Т. А. Логунова, М. Ю. Малова, В. И. Мельников, Ю. Е. Мешалкин, О. А. Мокиенко, С. П. Морозов, Е. Л. Морозова, А. Н. Мухортова, Ю. В. Никишова, В. П. Новик, В. А. Нуждина, Е. В. Панина, А. В. Петряйкин, Н. С. Полищук, Е. В. Попов, В. Г. Раковчен, А. А. Ревазян, Л. Г. Родионова, С. С. Семенов, А. В. Слепушкина, И. В. Смирнов, И. В. Солдатов, Е. С. Соломатина, А. В. Титова, И. А. Трофименко, Е. В. Туравилова, А. В. Усков, С. С. Федоров, А. Н. Хоружая, С. Ф. Четвериков, Н. В. Шипилова
Технический редактор А. И. Овчарова
Компьютерная верстка Е. Д. Бугаенко
ПРЕДИСЛОВИЕ
В ноябре 2019 года Указом Президента Российской Федерации утверждена Национальная стратегия развития искусственного интеллекта на период до 2030 года. Искусственный интеллект должен внести колоссальный вклад в реализацию приоритетных направлений научно-технологического развития России. Одним из таких направлений стало создание условий для улучшения уровня жизни населения за счет повышения качества услуг в сфере здравоохранения, включая профилактические обследования, диагностику, прогнозирование возникновения и развития заболеваний, подбор оптимальных дозировок лекарственных препаратов, сокращение угроз пандемий, автоматизацию и повышение точности хирургических вмешательств.
Как подчеркивается в Национальной стратегии стремительное развитие технологий искусственного интеллекта сопровождается существенным ростом как государственных, так и частных инвестиций в их развитие и разработку прикладных технологических решений. Громадный интерес и значительные потоки средств не должны быть расходованы безрезультатно. Критично важно сформировать адекватный, эффективный, справедливый рынок. Важно наладить коммуникации между индустрией информационных технологий, компьютерных наук и сферой здравоохранения, клинической медициной. Разработать общие правила, стандарты, которые бы в равной степени отвечали потребностям и признавались бы всеми заинтересованными сторонами. Критично необходима методическая поддержка разработчиков, ведь «механический» перенос принципов разработки искусственного интеллекта из промышленности или транспорта на медицину невозможен.
Залогом формирования рынка, прежде всего, служит создание спроса. Это означает необходимость научных исследований по трансформации диагностических и клинических процессов медицинских организаций на основе технологий искусственного интеллекта. Важно научно проверить гипотезы о том, как действительно автоматизация влияет на качество, производительность труда в здравоохранении; как помогает быстрее и точнее ставить диагноз, назначать и осуществлять лечение. Понимание трансформации производственных процессов позволит создать новые медицинские услуги, оказываемые с применением технологий искусственного интеллекта. Не исключая врача, но дополняя и усиливая его возможности, а также — повышая эффективность и производительность всей системы здравоохранения.
Безусловно, формирование рынка крайне важно для развития экономики столицы и государства, но не является самоцелью. Развитие искусственного интеллекта должно изменить способы и качество оказания медицинских услуг. Автоматизация может освободить медицинский персонал от рутинных, повторяющихся действий, чреватых дефектами и рисками. Вместо этого, врачи и медицинские сестры смогут физически больше времени уделять общению с пациентами, широко и полноценно используя клиническое мышление принимать сложные решения, недоступные компьютерам. Выполнение отдельных функций искусственным интеллектом позволит сократить время ожидания медицинской помощи, например — ускорит предоставление гражданам результатов диагностических исследований. Автоматизированный контроль не допустит ошибок в назначениях или маршрутизации, а значит медицинская помощь станет более безопасной.
Особенность состоит в том, что для медицины нужна не только разработка технологий, но и их всесторонняя научная оценка.
Научный подход к развитию искусственного интеллекта в здравоохранении не только дополняет экономические и инженерно-технические его аспекты, но, прежде всего, создает основу для безопасности пациента. Цена ошибки или неточности в медицине критично высока. Поэтому неукоснительным требованием к любой новой технологии в здравоохранении является безвредность для пациента. Полномасштабное обеспечение безопасности при применении новых технологий обеспечивается научными исследованиями на принципах доказательной медицины.
В целях реализации Национальной стратегии уже в ноябре 2019 года Правительство Москвы обеспечило организацию и проведение крупнейшего в мире научного исследования искусственного интеллекта в медицине — Эксперимента по использованию инновационных технологий в области компьютерного зрения для анализа медицинских изображений и дальнейшего применения в системе здравоохранения города Москвы.
Эксперимент направлен на получение знаний об эффективной и безопасной трансформации производственных процессов медицинских организаций на основе искусственного интеллекта. На их основе формируются условия для эффективного взаимодействия государства (органов исполнительной власти, регуляторов), медицинских и научных организаций, бизнеса и индустрии, а также граждан. Это позволит российским технологиям искусственного интеллекта занять значительную долю мирового рынка, значительно повысив качество и безопасность медицинской помощи.
РЕЦЕНЗЕНТЫ
Нуднов Николай Васильевич — д.м.н., профессор, заместитель директора по научной работе, заведующий НИО комплексной диагностики заболеваний и радиотерапии ФГБУ «Российский научный центр рентгенорадиологии» Минздрава России
Лебедев Георгий Станиславович — д.т.н., профессор, директор Института цифровой медицины, заведующий кафедрой информационных и интернет-технологий ФГАОУ ВО «Первый Московский государственный медицинский университет им. И. М. Сеченова» Минздрава России (Сеченовский Университет)
БЛАГОДАРНОСТИ
Авторы монографии выражают искреннюю благодарность и глубочайшее профессиональное уважение руководителям и сотрудникам Департамента здравоохранения города Москвы, Департамента информационных технологий города Москвы, медицинских организаций государственной системы здравоохранения города Москвы, членам Междисциплинарной рабочей группы по разработке и внедрению системы поддержки врачебных решений на этапе первичной диагностики и лечения: Агафоновой Олесе Алексеевне, Антиповой Анне Михайловне, Барышову Владимиру Ивановичу, Бойко Светлане Валентиновне, Вакуленко Елене Анатольевне, Васильевой Вере Игоревне, Вдовиной Александре Евгеньевне, Григель Вере Владимировне, Гулиевой Марии Ахадовне, Гуревичу Александру Борисовичу, Иманбердиной Айман Толеповне, Летучиной Татьяне Александровне, Лобанову Михаилу Николаевичу, Мокиенко Олесе Александровне, Никитину Борису Сергеевичу, Никишовой Юлии Вячеславовне, Пермогорской Анне Сергеевне, Поливанову Гайку Эдуардовичу, Самбурскому Станиславу Евгеньевичу, Смирновой Евгении Игоревне, Соколиной Ирине Александровне, Стецюк Лидии Дмитриевне, Трофимовой Марине Владимировне, Хомякову Александру Константиновичу, Хохловой Ирине Вячеславовне, Шепелевой Елене Николаевне, а также всем сотрудникам ГБУЗ «НПКЦ ДиТ ДЗМ» г. Москвы, всем замечательным коллегам, благодаря которым успешно стартовал первый в мире эксперимент по применению технологий искусственного интеллекта в лучевой диагностике.
Авторы
ГЛОССАРИЙ
АНАЛИТИЧЕСКАЯ ВАЛИДАЦИЯ — оценка корректности обработки входных данных программным обеспечением для создания надежных выходных данных; оценивается с применением эталонных наборов размеченных данных.
ИИ-СЕРВИС — программное обеспечение на базе технологий компьютерного зрения, предназначенное для анализа медицинских изображений и предоставляемое юридическим лицом (разработчиком или имеющим право на предоставление).
ИСКУССТВЕННЫЙ ИНТЕЛЛЕКТ (ИИ) — комплекс технологических решений, позволяющий имитировать когнитивные функции человека (включая самообучение и поиск решений без заранее заданного алгоритма) и получать при выполнении конкретных задач результаты, сопоставимые, как минимум, с результатами интеллектуальной деятельности человека. Комплекс технологических решений включает в себя информационно-коммуникационную инфраструктуру, программное обеспечение (в том числе то, в котором используются методы машинного обучения), процессы и сервисы по обработке данных и поиску решений.
КЛИНИЧЕСКАЯ АПРОБАЦИЯ — оценка эффективности медицинского изделия (в данном контексте — программного обеспечения) путем использования в рамках стандартного производственного процесса. Состоит из двух компонентов: клинической корреляции и клинической валидации.
КЛИНИЧЕСКИЕ ИСПЫТАНИЯ — разработанное и запланированное систематическое научно-практическое исследование, предпринятое для оценки безопасности и эффективности медицинского изделия.
КЛИНИЧЕСКИЙ КОНТЕКСТ ПРИМЕНЕНИЯ ТЕХНОЛОГИЙ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА — единый комплекс специфической базовой информации для осознанного и эффективного применения конкретной технологии искусственного интеллекта в практическом здравоохранении, в том числе включающий цель, задачи (запросы), конкретные процессы и операции, нозологии, виды данных, функции, способы и формы представления результатов анализа, измеримые метрики качества.
КОМПЬЮТЕРНОЕ ЗРЕНИЕ — технология искусственного интеллекта для формирования полезных выводов относительно объектов и сцен реального мира на основе анализа изображений, полученных с помощью датчиков.
НАБОР ДАННЫХ — совокупность данных, прошедших предварительную подготовку (обработку) в соответствии с требованиями законодательства РФ об информации, информационных технологиях и о защите информации и необходимых для разработки программного обеспечения на основе искусственного интеллекта.
НАБОР ДАННЫХ ВЕРИФИЦИРОВАННЫЙ — это эталонный набор данных для обучения или тестирования алгоритмов искусственного интеллекта, подготовленный проспективно и содержащий данные из медицинской документации об окончательном и/или патологоанатомическом диагнозе.
ОБЪЯСНИМЫЙ ИИ — (от англ. explainable AI), функциональная возможность программного обеспечения на основе технологий ИИ объяснить/интерпретировать свое решение и степень уверенности в этом решении человеку.
ПОДГОТОВКА ДАННЫХ — процесс выгрузки структурированных и неструктурированных данных из медицинских информационных систем по заданным критериям (фильтрам).
РАЗМЕТКА ДАННЫХ — этап обработки структурированных и неструктурированных данных, в процессе которого данным (в том числе текстовым документам, фото- и видеоизображениям) присваиваются идентификаторы, отражающие тип данных (классификация данных), и (или) осуществляется интерпретация данных для решения конкретной задачи, в том числе с использованием методов машинного обучения.
ТЕХНИЧЕСКИЕ ИСПЫТАНИЯ — разработанное и запланированное исследование соответствия характеристик медицинского изделия требованиям нормативной документации, технической и эксплуатационной документации производителя и принятия последующего решения о возможности проведения клинических испытаний.
ТЕХНОЛОГИИ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА — технологии, основанные на использовании искусственного интеллекта, включая компьютерное зрение, обработку естественного языка, распознавание и синтез речи, интеллектуальную поддержку принятия решений и перспективные методы искусственного интеллекта.
СПИСОК СОКРАЩЕНИЙ
АРМ — автоматизированное рабочее место врача.
БД — база данных.
ГБУЗ «НПКЦ ДиТ ДЗМ» — государственное бюджетное учреждение здравоохранения города Москвы «Научно-практический клинический центр диагностики и телемедицинских технологий Департамента здравоохранения города Москвы».
ДЗМ — Департамент здравоохранения города Москвы.
ДУ — диагностическое устройство.
ЕМИАС — Единая медицинская информационно-аналитическая система.
ЕРИС — Единый радиологический информационный сервис.
ЕСУВВ — подсистема ЕМИАС, Единая система уведомлений для внешних взаимодействий.
ЗНО — злокачественное новообразование.
ИИ — искусственный интеллект.
ИО — истинно отрицательный.
ИП — истинно положительный.
ИТ — информационная технология или интеллектуально-технологический.
КЗ — компьютерное зрение.
КТ — компьютерная томография.
КТТ — контрольно-техническое тестирование.
ЛО — ложноотрицательный.
ЛП — ложноположительный.
ММГ — маммография.
МО — медицинская организация.
МРТ — магнитно-резонансная томография.
НДКТ — низкодозная компьютерная томография.
ОЛД — отделение лучевой диагностики.
ПКТИ — предварительные клинико-технические испытания.
ПО — программное обеспечение.
ППАК — продуктивный программно-аппаратный комплекс, продуктивная среда ЕРИС.
ПУМ — подсистема ЕМИАС, продукт управления моделями.
ПЭТ/КТ — позитронно-эмиссионная компьютерная томография.
РИС — радиологическая информационная система.
РГ — рентгенография.
РЛ — рак легкого.
РФ — Российская Федерация.
ТПАК — тестовый программно-аппаратный комплекс, тестовая среда ЕРИС.
ФЛГ — флюорография.
AUC — англ. Area Under Curve; площадь под характеристической кривой.
CAD — англ. Computer-Aided Detection and Diagnosis system; программное обеспечение, система компьютерного обнаружения и диагностики.
CE — фр. Conformité Européenne; маркировка «европейское соответствие».
CONSORT — англ. Consolidated Standards of Reporting Trials; диаграмма потока участников исследования.
DICOM — англ. Digital Imaging and Communication in Medicine; Международный стандарт создания, хранения, визуализации и передачи медицинских файлов, которые хранят информацию о проведенных исследованиях. В данном документе под этими файлами подразумеваются файлы исследований, включающих цифровые медицинские изображения, сформированные на оборудовании в отделениях лучевой диагностики, документы пациентов и протоколы хранения/передачи информации.
FDA — англ. Food and Drug Administration; Управление по санитарному надзору за качеством пищевых продуктов и медикаментов США.
PACS — программное обеспечение, система передачи и архивации медицинских изображений.
ROC — англ. Receiver Operating Characteristic; характеристическая кривая.
ВВЕДЕНИЕ
Чем грандиознее идея и ее польза,
тем слабее бывает первое исполнение.
Причина понятна.
Это — трудность ее реализации.
Константин Эдуардович Циолковский
Искусственный интеллект (ИИ). Всего несколько лет назад это словосочетание буквально потрясло мир лучевой диагностики. «Робот заменит врача!», «Радиология исчезает!», «Безработные врачи заполнят улицы!» — каких только лозунгов и предвидений не довелось услышать. Тысячи инженеров и математиков по всему миру вдруг бросились создавать стартапы для разработки очередного «искусственного интеллекта», в надежде лишить непонятно, чем провинившихся рентгенологов куска хлеба. Транснациональные вендоры диагностической аппаратуры, неторопливо оглядевшись с высоты своего положения, побежали вдогонку, наверстывая упущенное. Появились разнообразные «экосистемы» и «платформы» для совместной работы разработчиков и врачей. Рекой потекли инвестиции — для наиболее быстрых аббревиатура «AI» в названии гипотетического продукта стала залогом получения финансовых средств (впрочем, это продолжалось недолго). Под напором ИТ-индустрии врачи «ушли в глухую оборону», поглядывая на происходящее со стороны, иногда иронично, иногда нервно, но чаще всего — безучастно. Тем не менее на сотнях научных конференций по всему миру закипели дискуссии. Визионеры рассказывали с трибун о грядущей роботизации лучевой диагностики. Прагматики требовали предъявить работающие технологии. Популисты публиковали в социальных сетях свои рассуждения.
Что же послужило причиной такого взрывного интереса и кипучей активности? Идею усиления человеческого разума за счет возможностей особых «интеллектуальных машин» сформулировал в 1832 году ветеран Наполеоновских войн, чиновник Министерства внутренних дел Семен Николаевич Корсаков (1787–1853). В своем потрясающем труде, основанном на принципах механистического материализма, Семен Николаевич предложил пять «машин, сравнивающих идеи», а еще — перфокарты, метод многокритериального поиска с использованием весовых коэффициентов и первый способ обработки больших данных (предтечу современных алгоритмов). Увы, блестящие открытия не прошли строгого рецензирования академиков того времени и почти на сто лет были забыты. Лишь с развитием кибернетики Норберта Виннера, Сергея Соболева, Виктора Глушкова и многих других ученых вновь вспомнились идеи «интеллектуальных машин».
В 1950 году английский математик Алан Тьюринг (1912–1954) впервые систематизировал рассуждения на тему возможности машинного мышления и предложил тест, позволяющий различить (или не различить) результаты интеллектуального труда машины и человека. Впрочем, в своих трудах Тьюринг, по-видимому, опирался на идеи философа Алфреда Айера, писавшего об эмпирических тестах для поиска различий между «разумным существом» и «глупой машиной» для определения «наличия или отсутствия сознания». В 1956 году американский ученый Джон Маккарти (1927–2011) предложил термин «искусственный интеллект» как резюме двухмесячной дискуссии на тему, возможно ли моделировать рассуждения, интеллект и творческие процессы с помощью вычислительных машин. При этом под интеллектом понималась только «вычислительная составляющая способности достигать целей в мире». В дальнейшем периоде времени кибернетика, философия и инженерия шли разом, создавая компьютеры, алгоритмы, языки программирования, а «искусственный интеллект» стал отдельной научной дисциплиной.
Но причем же здесь медицина? Достаточно быстро — примерно к началу 1970-х годов — появились компьютерные технологии анализа медицинских данных. Наибольшей эффективностью отличались средства автоматизированного анализа электрокардиографических (ЭКГ) исследований. Были разработаны нужный математический аппарат, принципы алгоритмизации анализа, создан ряд программных продуктов, часть из которых даже применялась в контексте коммерческих услуг по дистанционной автоматической расшифровке, а также — в рамках космических программ.
В СССР наибольший вклад в развитие «вычислительной ЭКГ-диагностики» внесли Юрий Исаакович Неймарк (1920–2011) и Александра Петровна Матусова (1919–2010), в США — Цезарь Касерес (1927–2020). Примерно через 10 лет появились «экспертные системы» — это были первые попытки создать автоматизированные системы поддержки принятия врачебных решений (СППВР). В научных журналах 80-х годов ХХ века можно найти большое количество публикаций на эту тему. Экспертные системы были предложены для множества дисциплин — кардиологии, хирургии, эндокринологии, нейрохирургии и т. д. Однако значительного, действительно масштабного развития эти СППВР не получили, так как основывались на жестких правилах. Фактически в основе их алгоритмов лежали структурированные «деревья решений»; они могли быть очень обширными, но предсказуемыми и полностью статичными. Обучаться или предлагать нетривиальные подходы эти системы еще не умели. Интерес к автоматизированному анализу медицинских данных резко снизился. Этот период иногда называют «зимой ИИ». Но в конце 1990-х — начале 2000-х гг. началась «весна». Своим возрождением ИИ обязан новому математическому аппарату — искусственным нейронным сетям — и стремительному наращиванию вычислительных возможностей компьютерных технологий.
Для создания алгоритмов на основе нейронных сетей сформировались способы обучения соответствующих моделей, в том числе — машинное, глубинное и проч. Появилась техническая возможность создавать алгоритмы для быстрой обработки огромных массивов данных в условиях низкой определенности; причем такие алгоритмы могут дообучаться и работать на обычных персональных компьютерах. Вот тут-то на медицину и обрушилась волна искусственно создаваемого ажиотажа. И первый ее удар приняла именно лучевая диагностика. Для разработчиков ИИ здесь все было очевидно:
— врач смотрит на снимок и ставит диагноз — значит алгоритм может сделать эту работу за человека;
— рентгенограмм и томограмм делают много — значит продукт на основе алгоритма будет востребован.
Данные тезисы звучали логично, а главное — выглядели очень простыми по сравнению со сложными комбинациями симптомов и десятков лабораторных показателей, которые нужно анализировать, например, для прогноза сепсиса или коронарного синдрома. Увы, такая логичная и простая конструкция полностью оказалась оторванной от жестких реалий настоящей медицины.
Вдоволь наслушавшись прогнозов и угроз, врачи подошли к новой проблеме стандартным прагматичным путем — с позиций медицинской науки и доказательной практики. Для автоматизированного анализа, как и для любого иного метода/средства/технологии в здравоохранении, должны быть научным путем доказаны: безопасность, эквивалентность существующим аналогам, эффективность (превосходство над существующими аналогами). По установленным правилам и принципам научных исследований должны быть обеспечены методологические возможности для практического применения технологий автоматизированного анализа медицинских данных. Все перечисленное обусловило формирование искусственного интеллекта в качестве объекта профессиональных научных исследований.
Диалектические единство и борьба противоположностей в отношении медицинского искусственного интеллекта наглядно иллюстрируются двумя цитатами. Сооснователь стартапа в области онлайн-обучения «Coursera» и профессор технологий машинного обучения Эндрю Ын утверждает: «Предприниматели XIX века в короткие сроки поставили электричество на службу человечеству, чтобы тот мог готовить пищу, освещать помещения и приводить в действие промышленное оборудование. Точно также современные предприниматели ставят на службу человеку машинное обучение и искусственный интеллект». Это ярко демонстрирует решительность и быстроту действий ИТ-индустрии.
Но как ярко и четко возражает (возражает ли?) ему врач-радиолог и медицинский блогер Хью Харви: «Если вы планируете инвестировать в ИИ, то выбирайте компании, которые сосредоточены на решении клинически значимой проблемы, обладают значительным объемом верифицированных клинических данных, нацелены на получение регистрации продукта как медицинского изделия и не чрезмерно распиарены. Все остальное — хайп». Данное выражение подчеркивает взвешенность и системность со стороны сферы здравоохранения. Обе отрасли (здравоохранение и ИТ-индустрию) роднит целеустремленность, вот только цели у всех в этом процессе разные.
После 2010 года стало появляться все больше научных статей, посвященных не только теории, но и практике применения искусственного интеллекта в здравоохранении. На фоне потока публикаций — статей и препринтов — от математиков и программистов особую ценность представляли работы, написанных именно врачами, пусть даже и вовлеченными в разработку того или иного решения.
Большинство практических публикаций было направлено на изучение диагностической и прогностической точности алгоритмов автоматизированного анализа, использовавшихся в лучевой и лабораторной диагностике, кардиологии, дерматологии и ряде иных дисциплин. Впрочем, именно рентгенология и радиология оставались здесь бесспорными лидерами — применению ИИ в этих сферах были посвящены более 70% публикаций. Примерное распределение предпочтений модальностей среди создателей алгоритмов было следующим: магнитно-резонансная томография (МРТ) — 40% разработок, компьютерная томография (КТ) — 27%, ультразвуковые исследования (УЗИ) — 6%, маммография — 4%, рентгенография — 3%, гибридные лучевые методы — 1%. Среди анатомических локализаций, чьи лучевые изображения подвергались автоматизированному анализу наиболее часто, лидировали центральная нервная система — 40%, опорно-двигательная система — 8%, сердечно-сосудистая система и молочная железа — по 7% каждая, мочевыводящая система, грудная полость и брюшная полость — по 6% каждая. Итак, большинство разработчиков трудились над алгоритмами для анализа диагностических изображений, а врачи «отвечали» изучением качества этих алгоритмов.
В 2019 году был подведен первый итог научных исследований искусственного интеллекта с позиций доказательной медицины. Результаты были катастрофическими: из 516 проанализированных статей клинические аспекты применения ИИ описывали… 0 (ноль!) из них. Лишь 1% статей соответствовал стандартам дизайна диагностического исследования, обязательного для медицинской науки. При обучении моделей применяли медицинские данные из нескольких клиник, то есть придерживались мультицентрового подхода, лишь 2,9% разработчиков. Валидировали свои алгоритмы на новых, не использованных для обучения данных — 6% команд. Итоговая картина выглядела следующим образом. В подавляющем большинстве ситуаций алгоритмы ИИ для медицины:
— создавали на ограниченных наборах данных;
— проверяли на тех же самых данных (в итоге алгоритм просто «не знал», что бывают другие данные со своими особенностями);
— при проверке использовали нестандартный статистический аппарат, доказывая лишь принципиальную потенциальную пригодность ИИ для решения некой — часто довольно абстрактной — медицинской задачи.
Результаты работы алгоритмов оказывались невоспроизводимыми на новых данных и в условиях новых медицинских организаций; для врачебного сообщества доказательность таких статей была нулевой. ИТ-сообщество продолжало твердить о консерватизме медиков, а на самом деле абсолютное большинство врачей не хотело применять непроверенное сомнительное средство, руководствуясь древним принципом медицины: Noli Nocere!
Важно отметить, что в том же 2019 году появились первые международные обобщения списков программного обеспечения на основе искусственного интеллекта, сертифицированного в качестве медицинского изделия. Наиболее показателен в этом ключе список Института науки о данных Американского колледжа радиологии. Из него узнаем, что среди сертифицированных ИИ лидируют алгоритмы для нейровизуализации — 38%, для работы с изображениями органов грудной клетки (включая сердце и сосуды) — 30%, молочной железы — 15%. Казалось бы, наличие государственной сертификации в качестве медицинского изделия — это отличная гарантия безопасности и качества. Но, увы, это не так. Под давлением ИТ-рынка в США установлена практика сертификации программного обеспечения на основе искусственного интеллекта по принципу прецедентов; при этом отсутствует система клинических испытаний ИИ (в отличие от медикаментов, инструментов и прочих иных технологий для медицины). С точки зрения безопасности для пациента, минимизации рисков ошибки для медицинского работника, качества в реальном клиническом контексте, такой подход не выдерживает критики.
Таким образом, методологические возможности для практического применения технологий искусственного интеллекта так и оставались terra incognita; напряженность между ИТ-индустрией и врачебным сообществом нарастала…
Часть первая. КЛИНИЧЕСКАЯ МЕТОДОЛОГИЯ ПРИМЕНЕНИЯ ТЕХНОЛОГИЙ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА В ЛУЧЕВОЙ ДИАГНОСТИКЕ
Глава 1. СИСТЕМНЫЙ ПОДХОД К ПРОБЛЕМЕ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА В ЛУЧЕВОЙ ДИАГНОСТИКЕ
§1. Стратегия развития технологий искусственного интеллекта
В 2019 году Указом Президента Российской Федерации от 10.10.2019 №490 утверждена Национальная стратегия развития искусственного интеллекта на период до 2030 года, в которой определяются цели и основные задачи развития искусственного интеллекта в Российской Федерации, а также меры, направленные на его использование в целях обеспечения национальных интересов и реализации стратегических национальных приоритетов, в том числе в области научно-технологического развития.
Основные принципы развития и использования технологий ИИ в России таковы:
— защита прав и свобод человека;
— безопасность;
— прозрачность;
— технологический суверенитет;
— целостность инновационного цикла;
— разумная бережливость;
— поддержка конкуренции.
Национальная стратегия прямо определяет, что использование технологий искусственного интеллекта в социальной сфере способствует созданию условий для улучшения уровня жизни населения, в том числе за счет повышения качества услуг в сфере здравоохранения (включая профилактические обследования, диагностику, основанную на анализе изображений, прогнозирование возникновения и развития заболеваний, подбор оптимальных дозировок лекарственных препаратов, сокращение угроз пандемий, автоматизацию и точность хирургических вмешательств). Нельзя не добавить, что указанное в Стратегии повышение качества услуг в сфере образования также имеет непосредственное отношение к здравоохранению, непрерывному профессиональному развитию медицинских работников.
Стратегией установлено, что использование технологий искусственного интеллекта во всех отраслях носит общий («сквозной») характер и способствует созданию условий для улучшения эффективности и формирования принципиально новых направлений деятельности. Развивая положения Стратегии, утверждаем, что в здравоохранении сказанное может достигаться за счет:
а) повышения эффективности процессов планирования, прогнозирования и принятия управленческих решений — создания и мониторинга достижения целевой модели здравоохранения, в том числе в особых условиях (пандемий, чрезвычайных ситуаций и проч.);
б) автоматизации рутинных (повторяющихся) производственных операций — оптимального использования ресурсов, высвобождения медицинского персонала для когнитивно сложных трудовых задач;
в) использования автономного интеллектуального оборудования и робототехнических комплексов, интеллектуальных систем управления логистикой — роботизации диагностических и инвазивных процедур, роботической телемедицины для повышения доступности медицинской помощи, минимизации дефектов, связанных с человеческим фактором;
г) повышения безопасности сотрудников при выполнении бизнес-процессов — реализации постоянного (фонового) контроля качества, снижающего риски и частоту дефектов и ошибок в работе медицинского персонала;
д) повышения лояльности и удовлетворенности потребителей (в том числе направления им персонализированных предложений и рекомендаций, содержащих существенную информацию) — обеспечения приверженности к сохранению здоровья, выполнению программ диспансерного наблюдения, лечению; реализации в лечении каждого пациента уникального сочетания персонализированного подхода и принципов доказательной медицины;
е) оптимизации процессов подбора и обучения кадров, составления оптимального графика работы сотрудников с учетом различных факторов — реализации индивидуальных траекторий развития специалистов с учетом показателей контроля качества, индивидуальных предпочтений, потребностей системы здравоохранения.
Благодаря реализации Стратегии должны быть созданы условия для эффективного взаимодействия государства, организаций, в том числе научных, и граждан в сфере развития искусственного интеллекта, что позволит российским технологиям искусственного интеллекта занять значительную долю мирового рынка.
§2. Научно-методологическое обеспечение реализации положений Национальной стратегии развития искусственного интеллекта в сфере лучевой диагностики
К историческому моменту принятия Национальной стратегии развития искусственного интеллекта в Российской Федерации уже была проведена значительная подготовительная научная, аналитическая и методическая работа, позволившая в сфере здравоохранения (точнее — лучевой диагностики) сразу перейти к реализации стратегических задач.
Еще в 2015 году в Научно-практическом клиническом центре диагностики и телемедицинских технологий Департамента здравоохранения города Москвы (НПКЦ ДиТ ДЗМ) впервые в Российской Федерации начались системные научные исследования применения технологий искусственного интеллекта в здравоохранении, в частности — в лучевой диагностике.
По своей научной тематике исследования полностью соответствовали следующей наиболее значимой международной повестке:
1. Стандартизация и методология подготовки данных для обучения алгоритмов.
2. Клинический контекст применения ИИ, в том числе как основы для продуктивной его разработки.
3. Оценка качества и методология клинических испытаний технологий ИИ.
В глобальной перспективе научным врачебным сообществом перечисленные направления (или «вызовы») были заявлены как наиболее актуальные, требующие немедленных научных изысканий.
Программа научных исследований НПКЦ ДиТ ДЗМ включала:
1. Аналитические исследования:
— мониторинг и анализ рынка;
— коммуникации с компаниями-разработчиками;
— коммуникации с врачебным сообществом;
— систематизация научных публикаций;
— теоретическая (эмпирическая) разработка методологий.
2. Научное исследование:
— тестирование диагностической точности алгоритмов ИИ;
— апробация и практическая валидация разработанных методологий.
Также использовались методы социологических опросов, экспертных интервью, оценки диагностической точности по совокупности метрик и т. д.
Особую сложность создавало отсутствие в глобальной перспективе общепринятых инструментов научного анализа технологий искусственного интеллекта в медицине. Поэтому ключевой задачей программы научных исследований стала разработка нужных методологий.
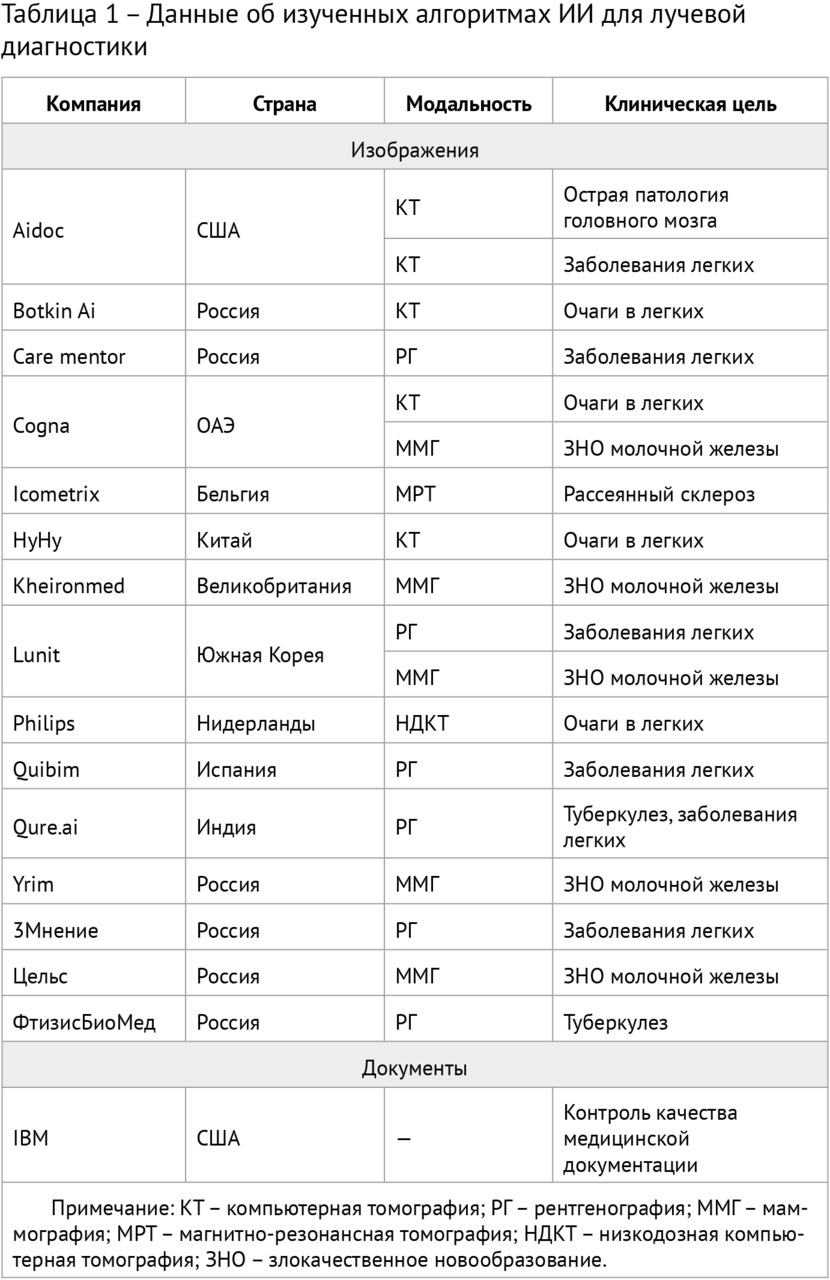
В ходе аналитической части исследования проводились постоянный мониторинг рынка, научной публикационной активности, а также дискуссии, как в формате бизнес-встреч, так и в ходе конференций, с разработчиками различного уровня (от инициативных стартапов до транснациональных производителей медицинской аппаратуры). Всего было проведено около 100 подобных встреч, в ходе которых были достигнуты соглашения о более углубленном научном исследовании 19 различных алгоритмов, предназначенных для использования в сфере лучевой диагностики (разработки компаний из Российской Федерации, Бельгии, Великобритании, Испании, Китая, Нидерландов, Объединенных Арабских Эмиратов, Соединенных Штатов Америки, Южной Кореи). Углубленное исследование предполагало экспертные интервью и независимое тестирование точности и надежности работы алгоритмов на новых данных.
Для научного тестирования отобранных решений был сформирован ряд эталонныхнаборов подготовленных (размеченных) данных, так называемых «датасетов», 4 из которых получили официальное свидетельство о государственной регистрации базы данных. Для помощи многочисленным разработчикам в 2018 году в свободном доступе впервые в Российской Федерации был размещен ограниченный деперсонализированный набор размеченных компьютерных томограмм грудной клетки. Этот набор скачали несколько десятков раз и использовали для самотестирования и обучения несколько групп разработчиков и компании (подробнее см. главу 4).
Были осуществлены исследования 18 алгоритмов автоматизированного анализа диагностических изображений и 1 алгоритма для распознавания естественного языка и анализа медицинской документации (таблица 1).
В ходе тестирования нами установлены типовые проблемы со стороны разработчиков:
1. Отсутствие или низкое качество клинически обоснованного целеполагания при разработке, непонимание контекста применения автоматизации в реальных производственных процессах (в связи с притоком в сферу медицины разработчиков из других отраслей, не имеющих представления о реальностях и особенностях практического здравоохранения).
2. Отсутствие или пренебрежение стандартами, методологические проблемы при формировании наборов данных для обучения (включая терминологические расхождения, игнорирование клинического контекста при разметке изображений).
3. Отсутствие методического понимания сути автоматизированного анализа медицинских изображений:
— некачественная сегментация анатомической области (например, поиск очага в легких по принципу «белое на черном» неоднократно приводил к ложному обнаружению «патологии» не только в брюшной полости, но и вне человеческого тела);
— отсутствие контроля качества изображения, получаемого на вход, с позиций его пригодности для диагностики (например, рентгенограмма органов грудной клетки с неполным захватом области, что чревато пропуском тяжелой патологии — рака в верхушке легкого или гемоторакса в плевральных синусах);
— отсутствие контроля целевой анатомической области, то есть контроля соответствия заявленной медицинской услуги фактическому изображению (в результате алгоритм старательно обнаруживает «очаги в легких» на рентгенограммах пяточной кости).
4. Создание дискретного программного обеспечения, не позволяющего проводить интеграцию с медицинскими (радиологическими) информационными системами (такой подход усложняет производственные процессы врача и резко ограничивает возможности данного продукта).
5. Игнорирование принципов объяснимости работы искусственного интеллекта (вывод результатов работы алгоритма без пояснений и детализации просто «ставит перед фактом» врача, что негативно сказывается на восприятии и используемости технологии).
6. Отсутствие независимой валидации алгоритмов на новых данных, в том числе в дизайне проспективных мультицентровых исследований в действующих медицинских организациях (такой подход резко снижает воспроизводимость результатов работы алгоритмов, моментально дискредитируя разработки, оказавшиеся в реальных клинических условиях).
7. Незнание или игнорирование принципов доказательной медицины (это сразу блокирует восприятие разработки медицинским сообществом, в ответ же порождается миф о «косности и консерватизме врачей»).
8. Отсутствие внутренней системы менеджмента качества у компании-разработчика (типичный дефект — отсутствие преемственности в версионности, приводящее к нестабильной работе, падению точности алгоритмов после обновлений).
9. Низкая конверсия перспективных разработок алгоритмов в готовые продукты, сертифицированные в качестве медицинских изделий (что легко объясняется предыдущим перечнем проблем).
Полученные результаты наглядно продемонстрировали выраженную нехватку методологии разработки, валидации и применения технологий искусственного интеллекта в практическом здравоохранении, в частности — в лучевой диагностике. Вместе с тем многие научные тестирования были достаточно успешными, алгоритмы надежно и качественно справлялись с клинически вполне обоснованными задачами. Это вселяло оптимизм и убежденность в необходимости дальнейших исследований. Приведем несколько примеров.
Кейс №1. Автоматизированный анализ низкодозовых компьютерных томографий (НДКТ) органов грудной клетки для выявления признаков злокачественных новообразований
Цель: провести аналитическую валидацию (оценку диагностической точности) алгоритма выявления очагов на НДКТ.
Референс-тест: эталонный набор данных из 100 НДКТ, сформированный в рамках программы скрининга ЗНО легкого в Москве; каждое исследование прошло двухэтапную экспертную интерпретацию.
Индекс-тест: алгоритм ИИ Trajanovski S et al, 2019 для анализа НДКТ легких.
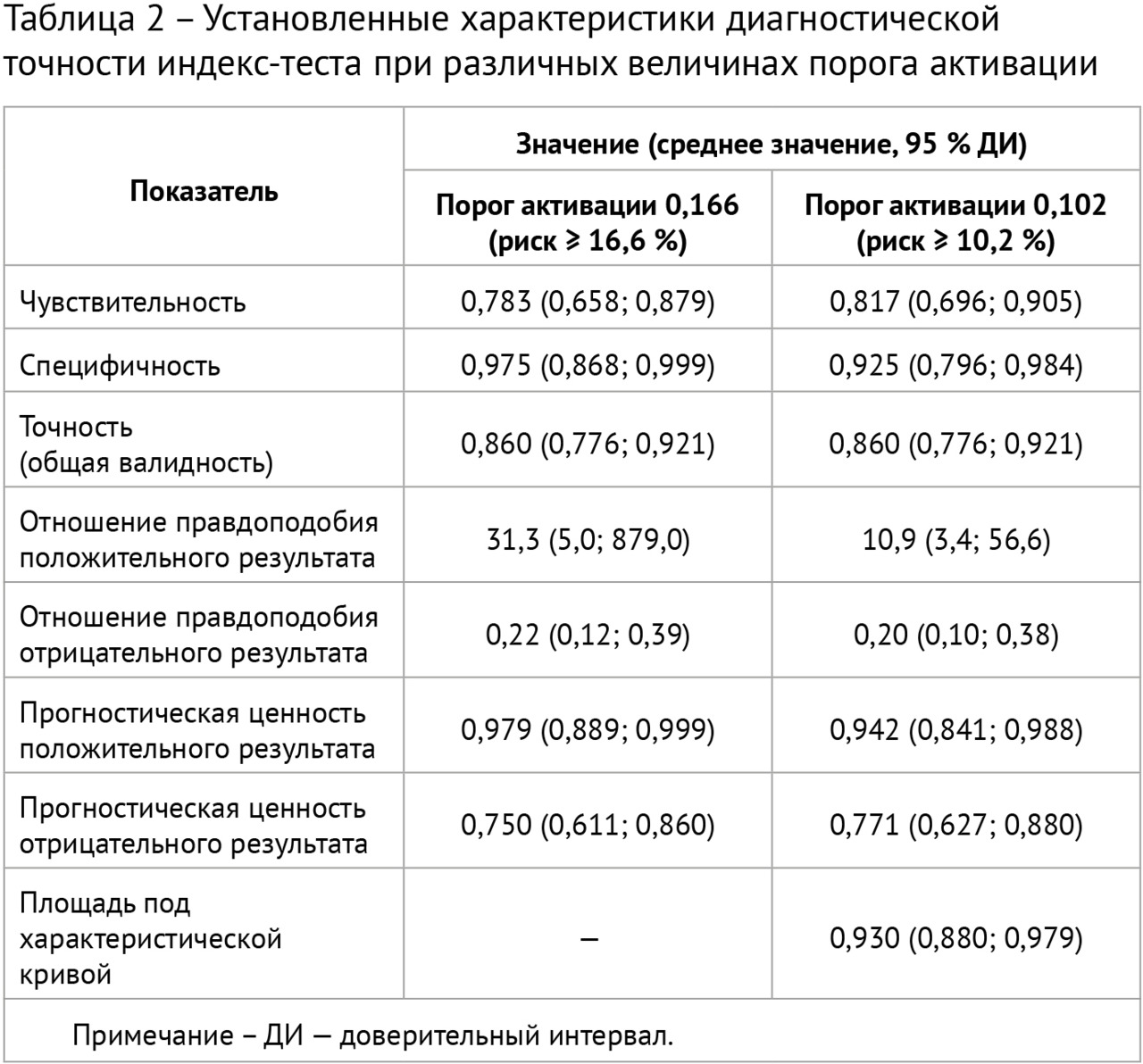
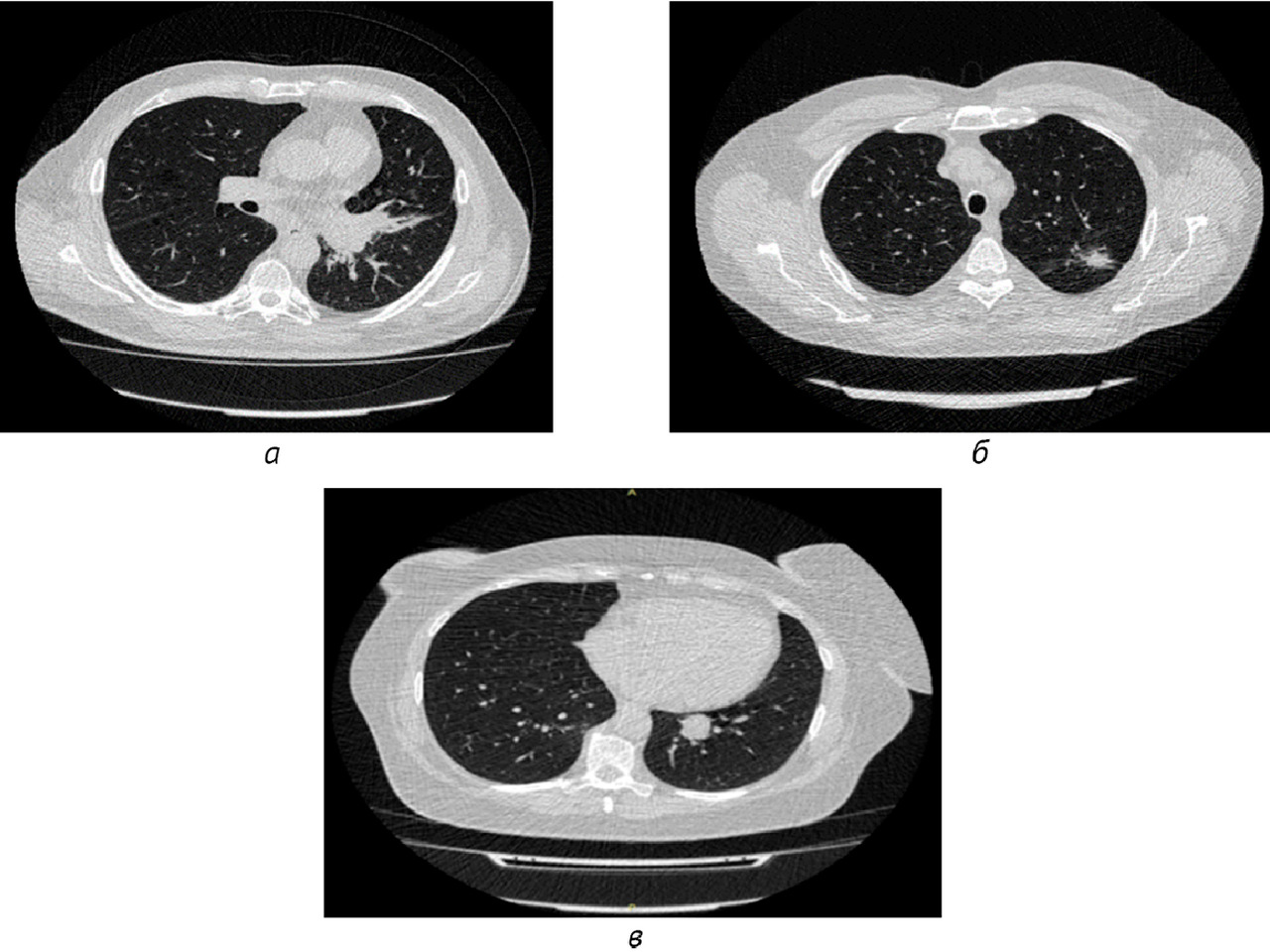
Результаты: в соответствии с разработанной методологией проведен этап аналитической валидации — доказательный тест (тестирование алгоритма на эталонном наборе данных, расчет стандартизированного набора метрик). Результаты представлены в таблице 2; проведено их сравнительное изучение с данными самих разработчиков и опубликованными результатами тестирования аналогичных алгоритмов. На рис. 1 представлены примеры работ изучаемого алгоритма ИИ.
Выводы:
1. Установлены следующие показатели диагностической точности алгоритма ИИ для автоматизированного выявления очагов в легких на НДКТ: чувствительность — 0,817, специфичность — 0,925, точность — 0,860, площадь под характеристической кривой — 0,930.
2. Сопоставление полученных значений с итогами собственного тестирования разработчиками алгоритма ИИ свидетельствует о хорошей воспроизводимости результатов работы ИИ на независимых данных, относящихся к популяции Москвы.
3. Изученный алгоритм ИИ может быть допущен к клинической апробации. В частности, он может применяться для первичного автоматизированного анализа результатов скрининговых обследований (с обязательным вторичным просмотром врачом-рентгенологом).
Кейс №2. Автоматизированный анализ рентгенограмм органов грудной клетки для выявления признаков туберкулеза
Цель: провести аналитическую валидацию (оценку диагностической точности) алгоритма выявления заболеваний органов грудной клетки для массовых профилактических осмотров.
Референс-тест:
— экспериментальная выборка №1 (n=140), соотношение «норма»: «патология» 50:50,
— экспериментальная выборка №2 (n=150), соотношение «норма»: «патология» 95:5.
Индекс-тест: система автоматизированного анализа флюорографических снимков на основе сверхточных нейронных сетей типа U-NET, модифицированных и обученных специальным образом.
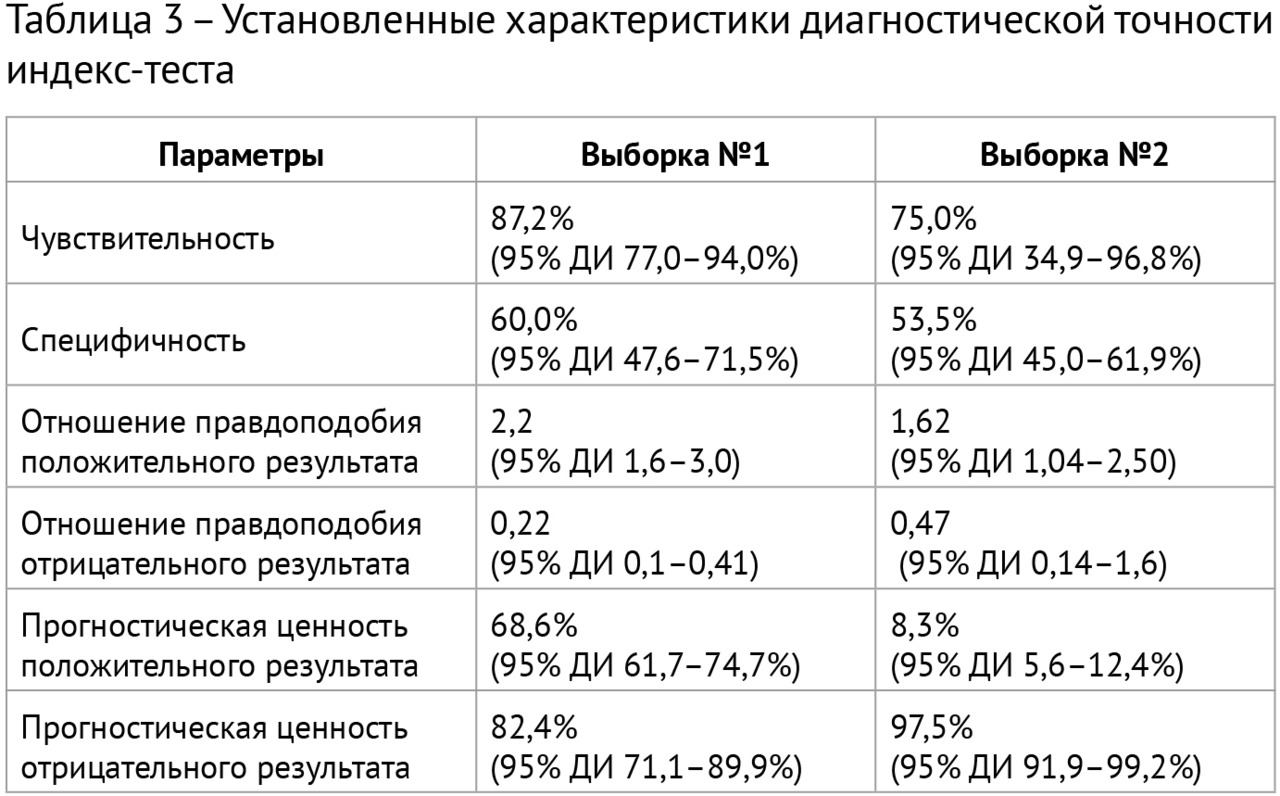
Результаты: в соответствии с разработанной методологией проведен этап аналитической валидации — доказательный тест (тестирование алгоритма на эталонных наборах данных, расчет стандартизированного набора метрик). Результаты представлены в таблице 3; проведено их сравнительное изучение с данными самих разработчиков и опубликованными результатами тестирования аналогичных алгоритмов. На рис. 2 представлены примеры работ изучаемого алгоритма ИИ.
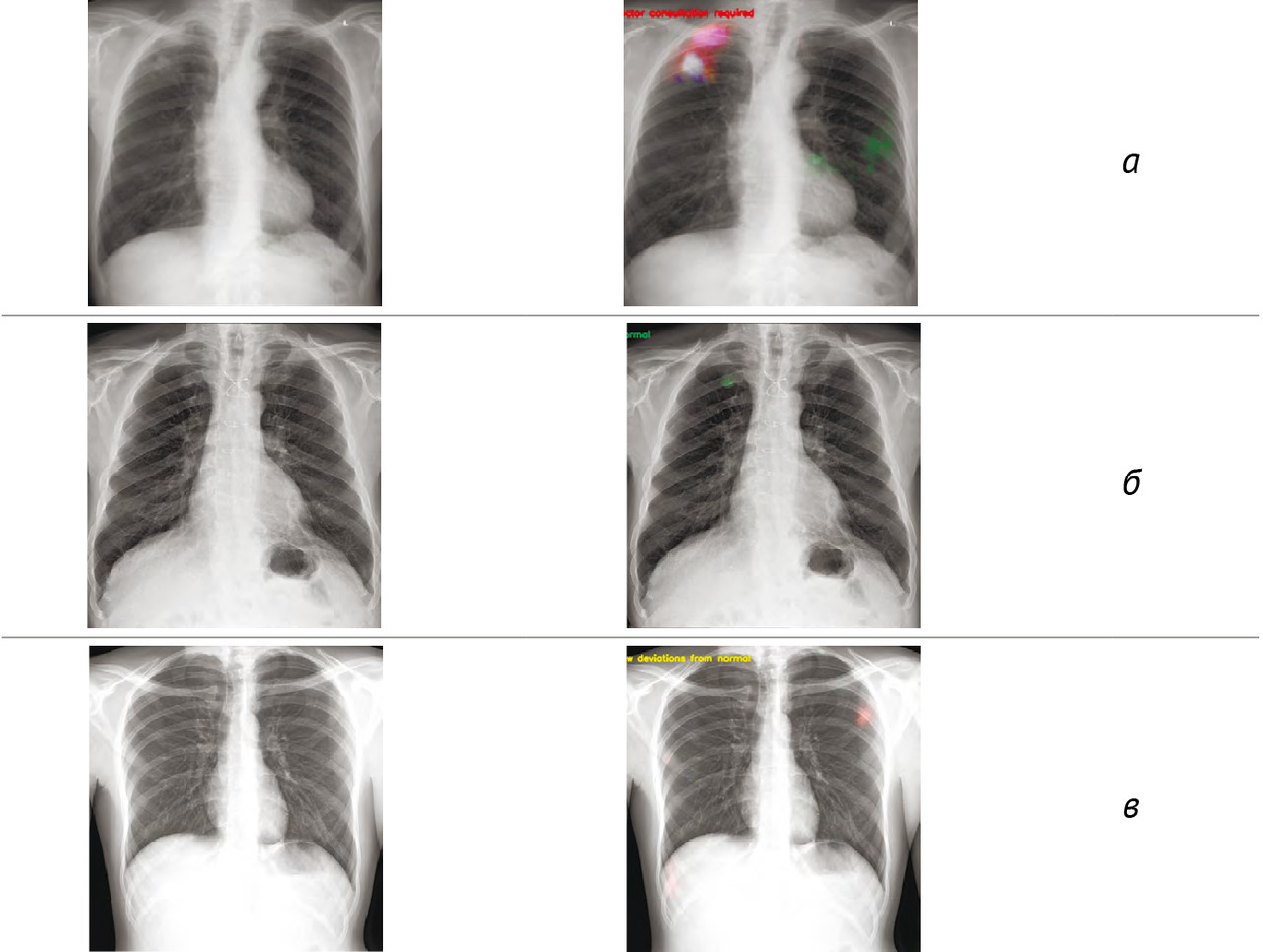
Выводы:
1. В результате ретроспективного исследования определены параметры диагностической точности системы скрининга туберкулеза легких на основе «искусственного интеллекта»: чувствительность 75,0–87,2%, специфичность 53,5–60,0%, площадь под кривой 0,64–0,74.
2. Система применима только для массовых профилактических осмотров в популяциях с низкой претестовой вероятностью наличия патологии, что подтверждается значением прогностической ценности отрицательного результата (97,5%).
3. Система может быть рекомендована для полуавтоматизированного формирования в процессе скрининга групп риска по туберкулезу легких для последующей верификации результатов компьютерного анализа флюорограмм врачом-рентгенологом.
Кейс №3. Автоматизированный анализ протоколов описаний результатов компьютерной томографии органов грудной клетки в целях контроля качества
Цель: провести аналитическую валидацию (оценку диагностической точности) алгоритма распознавания естественного языка.
Референс-тест: эталонный набор данных из протоколов описаний 5047 результатов НДКТ.
Индекс-тест: когнитивная система обработки естественного языка («IBM Watson’s Natural Language Processing Algorithm»).
Результаты: проведен многосторонний анализ протоколов НДКТ органов грудной клетки с целью обнаружения в них изменений по заданным параметрам, а также для выявления неточностей. Установлено, что в 8,3% документов содержались расхождения между описанием и заключением. Суть расхождений состояла в том, что значимый элемент (например, наличие очагов в легких) был указан лишь в одном компоненте протокола. При математическом сопоставлении согласованности решений о расхождениях в наличии триггеров между компонентами протокола установлено, что коэффициент каппа Коэна составляет 0,95. Определено соответствие рекомендаций, содержащихся в заключении, типу выявленного очага по классификации LungRADS. Установлено, что для очагов LungRADS 3 рекомендованные принципы ведения пациентов использованы в 46% случаев, для LungRADS 4А — в 42%, а для LungRADS 4B — в 49%. Автоматическая классификация очагов и анализ заключений были верифицированы двумя независимыми врачами-радиологами; точность системы обработки естественного составляет 96%.
Выводы:
1. Алгоритмы коммерческой системы обработки естественного языка позволили провести автоматизированный анализ 5047 деперсонализированных протоколов низкодозовых компьютерных томографий, выполненных в рамках масштабной программы скрининга рака легких. Согласованность решений (коэффициент каппа Коэна) при использовании системы в рамках контроля качества лучевых исследований составляет 95–96%.
2. Показаны потенциальные возможности системы для выявления значимых слов и их сочетаний, характеризующих качество описаний и заключений, а также для анализа соответствия рекомендаций, формулируемых врачом-рентгенологом, методическим и иным требованиям.
3. Можно констатировать факт применимости системы обработки естественного языка в качестве инструмента для контроля качества лучевых исследований, то есть для сплошного автоматизированного анализа протоколов и иных текстовых документов.
Кейс №4. Автоматизированный анализ магнитно-резонансных томографий головного мозга для выявления признаков рассеянного склероза
Цель: провести аналитическую валидацию (оценку диагностической точности) алгоритма выявления признаков рассеянного склероза (проспективно, в условиях отделения лучевой диагностики медицинской организации, оказывающей первичную (амбулаторно-поликлиническую) медицинскую помощь).
Референс-тест: поток результатов МР-исследований за период времени (n=93). Каждое исследование интерпретировано в 2 этапа. Первично — врачом-рентгенологом, непосредственно проводившим исследование; второе чтение проводилось двумя врачами-рентгенологами (заведующим отделением и независимым врачом-экспертом). При отсутствии расхождений во мнении исследование относили к одной из двух групп. При наличии расхождений исследование интерпретировалось повторно, коллегиально, с участием врача-рентгенолога с субспециализацией по нейрорадиологии, после чего исследование относили к одной из двух групп.
Индекс-тест: оригинальный алгоритм ИИ, Беляев М. с соавт., 2019.
Результаты: в соответствии с разработанной методологией проведен этап аналитической валидации — доказательный тест (проспективное тестирование алгоритма, расчет стандартизированного набора метрик). Результаты представлены в таблице 4; проведено их сравнительное изучение с данными самих разработчиков и опубликованными результатами тестирования аналогичных алгоритмов. На рис. 3 и 4 представлены примеры работ изучаемого алгоритма ИИ.
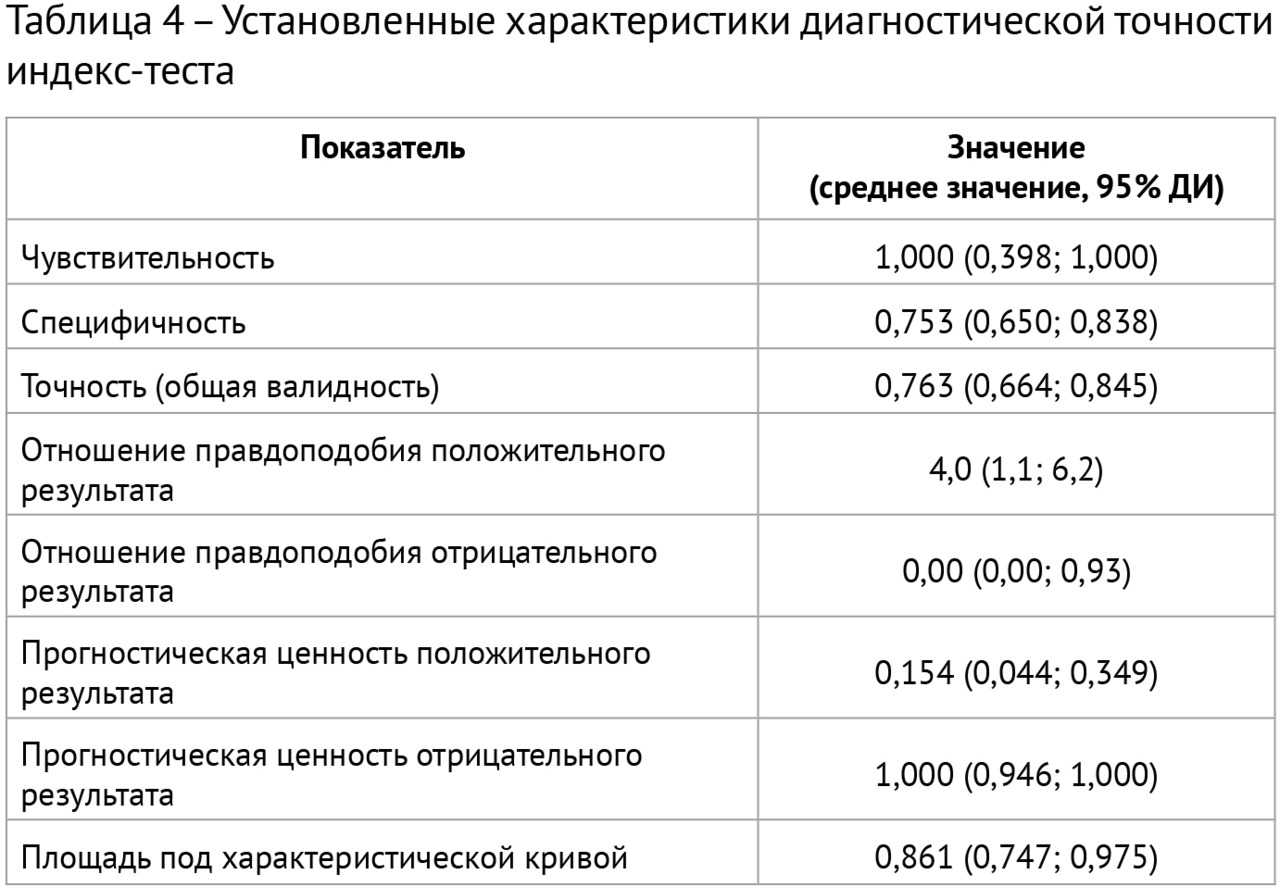
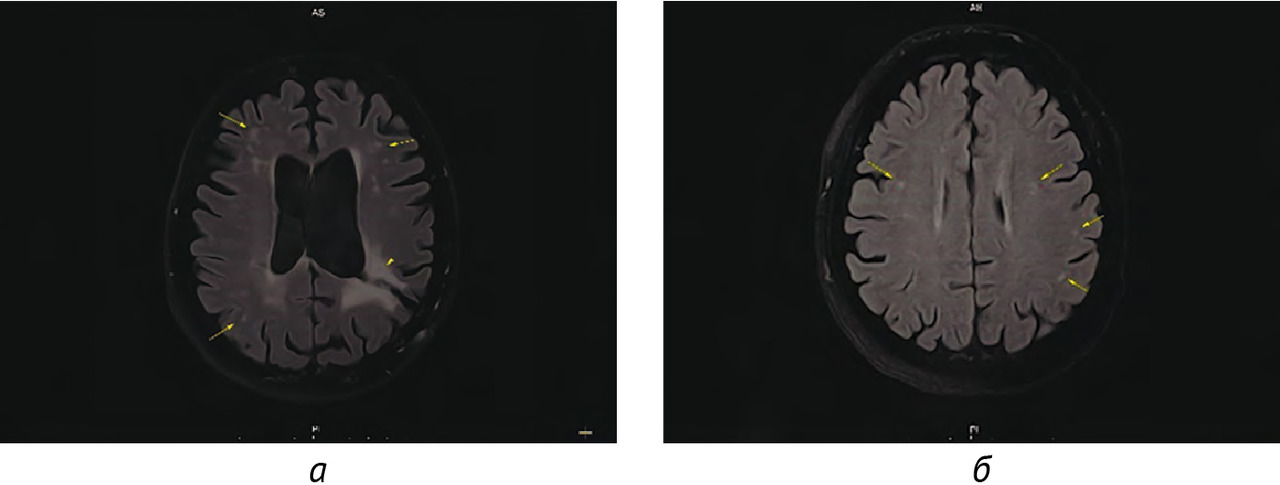
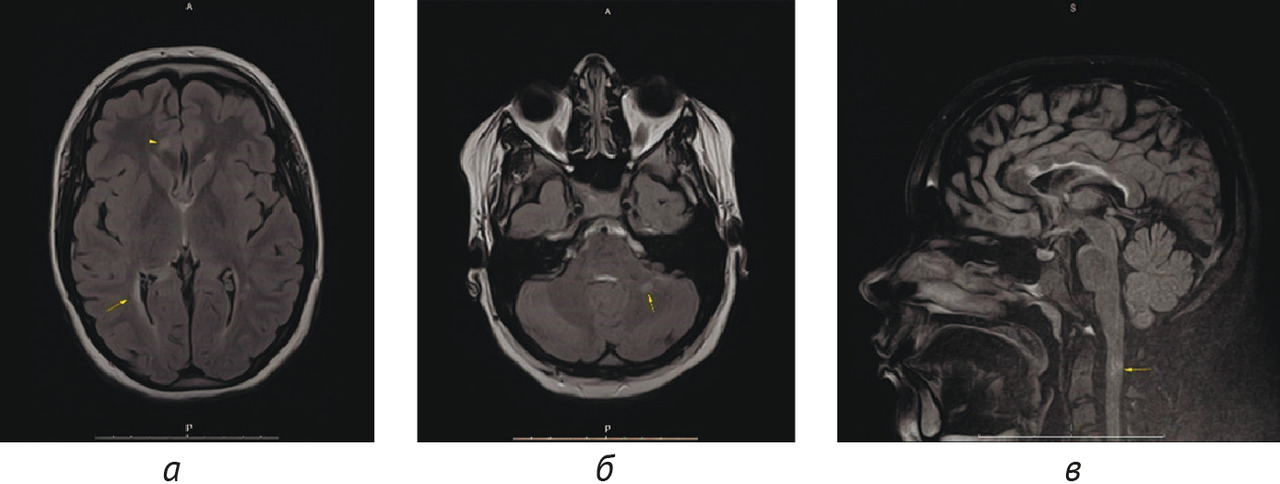
Выводы:
1. Результатом работы стала разработка алгоритма ИИ для выявления рассеянного склероза на МРТ в условиях типовой городской поликлиники, который обеспечивает эффективную сортировку МР-исследований в условиях первичного звена здравоохранения с поддержанием оптимального уровня настороженности относительно рассеянного склероза.
2. Проведена валидация диагностической точности алгоритма ИИ, при этом чувствительность метода составила 100,0, специфичность — 75,3, точность — 76,3, площадь под характеристической кривой — 0,861. Уровень прогностической ценности отрицательного результата составил 100%, что свидетельствует о надежном «отсеивании» алгоритмом результатов исследований без признаков рассеянного склероза.
3. Сопоставление полученных значений с собственными предыдущими результатами и литературными данными свидетельствует о достаточном качестве и отличной воспроизводимости результатов работы алгоритма на независимых данных. Установлено, что на снижение специфичности алгоритмов ИИ для выявления РС влияет возраст пациентов.
4. Рекомендуется расширенная клиническая апробация алгоритма в условиях медицинской организации первичного звена, оказывающей амбулаторно-поликлиническую медицинскую помощь.
В процессе исследования мы активно общались с профессиональной аудиторией — врачами-рентгенологами, радиологами, специалистами ультразвуковой диагностики, руководителями служб лучевой диагностики, организаторами здравоохранения. В ходе бесед и дискуссий легко было понять общее отношение: настороженное ожидание новых технологий на фоне недостатка объективных данных.
Тогда, помимо стандартных научных и популярных способов предоставления объективной информации, мы приняли решение провести специальное мероприятие в формате «поединка» алгоритмов и врачей, получившее название «ИИ-баттл: рентгенологи против искусственного интеллекта».
Мероприятие было запланировано как открытый конкурс разработчиков ИИ для лучевой диагностики. К участию допускались российские и зарубежные юридические лица, разработавшие или имеющие права на алгоритмы для автоматизированного анализа результатов компьютерной томографии или рентгенографии органов грудной клетки (выявление очагов и иных патологических состояний) или маммографии (скрининг злокачественных новообразований).
Участникам предлагалось продемонстрировать точность и качества своего алгоритма на эталонном наборе данных. Для конкурса были разработаны три полностью анонимизированных набора данных по 100 исследований в каждом (50% случаев с целевой патологией и 50% случаев нормы). Подготовка данных заключалась в разметке 3 врачами-экспертами с достижением консенсуса по каждому случаю. Отмечались исследования с патологией, координаты и диаметр патологических очагов.
Несмотря на широкое анонсирование мероприятия в открытом конкурсе — в открытой схватке с теми самыми рентгенологами, которых хотели заменить искусственным интеллектом — решились принять участие только четыре компании. Это были разработчики из России («Медицинские скрининг-системы (Цельс)», «Третье мнение», «IRYM») и из Китая («HY Medical»).
Конкурс был проведен в рамках конференции МРО «Лучевая диагностика в онкологии» (Москва, Сколково, 13–14 декабря 2019 г.), на которой присутствовало более полутора тысяч участников из России, стран СНГ, Европы и Китая. Он состоял из заочной и очной фаз. За 12 часов до очной фазы участники получили доступ к анонимизированным наборам данных, провели их анализ и предоставили жюри результаты работы алгоритмов для расчета метрик диагностической точности. Очная фаза конкурса включала короткую самостоятельную презентацию каждым участником и, собственно, поединок в следующем формате. Из наборов данных были отобраны 5 клинических случаев по каждой модальности — как вполне тривиальных, так и диагностически сложных. Аудитории врачей-рентгенологов демонстрировали каждый клинический случай и предлагали вынести общий вердикт. Затем представлялось мнение искусственного интеллекта, а вердиктом служила согласованная позиция 3-х экспертов, проводивших разметку наборов данных.
В течение второго дня на конференции присутствовало большое количество участников, в аудитории проходило активное обсуждение: после абстрактных выступлений и маркетинговых выставок у врачей появилась возможность подробно ознакомиться с очередной революционной технологией. По модальности «рентгенография» с врачами состязался только один алгоритм, показавший неплохие результаты, которые в четырех случаях совпали с мнением врачей. Последний, пятый, снимок оказался фатальным: ИИ нашел патологию там, где ее не было; но при этом еще и пропустил перелом ребра довольно коварной локализации, однако вполне очевидный.
По модальности «маммография» врачам противостояли сразу два алгоритма, которые не смогли представить консолидированные результаты — их мнения постоянно различались. И если первый алгоритм почти все время совпадал в своих решениях с врачами, то второй часто ошибался. Общий исход раунда оказался нетривиальным. В трех случаях алгоритмы дали ложноположительный ответ, «увидев» онкологическую патологию. Проблема состояла в том, что и участники конференции разошлись во мнениях, однако эксперты, размечавшие исследования, вынесли вердикт — на всех трех снимках присутствуют доброкачественные изменения.
Отличные результаты показал алгоритм по модальности «компьютерная томография»: полное совпадение мнение врача и ИИ было в четырех ситуациях. В последнем случае алгоритм сделал ошибку, хотя сомнения имелись и у врачебной аудитории. Для решения проблемы был созван консилиум экспертов с субспециализацией.
Эмоции присутствующих и атмосферу ИИ-баттла достоверно передал один из основателей ассоциации разработчиков и пользователей систем искусственного интеллекта в медицине «Национальная база медицинских знаний» Александр Гусев: «Долой скучные выставки и рекламный спам: живое сравнение систем с экспертами и сидящими в зале врачами создает совершенно другое восприятие».
Общая оценка участников проводилась по сумме четырех этапов: анкетирование (оценка системы качества компании), анализ набора данных из 100 клинических случаев (метрики диагностической точности), презентация компаний (оценка симпатий зрителей), соревнование в точности диагностики (голосование аудитории по итогам поединка). Для каждого этапа была сформирована система балльной оценки. Жюри в составе врачей, физиков и инженеров приняло окончательное решение. На торжественном закрытии конференции были вручены награды:: приз зрительских симпатий получила компания «Третье мнение», в номинации «Помощник врача» лучшей стала «HY Medical», в номинации «Самый точный» — «IRYM», а гран-при заслужила компания «Медицинские скрининг-системы (Цельс)» (рис. 5).
Таким образом, надо отметить, что в течение 4-х лет велась системная работа по изучению феномена технологий искусственного интеллекта относительно применимости в сфере лучевой диагностики, созданию необходимых методологий и принципов, коммуникациям с индустриальным и медицинским сообществом.
В качестве итогов аналитического исследования и научного тестирования алгоритмов были опубликованы 14 научных работ, в том числе 2 монографии в издательствах «Springer-Verlag» и «ГЭОТАР-Медиа», 3 статьи в журналах, индексируемых Scopus и Web of Science (в том числе во входящем в первый квартиль цитируемости «Insights into Imaging»); разработаны 2 методических рекомендаций; получено 6 документов о регистрации прав на интеллектуальную собственность для программного обеспечения и баз данных; сделано около 50 докладов на научно-практических конференциях. Также в целях популяризации тематики выпущено более 30 научно-популярных публикаций, организован первый в Российской Федерации «ИИ-баттл: рентгенологи против искусственного интеллекта».
Проведенная работа позволила получить широкое представление о текущем состоянии разработок, качестве, особенностях работы технологий искусственного интеллекта. Но прежде всего эта работа стала научно-практической основой для создания необходимой научной базы — в ее процессе нами формировалось понимание клинического контекста применения ИИ в лучевой диагностике, создавались и совершенствовались методология клинических испытаний и эталонные наборы данных, а также поэтапно развивались технологические условия для автоматизации лучевой диагностики. Подробнее об этом расскажем в следующих главах.
Глава 2. ТЕХНОЛОГИЧЕСКАЯ ОСНОВА ДЛЯ ПРИМЕНЕНИЯ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА В ЛУЧЕВОЙ ДИАГНОСТИКЕ
Основное предназначение технологий искусственного интеллекта в лучевой диагностике — это автоматизация определенных участков производственных процессов, в которых задействованы руководители, врач и средний медицинский персонал, с целью повышения безопасности и качества, но прежде всего — с целью оптимизации (подробно это утверждение будет доказано в следующей главе). Поэтому использование технологий ИИ должно происходить в «фоновом» режиме, без необходимости увеличения количества трудовых операций, а конкретные программные решения должны быть встроены в информационную инфраструктуру отделений лучевой диагностики.
Наличие медицинской (радиологической) информационной системы с интегрированным диагностическим оборудованием и автоматизированными рабочими местами врачей-рентгенологов — это абсолютный минимум с точки зрения технической готовности. Для применения технологий ИИ в оптимальном масштабе и с высокой эффективностью требуется наличие единого цифрового пространства службы лучевой диагностики в рамках субъекта РФ: централизованного архива медицинских изображений с подключением до 100% диагностического оборудования и обеспечением доступа к результатам исследований до 100% врачей-рентгенологов.
Функциональные задачи единого цифрового пространства службы лучевой диагностики:
— обеспечить наличие хранилища данных медицинских изображений с возможностью «сквозной» идентификации результатов исследований данного пациента;
— предоставить защищенный доступ для уполномоченных сторон (медицинских организаций, их сотрудников, пациентов и их законных представителей) ко всему массиву диагностических данных определенного пациента;
— выполнять централизованное накопление и анализ в режиме реального времени технологической информации, поступающей от диагностической аппаратуры (включая информацию о дозовой нагрузке, применяемых протоколах и проч.);
— реализовать поддержку принятия решений;
— обеспечить возможность проведения мероприятий по контролю качества процесса проведения и результатов диагностических исследований;
— формировать информационный базис для принятия управленческих решений в отрасли здравоохранения.
Единое цифровое пространство службы лучевой диагностики должно включать технологические и методические компоненты.
К технологическим компонентам относятся:
— парк цифровой диагностической аппаратуры, объединенный в сеть;
— централизованный вендор-нейтральный архив медицинских изображений;
— телекоммуникационное оборудование;
— рабочие станции;
— средства защиты персональных данных и обеспечения безопасности;
— системное и прикладное программное обеспечение;
— стандарты и протоколы обмена данными.
К методическим компонентам относятся:
— способ централизованного накопления и мониторинга динамики данных, характеризующих использование парка диагностической аппаратуры;
— метод дистанционного анализа и контроля качества результатов диагностических исследований с формированием индивидуальных стратегий повышения качества;
— методики описаний результатов лучевых исследований с применением телемедицинских технологий (первичные, экспертные, двойные и проч.).
В Москве технологической основой для применения искусственного интеллекта в лучевой диагностике стал Единый радиологический информационный сервис в составе Единой медицинской информационно-аналитической системы города Москвы (ЕРИС ЕМИАС).
ЕРИС ЕМИАС — это информационная система в сфере здравоохранения, которая объединяет рабочие места рентгенолаборантов, врачей-рентгенологов и диагностическую аппаратуру, аккумулирует информацию о каждом исследовании или серии исследований, проведенных на подключенных к нему устройствах.
Функциональные возможности ЕРИС ЕМИАС включают:
— учет и регистрацию всех проводимых лучевых исследований (медицинские организации государственной системы здравоохранения г. Москвы амбулаторно-поликлинического и стационарного звеньев);
— хранение и доступ ко всему объему диагностических изображений;
— подсистему обмена информацией с любой внешней информационной системой в режиме реального времени;
— полную автоматизацию процесса логистики исследования, архивации и доступа к историческим данным пациента;
— визуализацию исследований, позволяющую провести рутинную диагностику без использования дополнительного программного обеспечения;
— шаблонизацию, структурирование и хранение медицинской информации в международных стандартах (включая структурированные шаблоны описаний);
— аналитический модуль, позволяющий оценивать ключевые показатели;
— модуль технического мониторинга доступности диагностического оборудования;
— подсистему запроса консультативной помощи в сложных клинических случаях;
— подсистему анализа и контроля качества.
Апробация ЕРИС проводилась в течение 2015 года, наращивание числа подключенных медицинских организаций амбулаторно-поликлинического звена интенсивно осуществлялось в 2016 году. В 2017 году ЕРИС вышел на рутинный порядок использования, в 2018 — проведена интеграция ЕРИС и ЕМИАС, в 2019 — начато подключение к ЕРИС ЕМИАС медицинских организаций стационарного звена, а в 2020 — завершено формирование единого цифрового пространства лучевой диагностики столицы. Данные об интегрированном в ЕРИС ЕМИАС оборудовании приведены в таблице 5.
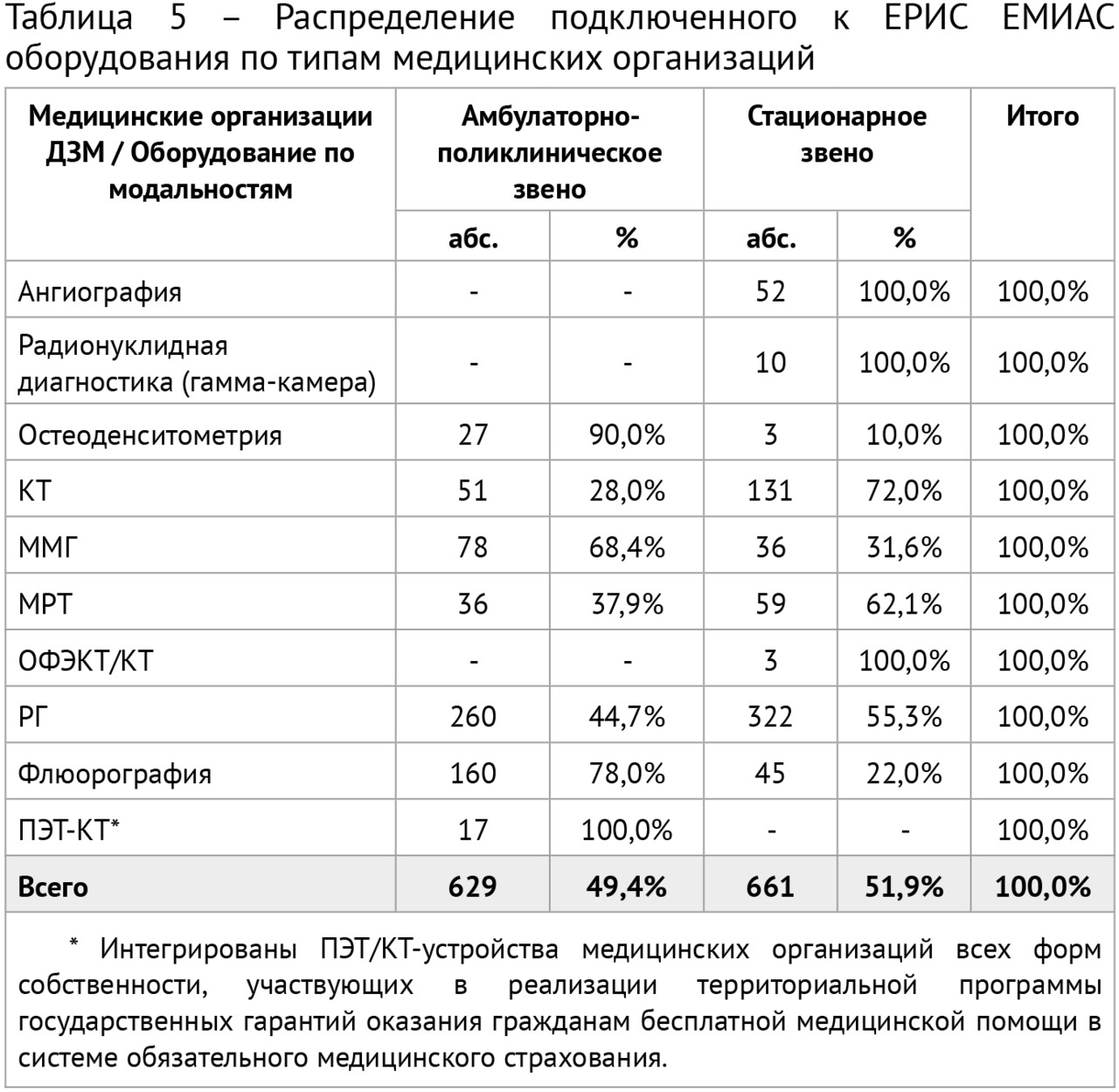
Также была обеспечена возможность работы для 100% врачей-рентгенологов и рентгенолаборантов, организован доступ к результатам исследований для лечащих врачей, направляющих пациентов на исследования. Путем интеграции с порталом государственных услуг г. Москвы (www.mos.ru) реализована возможность предоставления результатов исследований (как описания, так и непосредственно изображения) пациентам через личный кабинет.
В фазе апробации в ЕРИС ЕМИАС было накоплено около 95 тысяч изображений, в фазе рутинного применения к концу 2020 года их общее количество превысило 7 миллионов.
Управленческий компонент. Накапливаемая в ЕРИС информация о загруженности, режимах работы, протоколах исследований диагностической аппаратуры доступна в режиме реального времени посредством специального аналитического интерфейса или «дашборда» (рис. 5).
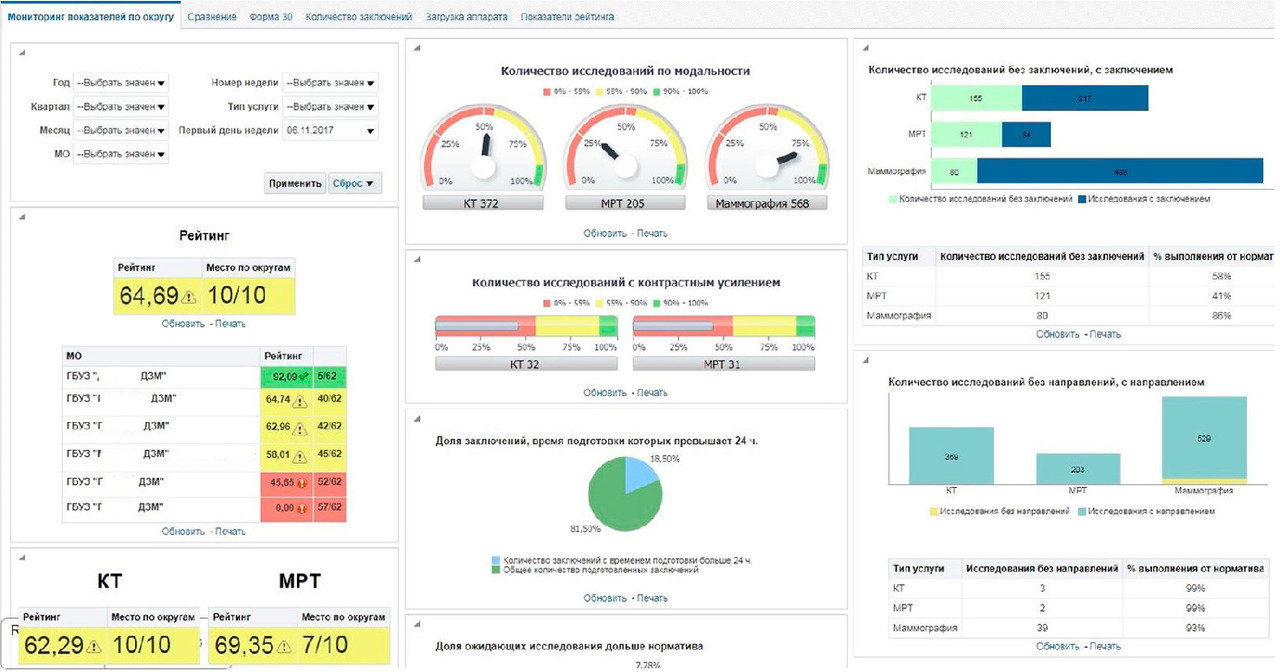
Интерфейс — это уникальный аналитический инструмент, позволяющий в режиме реального времени мониторировать работу всей службы лучевой диагностики г. Москвы, оперативно принимать необходимые управленческие решения. Данные, поступающие в систему с промежутком 2 секунды, накапливаются и доступны для ретроспективного анализа. Эта подсистема разработана по оригинальной авторской концепции и уникальному техническому заданию, включающему базу метрик и методики их расчета.
В частности, посредством интерфейса можно контролировать следующие основные параметры по каждому подключенному аппарату:
— количество отработанных дней;
— количество отработанных смен;
— количество проведенных исследований;
— количество исследований, проведенных по разным каналам финансирования;
— количество проведенных исследований с применением контрастного усиления;
— время и длительность проведения исследований.
Также ЕРИС позволяет учитывать некоторые параметры работы врача-рентгенолога, рентгенолаборанта и отделения лучевой диагностики в целом:
— количество заключений, подготовленных в системе;
— время подготовки заключения в системе (разница между временем окончания исследования и временем, когда заключение появляется в системе);
— время, которое пациенты ожидают проведения исследования (разница между датой выдачи направления на исследование и датой проведения исследования);
— количество пациентов, не имеющих направления на исследование.
Кроме того, в режиме реального времени можно оценивать техническое состояние оборудования и эффективность его загрузки. В пилотном режиме (в том числе с использованием специализированного программного обеспечения сторонних производителей) доступен контроль дозовой нагрузки.
Аналитический интерфейс может быть настроен для использования организаторами здравоохранения различного уровня, исходя из конкретных задач: отдельно для заведующего отделением, окружного внештатного специалиста и главного внештатного специалиста по лучевой диагностике столицы.
Благодаря ЕРИС ЕМИАС в автоматическом режиме налажен сбор данных по количеству выполненных исследований в разрезе модальностей оборудования, виду исследований, времени проведения исследования, режима работы медицинского персонала и эксплуатации оборудования. Проводится регулярный мониторинг работоспособности и загрузки оборудования, количества диагностических ошибок по модальностям, видам оборудования, отделениям лучевой диагностики, врачам и рентгенолаборантам. Актуализируется перечень малозагруженных аппаратов, потенциально пригодных для перемещения в медицинские организации, нуждающиеся в компьютерном или магнитно-резонансном томографе. Применяются рейтинги отделений для увеличения количества исследований с внутривенным контрастированием и обеспечения их доступности. На основе данных из ЕРИС ЕМИАС готовятся управленческие решения, формируются нормативно-правовая и методическая документация.
Медицинский компонент. Наличие ЕРИС ЕМИАС позволило обеспечить цифровизацию производственных процессов медицинских организаций в части лучевой диагностики. Одновременно появилась возможность для проведения дистанционных интерпретаций и описаний результатов исследований. С применением телемедицинских технологий стали проводиться экспертные телемедицинские консультации (их среднее количество в год стабильно достигает 3–4 тысяч). Затем в 2018 году проведены успешные эксперименты по централизации описаний и перекрестным описаниям по субспециализациям.
В первом случае проведена реорганизация производственных процессов, кадрового и ресурсного обеспечения одной городской поликлиники с разветвленной филиальной сетью путем создания единого центра описаний, использующего в своей работе ЕРИС ЕМИАС и методики телемедицины. В результате достигнуты: экономия финансовых средств за счет снижения фонда оплаты труда на 59% (более 19 млн руб. в год), затрат на фотолабораторию на 40% (0,4 млн руб. в год), сокращения коммунальных и эксплуатационных расходов на 25% (более 6 млн руб. в год); рост производительности труда (число описаний, выполняемых одним врачом, увеличилось с 4,7 до 21 в день).
Во втором случае организованы описания результатов исследования по субспециализациям с учетом анатомического принципа. Для этого в ЕРИС ЕМИАС была налажена специальная схема маршрутизации. Такой подход обеспечил снижение удельного веса клинически значимых расхождений с 2,0% до 1,0%, незначимых — с 5,0% до 3,0%, замечаний общего характера — с 35,0% до 16,0% (в исследованиях по субспециализации «нейрорадиология»). Также благодаря «перекрестной» маршрутизации исследований для описаний полностью устранены простои и перебои, связанные с физическим отсутствием врача (например, по болезни или из-за отпуска).
Таким образом, были получены результаты, свидетельствующие об экономической эффективности, росте производительности труда, повышении качества и доступности медицинской помощи. Они легли в основу концепции Референс-центра лучевой диагностики, созданного в Москве в 2019 году.
Особое значение имеет такой методический компонент ЕРИС ЕМИАС, как дистанционный анализ и контроль качества лучевых исследований. Пересмотр (от англ. «peer review») результатов диагностических исследований — глобально признанный подход, заключающийся в повторном анализе диагностических изображений и их описаний квалифицированным врачом-экспертом (чаще всего непосредственным руководителем) для выявления расхождений, ошибок, неточностей и их методического устранения.
Ограниченная методика пересмотра была развита нами в концепцию дистанционного анализа и контроля качества, которая подразумевает дистанционный, систематический, независимый и документируемый процесс оценки качества проведения и описания рентгенорадиологических исследований, выполненных в медицинской организации с целью определения степени их соответствия рекомендуемым стандартам. Оценка проводится постоянно, на регулярной основе, независимой группой экспертов; для анализа случайным образом формируется выборка исследований и их описаний, при этом она анонимизируется. Научно обоснована классификация расхождений, которые могут быть выявлены при анализе. Разработаны и автоматизированы в ЕРИС ЕМИАС процессы работы врачей-экспертов, обеспечивающие максимальную объективность, беспристрастность и точность выявления расхождений. Отличительная черта дистанционного анализа и контроля качества — направленность на непрерывное улучшение. По итогам анализа формируются рейтинги и индивидуальные стратегии повышения качества. Последние могут включать учебно-методические и образовательные мероприятия в разных форматах, организационные, технические и, крайне редко, административные мероприятия.
Для Московского референс-центра лучевой диагностики дистанционный анализ и контроль качества — один из стандартных производственных процессов. Научно доказана его эффективность: на материале 48520 исследований показано достоверное снижение удельного веса расхождений, в том числе клинически значимых — почти на 50% в показателях наглядности.
В 2020 году Московский референс-центр лучевой диагностики, как «ядро» единого цифрового пространства, работает в рутинном режиме. Основными его процессами являются первичные описания результатов лучевых исследований, двойные просмотры результатов скринингов и результатов компьютерной томографии пациентов с подозрением на новую коронавирусную инфекцию, экспертные консультации, дистанционный контроль качества.
Таким образом, единое цифровое пространство службы лучевой диагностики города Москвы в виде ЕРИС ЕМИАС стало технологической, а в части дистанционного контроля качества — еще методической, основой для применения технологий искусственного интеллекта.
Глава 3. КЛИНИЧЕСКИЙ КОНТЕКСТ ПРИМЕНЕНИЯ ТЕХНОЛОГИЙ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА
Если исключить философский подход и применить к современным компьютерным наукам принципы механистического материализма, то технологии искусственного интеллекта окажутся всего лишь инструментом автоматизации тех или иных производственных операций в здравоохранении. Безусловно, автоматизация должна быть осознанной, резонной, обоснованной, наконец — эффективной. Иначе как не вспомнить афоризм психолога Абрахама Маслоу (1908–1970): «Я думаю, что если твоим единственным инструментом является молоток, то на что угодно хочется смотреть как на гвоздь». Автоматизация — лишь один из подходов оптимизации и улучшения производственных процессов в здравоохранении, а искусственный интеллект — лишь один из инструментов такого подхода. Поэтому внедрение технологии ИИ в практическую медицину без понимания и должного описания соответствующего клинического контекста представляется бессмысленной тратой времени и ресурсов.
Под клиническим контекстом мы понимаем: цель, задачи (запросы), конкретные процессы и операции, нозологии, виды данных, функции, способы и формы представления результатов анализа, измеримые метрики качества — как единый комплекс специфической базовой информации для осознанного и эффективного применения конкретной технологии искусственного интеллекта в практическом здравоохранении.
Сразу хотим сказать о ключевом аспекте представления результатов анализа, то есть результатов работы искусственного интеллекта. Алгоритмы работы нейронных сетей крайне сложны для интерпретации и, следовательно, результаты их работы могут быть подвергнуты сомнению и отменены человеком. Отсутствие понимания того, как искусственный интеллект достигает результатов, является одной из причин низкого уровня доверия медицинских работников к соответствующим технологиям. Недопустимо в итоге автоматизации просто ставить врача или медицинскую сестру перед фактом по принципу «есть болезнь» / «нет болезни» или «назначить медикамент Х». Решения и предложения ИИ должны быть объяснимы, содержать пояснения, статистические величины (шансы, риски, вероятности) в соответствии с канонами доказательной медицины. Конечно, в зависимости от клинической ситуации медицинский работник может воспользоваться предложением ИИ без детализации — например, искусственный интеллект анализирует результаты КТ головного мозга до их описания рентгенологом и сразу сообщает нейрохирургу о наличии внутричерепного кровотечения для оказания экстренной медицинской помощи. Однако все равно должна быть предусмотрена возможность «вернуться» к решениям алгоритма и просмотреть их доказательную базу.
Таким образом, особое условие для широкого применения технологий искусственного интеллекта в практическом здравоохранении — это скорейшее развитие направления объяснимого ИИ (от англ. «explainable AI»). Оно подразумевает функциональную возможность программного обеспечения на основе ИИ объяснить/интерпретировать свое решение и степень уверенности в этом решении человеку. Соответствующие положения, например, в форме утверждения «системы ИИ должны включать элемент объяснимого ИИ для повышения интерпретируемости ИИ решений», уже появляются в нормативно-правовых документах ряда стран. В России Национальная стратегия развития искусственного интеллекта на период до 2030 года вводит такой основной принцип развития и использования ИИ, как прозрачность: объяснимость работы искусственного интеллекта и процесса достижения им результатов, недискриминационный доступ пользователей продуктов, которые созданы с использованием технологий искусственного интеллекта, к информации о применяемых в этих продуктах алгоритмах работы искусственного интеллекта. Следование этому принципу — строго обязательно для технологий искусственного интеллекта, разрабатываемых для здравоохранения. Целесообразность, объяснимость, верность принципам доказательной медицины, исходный высочайший уровень качества и точности алгоритмов — вот гарантия широкого принятия технологий искусственного интеллекта практическим здравоохранением.
Далее мы проведем обоснование клинического контекста для сферы лучевой диагностики и начнем с анализа основного производственного процесса — проведения и описания исследования.
§1. Основной производственный процесс службы лучевой диагностики
Цель основного производственного процесса службы лучевой диагностики (рис. 6) — предоставление качественного обоснованного ответа на клинический запрос лечащего врача путем организации, проведения, описания и контроля качества лучевого исследования определенной модальности.
В стандартном схематическом виде лечащий врач по результатам обследований иными способами и методами принимает решение о необходимости выполнения лучевого исследования, формирует соответствующее направление. Пациент осуществляет запись на исследование. Рентгенолаборант регистрирует исследование в информационной системе и непосредственно проводит его. Если исследование выполняется с диагностической целью, то один врач-рентгенолог интерпретирует его результаты и формирует описание. При необходимости или при наличии показаний (в том числе могут быть установлены нормативными документами) врач может обратиться за экспертной консультацией к более квалифицированному доктору, возможно — с субспециализацией. Обычно для таких консультаций применяются телемедицинские технологии. Если же цель исследования — профилактическая, скрининговая, то необходимо второе чтение — параллельная независимая интерпретация и описание другим рентгенологом. Финализированный протокол исследования направляют лечащему врачу, который формулирует диагноз и ведет дальнейшую работу с пациентом. В отношении результатов лучевого исследования осуществляется ретроспективный контроль качества. Обращает на себя внимание высокая степень информатизации данного процесса. Множество отдельных операций в его составе совершаются с применением тех или иных информационных технологий.
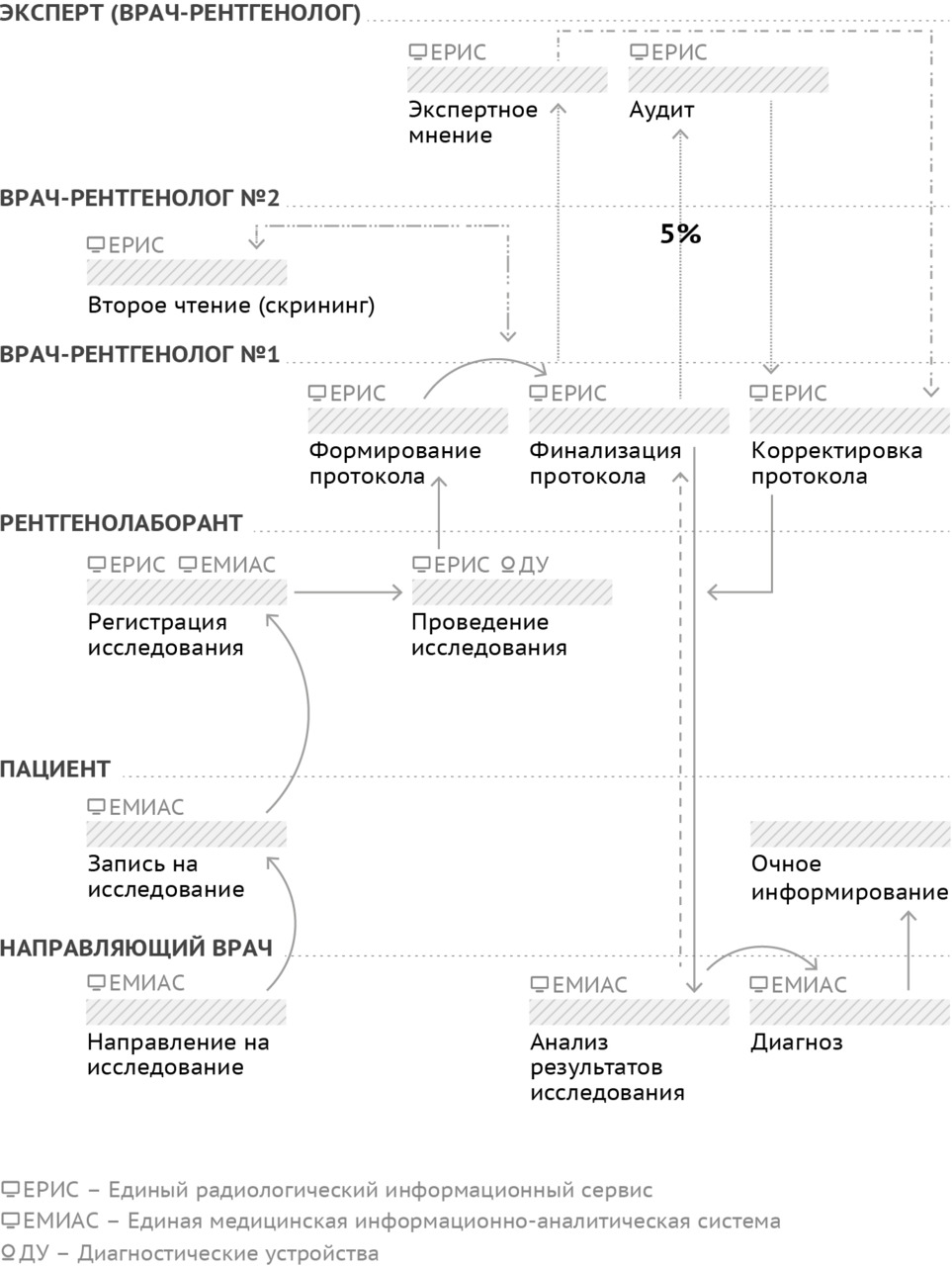
К сожалению, в таком варианте производственный процесс чреват дефектами, рисками, затрагивающими всех участников: для пациента это пролонгация или ошибочный диагноз, негативные исходы; для медицинских работников — угроза возникновения юридической ответственности (рис. 7). На этапе назначения исследования есть риски некорректного информирования пациента о методике, показаниях и противопоказаниях к исследованию (например, назначение МРТ без учета наличия у пациента кардиостимулятора). Лечащий врач может быть недостаточно осведомлен об оптимальном виде и способе диагностики, что приводит к необоснованным назначениям, выбору устаревших методик. А вот уже после получения описания — в самом конце процесса — лечащему врачу может вновь не хватить компетенций с точки зрения интерпретации результатов лучевого исследования в конкретных клинических обстоятельствах. Ситуация самостоятельного выбора пациентом слотов, с одной стороны, комфортна, но, с другой — чревата дисбалансом в загруженности диагностических устройств. Рентгенолаборант может допустить механическую опечатку при регистрации исследования, совершить ошибку при укладке пациента, выбрать некорректный протокол сканирования. Самое плохое, что ошибку рентгенолаборанта выявят только на следующем этапе, когда изображения будет анализировать врач-рентгенолог. Это означает, что диагноз не будет определен вовремя, а пациенту придется снова проходить весь цикл: идти к лечащему врачу, получать направление, записываться, ждать… Вполне вероятно, что в итоге пациент напишет жалобу.
На своем этапе процесса врач-рентгенолог, конечно же, может пойти по ложному пути гипо- или гипердиагностики. Второе чтение для скрининговых исследований зачастую просто невозможно из-за выраженного кадрового дефицита, в итоге либо чрезвычайно затягиваются его сроки, либо оно совершается формально. Затянуть подготовку описания может и длительное ожидание экспертной консультации. Исходя из сложившейся практики известно, что на ретроспективный контроль качества попадает в среднем около 5% исследований. Очевидно, что подавляющее большинство дефектов при этом остается не выявленными. Подчеркнем, контроль проводится ретроспективно — через несколько недель, а то и месяцев после проведения исследования. Фактически он может обнаружить и исправить проблемы компетенций медицинского персонала. Но для конкретного пациента он уже бесполезен чаще всего.
Таким образом, есть значительные риски пролонгации диагностики, отказа в проведении исследования, необходимости повторного сканирования ионизирующим облучением, гипо- или гипердиагностики, накопления систематических ошибок персоналом. Все это в итоге ограничивает доступность и качество медицинской помощи, вызывает социальное недовольство, психоэмоциональные проблемы, а также самые негативные исходы болезни.
Потенциальную роль технологий искусственного интеллекта в рамках основного производственного процесса службы лучевой диагностики трудно переоценить (рис. 7). Фактически автоматизация может быть (должна быть!) применена на всех его этапах.
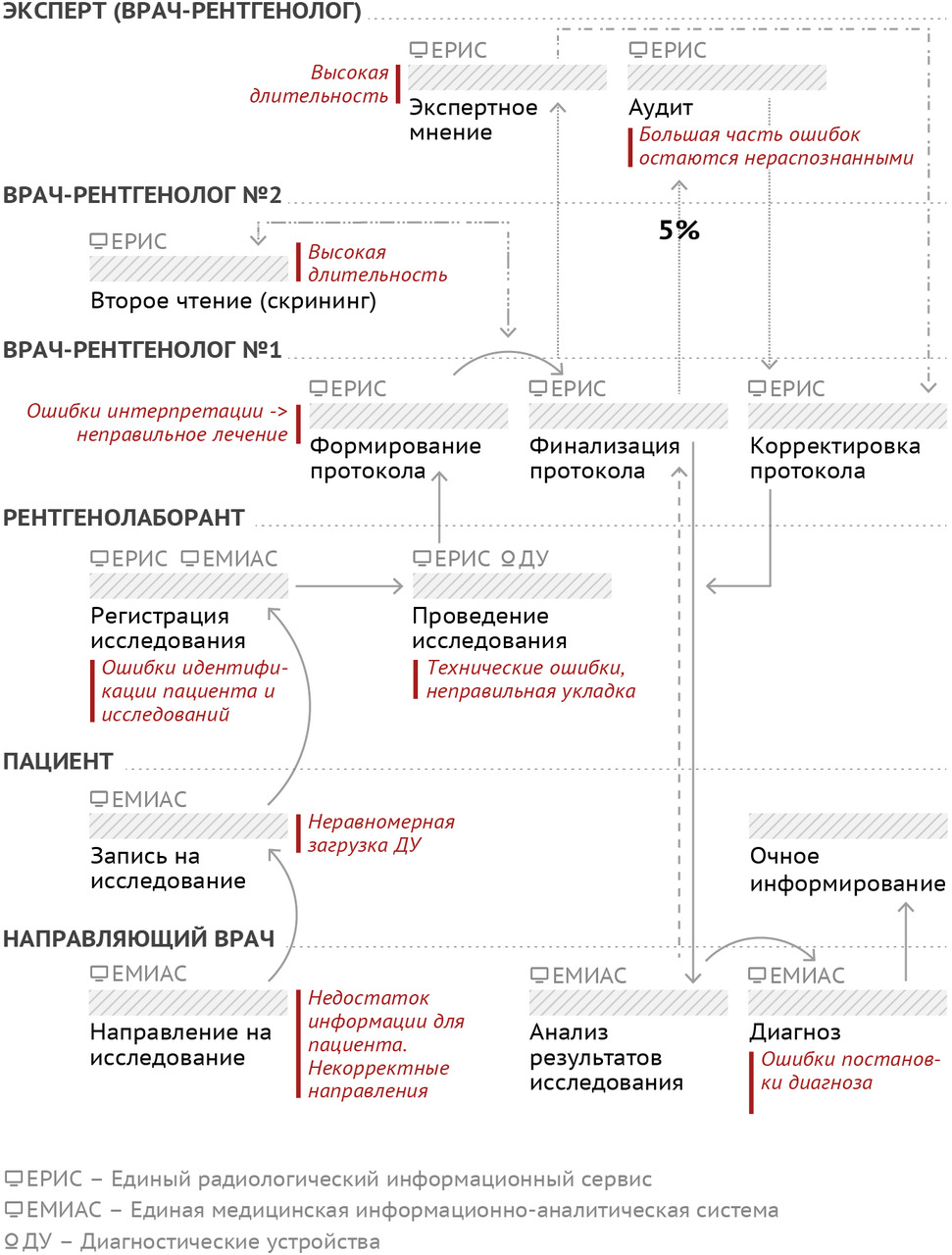
Для лечащего врача необходимы системы поддержки принятия решений как при назначении исследования, так и при его интерпретации, точнее — при дифференциальной диагностике по совокупности данных. Вклад автоматизации здесь составляет до 50%. Запись на исследование может быть полностью автоматизированной, учитывающей текущий статус загрузки и работоспособности парка оборудования, реальные сроки ожидания исследования, персональные данные и предпочтения пациента, возможности и специализацию отдельных медицинских организаций. Конечно, для удобства пациенту должны предлагаться несколько вариантов для записи, но не механически («все свободные»), а с учетом рациональности использования ресурсов системы здравоохранения и максимальной доступности медицинской помощи. Обеспечение идентичности персональных данных пациента на всех этапах процесса — это также функция для автоматизированного контроля. Здесь, пожалуй, стоит напомнить требование Национальной стратегии развития искусственного интеллекта на период до 2030 года по обеспечению за счет технологий ИИ повышения качества предоставления государственных и муниципальных услуг, а также снижения затрат на их предоставление.
Значителен вклад технологий ИИ в работу рентгенолаборанта при непосредственном проведении исследования. Алгоритмы могут проконтролировать правильность укладки, предупредить о противопоказаниях, провести немедленный технический аудит полученного изображения (если будут обнаружены дефекты, то можно сразу провести повторное сканирование, не отправляя пациента «на второй круг»). В данном случае вклад технологий ИИ может достигать 75%.
При проведении первичного описания уровень автоматизации составляет не менее 50%: ИИ может приоритизировать исследования в рабочем списке автоматизированного рабочего места (ускорится описание случаев с признаками болезни); отметить на изображении патологические признаки и, возможно, измерить их (снизится риск пропусков патологии); помочь сопоставить текущие результаты для данного пациента с предыдущими исследованиями; сформировать шаблон описания. Таким образом, комплексно повысятся скорость и качество описаний. Второе чтение может быть полностью автоматизированным — все скрининговые исследования могут на потоке анализироваться алгоритмом ИИ. Тогда полностью устраняется проблема кадрового дефицита и достигается максимальная точность профилактических осмотров. Немаловажное значение имеет и скорость — результаты скринингов с подозрением на наличие патологии не будут дожидаться своей очереди в огромном рабочем списке заваленного работой врача, а сразу «будут подняты наверх» с тревожной отметкой, быстрее будут описаны и направлены лечащему врачу. Следовательно, пациент быстрее получит нужное и иногда жизнеспасающее лечение. Системами поддержки принятия решений может пользоваться и врач-эксперт, в том числе с учетом особенностей субспециализации.
Благодаря комбинациям технологий компьютерного зрения и распознавания естественного языка можно добиться охвата контролем качества 100% исследований. Причем такой контроль будет происходить практически в реальном режиме времени (рис. 8). Дефекты можно будет устранить заблаговременно, то есть можно уже говорить о профилактике ошибок, а не борьбе с ними.
Таким образом, технологии искусственного интеллекта потенциально позволяют автоматизировать ряд операций в составе основного производственного процесса службы лучевой диагностики для снижения рисков дефектов и ошибок, повышения производительности труда, увеличения скорости постановки диагноза и начала специального лечения.
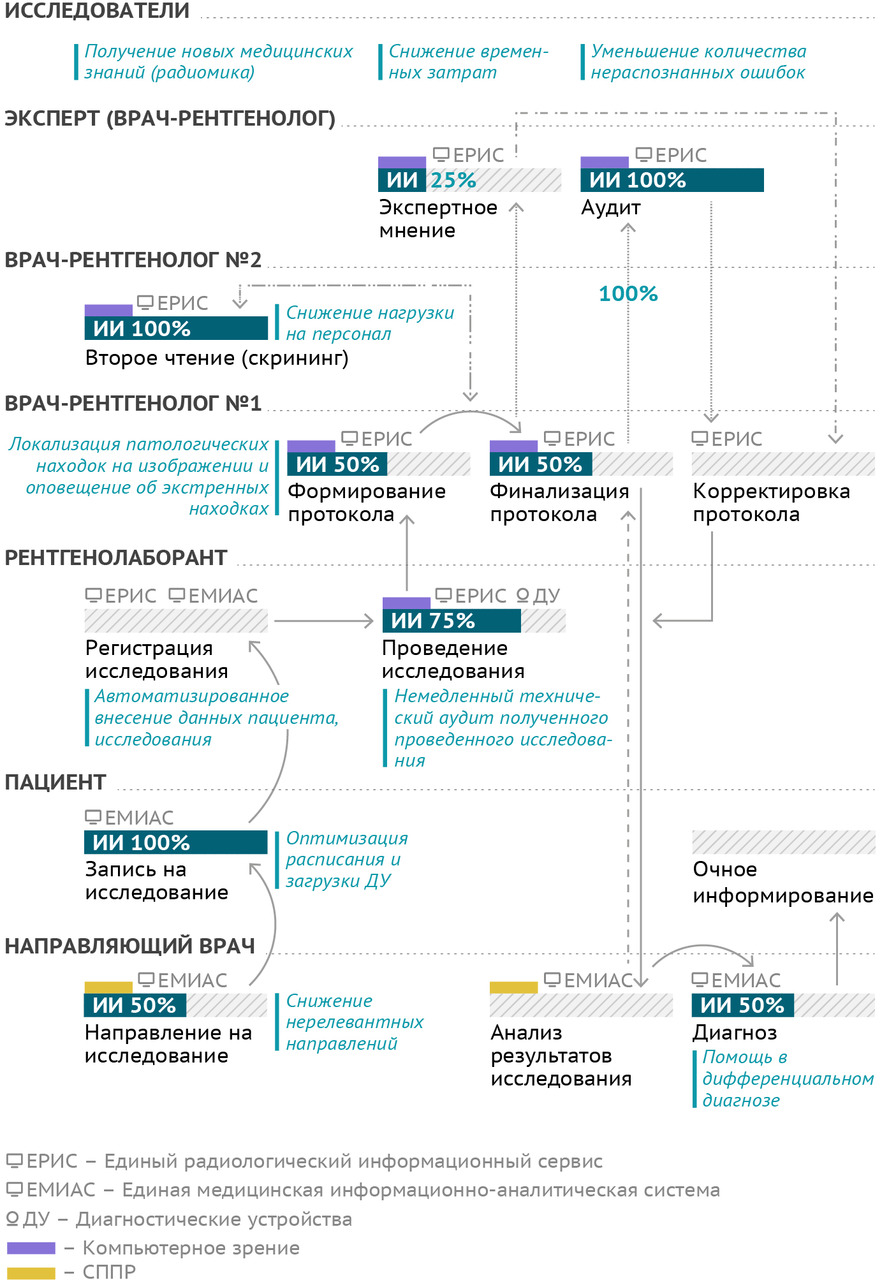
Далее мы проанализируем запросы системы здравоохранения, разберем ожидания врачебного сообщества и проанализируем потребность в автоматизации лучевой диагностики с позиции эпидемиологии и общественного здоровья.
§2. Запрос системы здравоохранения Российской Федерации
Перспективное становление технологий искусственного интеллекта должно быть согласовано с общим направлением развития отечественного здравоохранения. В России до 2024 г. выполняется Национальный проект «Здравоохранение», включающий ряд федеральных проектов. К наиболее релевантным нашей теме метрикам Национального проекта относятся:
— снижение уровней летальности и смертности от онкологических заболеваний;
— повышение выявляемости злокачественных новообразований на ранних стадиях;
— увеличение охвата населения профилактическими исследованиями;
— наличие в субъектах референс-центров для борьбы с онкологическими заболеваниями.
Представляется перспективным широкое внедрение технологий искусственного интеллекта для:
— работы с результатами массовых профилактических осмотров;
— выявления признаков онкологических заболеваний, особенно на ранних стадиях;
— поддержки решений по оптимальной, предписанной маршрутизации пациентов;
— оппортунистического поиска предикторов или явных проявлений иных особо значимых патологий;
— формирования проектов описаний с использованием установленных классификаций.
С учетом аспекта качества, работа решений на основе технологий искусственного интеллекта должна быть точной и сбалансированной. Категорически недопустимо создание дополнительной необоснованной нагрузки на систему здравоохранения: например, за счет избыточной генерации ложноположительных или клинически нецелесообразных результатов (к последним, в частности, относятся очаги в легких объемом менее 5 мм, которые невозможно верифицировать патогистологически или иным способом).
В соответствии с действующим законодательством программное обеспечение на основе технологий ИИ должно быть интегрировано с информационными системами в сферу здравоохранения субъектов РФ и/или медицинских информационных систем, в том числе референс-центров.
§3. Эпидемиологический и организационный аспекты
Онкологические заболевания по-прежнему представляют значительную угрозу и проблему для человечества. По официальным данным в Российской Федерации в 2018 году показатель распространенности злокачественных новообразований составил 2 562,1 на 100 000 населения. В течение 10 лет отмечается рост этого параметра на 39,5%. С одной стороны, такая динамика обусловлена положительным развитием отечественного здравоохранения: значимо улучшается выявляемость и выживаемость онкологических больных. С другой стороны, имеется истинный рост заболеваемости, связанный с различными неблагоприятными факторами.
Об улучшении показателей выживаемости онкологических больных свидетельствует динамика индекса накопления контингента больных со злокачественными новообразованиями: за 10 лет данный показатель вырос с 5,7 до 6,9. Вместе с тем в структуре смертности населения России злокачественные новообразования занимают второе место (16,1%), уступая только болезням системы кровообращения (46,8%). В целом показатель запущенности (то есть выявление болезни на IV стадии) достигает 23,9%. На этом фоне уровень одногодичной летальности составляет 25,8%, что означает: почти четверть больных со злокачественными новообразованиями узнают о своем диагнозе только на практически безнадежной стадии, а в течение года после установления диагноза умирает каждый четвертый пациент. Невзирая на положительную динамику исходов и некоторое снижение смертности, проблема онкологических заболеваний еще явно далека от окончательного решения.
Высокий показатель запущенности свидетельствует о необходимости развития и активного совершенствования программ профилактических осмотров — скринингов, направленных на как можно более раннее выявление и своевременное лечение злокачественных новообразований. Методологии и технологии таких осмотров различны. Скрининг может быть селективным (исследования проводятся только в группах риска) или неселективным (проводятся исследования всего населения). Критично важно наличие эффективной системы маршрутизации лица с выявленным подозрением на опухоль для всестороннего дообследования и специализированного лечения. Так, в 2016–2020 гг. НПКЦ ДиТ ДЗМ инициировал и обеспечил проведение двух программ скрининга (ЗНО легких и молочной железы). В результате была сформирована методология, обеспечивающая значимый прирост выявляемости на ранних стадиях, а значит влияющая и на исходы. Таким образом, профилактические исследования могут внести значительный вклад в преодоление проблемы онкологических болезней, что полностью соответствует концепции и задачам развития здравоохранения Российской Федерации.
Какие же состояния несут наибольшую угрозу? Для обоих полов ведущими локализациями в общей структуре онкологической заболеваемости являются: кожа (12,6%, с меланомой — 14,4%), молочная железа (11,4%), трахея, бронхи, легкое (9,9%). У мужского населения первое место занимают опухоли трахеи, бронхов, легкого (16,9%); у женского — рак молочной железы (20,9%). Вполне закономерно, что обе нозологии — это одновременно и ведущие причины смерти. У мужчин более четверти (25,9%) смертей обусловлены раком трахеи, бронхов, легкого. У женщин злокачественные опухоли молочной железы (16,2%). Далее следуют опухоли желудочно-кишечного тракта, кожи, внутренних мочеполовых органов. Примечательно, что именно лучевая диагностика помогает своевременно выявлять ЗНО легких и молочной железы (в то время как для других локализаций — используются иные инструментальные и лабораторные методы: эндоскопии, дерматоскопии, тестов на скрытую кровь и онкомаркеры).
Казалось бы, общая ситуация очевидна. Есть две формы злокачественных новообразований, лидирующие по распространенности и рискам смерти. У многих пациентов обе формы выявляются несвоевременно. Для решения этой проблемы есть программы скринингов с помощью лучевой диагностики с проверенной методологией. Почему же онкология до сих пор не побеждена?
Дело в том, что с позиций практической лучевой диагностики скрининги имеют ряд существенных проблем:
1. Нагрузка. Профилактические осмотры подразумевают проведение однотипных стандартизированных исследований у значительных контингентов лиц (от десятков тысяч до миллионов). Причем большинство этих людей здоровы; во всяком случае не имеют онкологической патологии, которую и пытаются обнаружить при скринингах. Для проведения исследования необходимо задействовать максимально большие аппаратные мощности, а также иные виды ресурсов системы здравоохранения.
2. Кадры. Для проведения такого колоссального объема исследований и интерпретации (описаний) их результатов требуется значительное, постоянно нарастающее количество среднего медицинского персонала и врачей. И это на фоне существующего дефицита квалифицированных кадров — типичной проблемы современного здравоохранения как на национальном, так и на общемировом уровнях.
3. Человеческий фактор. При описании результатов тысяч скрининговых исследований врач-рентгенолог в подавляющем большинстве случаев имеет дело с нормальной картиной, выискивая пациента с опухолью «как иголку в стоге сена». Поэтому при просмотре сотен однотипных нормальных исследований постоянно растет риск пропуска значимой находки, и та самая «иголка» может быть просто упущена. Для минимизации таких рисков применяют двойное чтение, когда результаты каждого исследования независимо интерпретируют два врача. Но в данном случае мы возвращаемся к ранее обозначенной проблеме — установленный объем дефицита специалистов удваивается.
4. Квалификация. Обнаружить рак сложно. Для качественного скрининга врач-рентгенолог должен иметь достаточный опыт, а иногда — как в случае с маммографией для выявления ЗНО молочной железы — еще и субспециализацию. Таким образом, возникает двойной дефицит не просто врачей, но специалистов наивысшего уровня.
Итак, общая ситуация крайне сложна: на фоне дефицита высококвалифицированных специалистов нужно проводить и описывать (качественно и быстро!) миллионы однотипных исследований с преимущественной нормой.
Дефицит кадров можно проиллюстрировать следующим образом: в соответствии с целями Национального проекта «Здравоохранение» должно быть достигнуто снижение смертности от новообразований до 185 случаев на 100 тыс. населения (на 7,8%). Для этого установлены целевые показатели ранней выявляемости. Если говорить о двух самых значимых формах ЗНО — опухолях легкого и молочной железы — то для достижения метрик Национального проекта потребуется выполнить около 1,8 миллиона низкодозовых компьютерных томографий и 14,8 миллиона маммографий. Для этого необходимо дополнительно задействовать порядка 5 400 врачей-рентгенологов, в то время как, по официальным данным, укомплектованность штатных должностей врачей-рентгенологов физическими лицами составляет около 59%. Физически увеличить количество врачей-рентгенологов, тем более необходимой специализации, не получится. Потребность всегда будет опережать реальное число должным образом подготовленных специалистов, что свидетельствует о том, что скрининги проводятся в недостаточном объеме или с неудовлетворительным качеством.
Эта ситуация идеальна для автоматизации посредством технологий искусственного интеллекта. Должным образом обученный алгоритм может беспрерывно анализировать результаты скрининговых исследований, выявлять подозрительные находки и направлять их для интерпретации квалифицированным врачом. Это и есть целевая модель скрининга будущего, которая может реально снизить смертность от злокачественных опухолей. Конечно, при условии очень качественного, можно сказать ответственного, обучения алгоритмов и масштабности внедрения.
§4. Ожидания врачебного сообщества
В ходе собственного аналитического и научного исследования проблемы искусственного интеллекта мы активно общались и вели дискуссию с профессиональным сообществом, также было организовано участие в масштабном опросе врачей-рентгенологов под эгидой Европейского общества радиологии. Всего были собраны и проанализированы ответы почти 675 респондентов из 39 стран Евразии и Северной Америки, в том числе из Российской Федерации. В течение проведения данных мероприятий стало известно, что примерно 20% врачей-рентгенологов и радиологов уже используют те или иные инструменты ИИ в своей работе.
В глобальной перспективе наиболее востребованной врачами будет являться автоматизированная обработка результатов исследований по таким модальностям (здесь и далее в порядке убывания), как:
— компьютерная томография;
— маммография или томосинтез молочной железы;
— магнитно-резонансная томография;
— позитронно-эмиссионная томография (в т.ч. в составе гибридных методик).
Вместе с тем наиболее ожидаемы решения на основе ИИ для:
— анализа диагностических изображений молочной железы;
— поиска признаков онкологических заболеваний, прежде всего на изображениях органов грудной клетки;
— молекулярной визуализации;
— анализа диагностических изображений центральной нервной системы.
Примечательно, что с учетом клинического контекста ожидания врачебного сообщества относительно целей применения ИИ таковы:
— скрининг (массовые профилактические осмотры);
— стадирование новообразований;
— количественные измерения биомаркеров;
— постпроцессинг (в т.ч. для ускорения процессов получения изображений для анализа);
— генерация шаблонов описаний;
— поддержка в принятии решений при наличии симптомов.
Таким образом, профессиональным сообществом явным образом высказан запрос на автоматизацию массовых профилактических (скрининговых) исследований, в том числе исследований органов грудной клетки и молочной железы. Безусловно, скрининги не исчерпываются онкологической патологией. Специальные массовые осмотры методами лучевой диагностики проводятся для выявления туберкулеза, сердечно-сосудистых заболеваний, остеопороза, наконец, ЗНО иных локализаций. Это необходимо учитывать при разработке клинического контекста применения ИИ.
Проанализировав запрос профессиональной аудитории, мы, к сожалению, увидели вновь дисбаланс между мнениями разработчиков и врачей. По обобщенным данным среди создателей ИИ предпочтение отдается следующим модальностям: МРТ — 40% алгоритмов, КТ — 27%, УЗИ — 6%, маммография — 4%, рентгенография — 3%, ПЭТ/КТ — 1%. Распределение интереса разработчиков по анатомическим областям таково: центральная нервная система — 40%, опорно-двигательная система — 8%, сердечно-сосудистая система и молочная железа — по 7% каждая, мочевыводящая система, грудная полость и брюшная полость — по 6% каждая. Как видим, целевые модальности и анатомические локализации фигурируют всего лишь в 10–30% случаев.
Впрочем, преобладание мнения врачей очевидно, что иллюстрируется показателями регистрации технологий ИИ в качестве медицинских изделий. Например, в США среди модальностей лидируют КТ и МРТ, среди локализаций — центральная нервная система, органы грудной клетки, молочная железа. Следовательно, динамика регистраций алгоритмов в большей степени соответствует реальным потребностям здравоохранения и запросам врачебной аудитории. Вместе с тем мы не намерены преуменьшать роль автоматизированного анализа КТ и МРТ в нейровизуализации. Сложность диагностики заболеваний и повреждений центральной нервной системы, необходимость экстренного принятия решений во множестве ситуаций также представляет собой значительный потенциал для технологий искусственного интеллекта.
§5. Клинический контекст
В настоящее время технологии искусственного интеллекта находятся на первом, начальном, этапе системного внедрения в сферу лучевой диагностики. В данном случае оптимальным клиническим контекстом для их применения будет следующий:
1. Цель: достижение максимального уровня доступности и качества лучевых исследований. Уровень доступности определяется непрерывным выполнением описаний результатов исследований с опережением установленных законодательством норм времени. Уровень качества определяется удельным весом ложноположительных и ложноотрицательных результатов, обуславливающих клинически значимые расхождения.
2. Процесс: первичное или двойное описание врачом-рентгенологом результатов лучевого исследования, выполненного:
— в рамках массового профилактического осмотра (скрининга);
— при наличии высоких шансов выявления онкологической патологии (исходя из анатомической области);
— при оказании экстренной и неотложной медицинской помощи.
3. Функции:
— анализ соответствия номенклатуры заявленной услуги фактическому изображению;
— технический анализ диагностической ценности изображения;
— приоритизация исследований в автоматизированном рабочем месте врача для первоочередной интерпретации результатов с риском патологии;
— локализация патологических находок на диагностическом изображении с предоставлением информации о вероятности наличия патологии (а также иных данных в рамках концепции объяснимости решений ИИ);
— морфометрия патологических находок;
— сравнение результатов исследований пациента, выполненных в динамике;
— формирование проекта описания результатов исследований в виде структурированного документа и с использованием принятых классификаций;
— предоставление объяснений и подтверждений принятых решений, в том числе в соответствии с принципами доказательной медицины.
4. Приоритеты модальностей:
— компьютерная томография (в том числе низкодозная);
— маммография;
— рентгенография;
— магнитно-резонансная томография.
5. Приоритеты локализаций:
— органы грудной клетки;
— молочная железа;
— центральная нервная система.
6. Приоритеты нозологий:
— злокачественные новообразования;
— социально значимые инфекционные заболевания (туберкулез, новая коронавирусная инфекция);
— состояния, требующие экстренной или неотложной помощи;
— заболевания сердечно-сосудистой системы (в том числе их предикторы);
— иные социально значимые заболевания.
На текущем (начальном) этапе должны быть научно обоснованы методологии и сформирована доказательная база безопасности и результативности применения технологий искусственного интеллекта в лучевой диагностике. Это создаст основу для дальнейшего развития, появления новых этапов за счет расширения перечня процессов (в том числе включения участков работы рентгенолаборантов, направляющих лечащих врачей), модальностей, локализаций, нозологий.
Глава 4. КЛАССИФИКАЦИЯ И МЕТОДОЛОГИЯ ПОДГОТОВКИ ЭТАЛОННЫХ НАБОРОВ ДАННЫХ
Философы-футуристы обычно называют данные «топливом» для технологий искусственного интеллекта. Мы не согласны с этим утверждением и вот почему. Хаотичные массивы необработанных так называемых «сырых» данных непригодны для создания качественного ИИ в сфере медицины, так же как практически непригодна методология машинного обучения «без учителя» в силу колоссальных рисков и высочайшей цены ошибки, которые таит в себе сфера здравоохранения. В медицине данные требуют предпроцессинга, стандартизации, разметки — только тогда появляется возможность с их помощью разработать алгоритм для эффективного решения конкретной клинической задачи.
Сферы здравоохранения, медицины, здоровьесбережения содержат потенциально неисчислимые объемы информации. В качестве минимальной единицы измерения количества информации здесь можно использовать эксабайт. Однако наличие таких ресурсов совсем не гарантирует реализуемость востребованного искусственного интеллекта. Колоссальные массивы данных бесполезны без научно обоснованной постановки клинических задач и описания клинического контекста применения ИИ.
Принцип «Больше данных — больше интеллекта» в чем-то созвучен утверждению «Врач учится всю жизнь». Тем не менее с учетом создания конкретного продукта для здравоохранения необходимости в доступе к бесконечно пополняемому массиву данных нет. На этапе планирования разработки должны определяться целевые метрики качества и точности будущего алгоритма; соответственно определяется и объем данных, требуемый для их достижения. Таким образом, по нашему мнению, данные — это не «топливо», а «двигатель» искусственного интеллекта, требующий целеполагания, планирования, подготовки и управления.
Дополняя положение из Национальной стратегии развития искусственного интеллекта на период до 2030 года, можно сказать, что для поиска интеллектуальной вычислительной системой в сфере здравоохранения непредвзятого доказательного решения требуется ввести репрезентативный, релевантный и корректно размеченный набор биомедицинских данных. В соответствии с вышеназванным документом приняты следующие определения.
Набор данных — совокупность данных, прошедших предварительную подготовку (обработку) в соответствии с требованиями законодательства Российской Федерации об информации, информационных технологиях и о защите информации и необходимых для разработки программного обеспечения на основе искусственного интеллекта.
Разметка данных — этап обработки структурированных и неструктурированных данных, в процессе которого данным (в том числе текстовым документам, фото- и видеоизображениям) присваиваются идентификаторы, отражающие тип данных (классификация данных), и (или) осуществляется интерпретация данных для решения конкретной задачи, в том числе с использованием методов машинного обучения.
Медицинские данные — обширное понятие, включающее в себя разнообразные типы документов, возникающих в ходе медицинской деятельности. Несмотря на то, что понятие «медицинские данные» не имеет отдельного упоминания в Федеральном законе «Об основах охраны здоровья граждан в Российской Федерации», о нем косвенно сказано в ст. 13 упомянутого Федерального закона, а именно — в контексте соблюдения врачебной тайны. Под медицинскими данными в статье понимаются сведения о факте обращения гражданина за оказанием медицинской помощи, состоянии его здоровья и диагнозе и иные сведения, полученные при его медицинском обследовании и лечении. В контексте своей работы под медицинскими данными, в первую очередь, мы понимаем результаты клинических, лабораторных и инструментальных исследований в виде текстовых, графических изображений, видеорядов и проч.
Во многих клинических и лабораторных исследованиях медицинские данные играли и играют большую роль с момента начала применения научного метода в медицине. Эта роль сводилась к пониманию наборов данных как вспомогательного материала для проведения аналитических расчетов в целях проверки или опровержения поставленной гипотезы.
С приходом цифровых способов обработки больших массивов данных появилась потребность в правильном структурировании и подготовке данных, так называемой машиночитаемости. Это связано с тем, что исходные причины их возникновения не предполагали ретроспективной автоматической обработки: медицинские данные служат целью оказания медицинской помощи конкретному пациенту (от постановки правильного диагноза до назначения и проведения эффективного лечения). Однако первично цифровой характер многих результатов инструментальных исследований, а также активное внедрение современных систем диагностики и лечения, использующих такие данные, способствует пересмотру концепции медицинских данных как вспомогательных инструментов для оказания медицинской помощи.
Для задач обучения нейронных сетей, входящих в понятие технологий искусственного интеллекта, хорошо структурированные данные являются ключевым фактором успеха, поскольку результаты работы алгоритмов при анализе новых, ранее не встречаемых медицинских данных, напрямую зависят от того, на каких наборах данных были обучены нейронные сети. На сегодняшний день алгоритмы искусственного интеллекта уже активно используются во многих аспектах бытовой жизни (например, персональные голосовые помощники) и профессиональной деятельности (в авиации, логистике и др.).
Завершающим этапом разработки алгоритмов искусственного интеллекта до практического применения является их тестирование. Для этих целей обычно используется подвыборка из основного набора данных для обучения (например, 20%), которая изолируется от остальных 80% и не используется в процессе обучения. В случае независимого тестирования (например, для проведения сравнения результатов анализа между несколькими алгоритмами) может использоваться отдельный эталонный набор данных, в котором тестирующему заранее известны категории каждой из единиц данных (например, отношение единицы данных к категориям «норма» и «патология»). Для классической задачи бинарного классификатора часто используются сбалансированные «датасеты», в которых две категории представлены в равных частях.
Другое назначение наборов данных — техническая проверка алгоритмов на правильность обработки исследований одной модальности, полученных на аппаратах различных производителей. В связи с особенностями различных моделей входные данные для алгоритма могут отличаться как по техническим характеристикам (например, размер матрицы изображения), так и по передаваемой вместе с ними метаинформации (например, перечень DICOM-тегов).
Набор данных (синоним-жаргонизм «датасет» от англ. dataset) отличается от простого сбора медицинских данных тем, что он наделен особыми качествами, к которым относятся: унификация и структурированность данных; отсутствие грубых неточностей, ошибочных исследований; наличие дополнительной информации (категории и значения признаков или характеристик элементов данных); наличие сопроводительной документации.
Существует ряд трудностей, с которыми можно столкнуться при составлении медицинских наборов данных:
1. Вопросы этического характера: деперсонализация данных, «серая зона» законодательства о персональных данных применительно к медицинским данным, страх раскрытия врачебной тайны.
2. Вопросы политического характера: вопрос трансграничной передачи данных.
3. Сложность получения самих данных: для получения медицинских данных требуется пройти весь процесс от начала регистрации пациента, проведения диагностики и исследования, где участвует медицинский персонал и используется медицинское оборудование, до составления заключения и передачи этих данных в единую систему хранения медицинских данных.
4. Сложнейшая структура организации данных с рядом специфических параметров, которые необходимо фильтровать для использования ИИ (в отличие от банковских транзакций, баз данных спамерских атак, распознавания номеров автомобилей и других наборов данных).
5. Разметка данных: может быть осуществлена экспертной группой врачей. Стоит отметить наличие данных, согласно которым в определенных случаях возможна разметка краудсорсингом (снижение вероятности ошибки путем усреднения).
6. Репрезентативность: сформированная выборка отражает общие характеристики популяции (генеральной совокупности). Репрезентативность также может относиться к сбалансированному соотношению элементов по каждой выбранной категории (используемое оборудование, классы разметки и т.п.). При корректно сформированной выборке выводы и заключения по исследованию будут верны и могут быть перенесены на уровень популяции.
Одной из основных сложностей, связанных с подготовкой наборов данных для машинного обучения и валидации алгоритмов искусственного интеллекта, является разнообразие характеристик, меняющихся от задачи к задаче. К основным характеристикам наборов данных относятся:
1. Формат данных. Может различаться во входных и выходных данных. Ко входным относятся данные, служащие материалом для составления набора. Примерами форматов входных данных лучевой диагностики служат изображения магнитно-резонансной томографии (МРТ), компьютерной томографии (КТ), рентгенографии (РГ) формата DICOM, клинические данные в текстовом формате, разметка изображений формата json и другие. Выходные данные — продукт готового набора. Формат выходных данных варьируется, может быть оптимизирован под задачу и заданные условия.
2. Объем набора данных, количество занимаемого пространства на диске.
3. Размер набора данных, показывающий количество единиц данных, содержащихся в наборе. Единица данных устанавливается в зависимости от задачи и принципа структурирования данных в наборе. В случае данных лучевой диагностики таким примером может стать одно исследование или одна серия изображений исследования, так как представляет собой минимальную самостоятельно информативную единицу данных.
4. «Сырые» и агрегированные данные. «Сырые» данные — это необработанные данные медицинских исследований в своей исходной форме (без обработки и предобработки, без применения фильтров и других методов анализа). Агрегированные данные — это сырые данные, прошедшие какую-либо форму обработки, анализа и прочих манипуляций.
5. Тип набора данных (его логическое представление). Набор может быть представлен в виде непрерывной последовательности записей, в виде отдаленных друг от друга членов и т. п.
6. Формат хранения набора данных.
7. Доступ к набору данных. Может быть организован как открытый, так и закрытый доступ.
8. Прочее. У каждого типа данных есть свой набор спецификаций и характеристик.
Вследствие широкого разнообразия характеристик данных, методов их сбора и способов организации в единый набор появляется большое множество наборов данных, каждый из которых может радикально отличаться от другого, что усложняет их поиск и применение. Особенно это касается случаев, где есть необходимость в большом количестве входных данных для обучения или, как еще один пример, необходимость в дополнительном наборе данных с той же спецификацией, но без повторения элементов набора, на которых алгоритм уже был обучен. Кроме того, обучение и развитие алгоритмов с искусственным интеллектом напрямую зависит от качества набора данных.
Под качеством набора принято понимать его структурированность, однородность, репрезентативность, сбалансированность по классам, отсутствие выпадающих значений, наличие экспертной разметки (при необходимости), наличие описания модели данных и документации. Кроме того, в лучевой диагностике наблюдается спрос и нехватка открытых наборов данных для обучения, а также эталонных данных для валидации и калибровки (в ограниченном доступе) алгоритмов ИИ. Вышеперечисленные проблемы решаются путем стандартизации процесса сбора, обработки и проверки набора данных, чтобы упростить их использование и повысить эффективность для исследований в области машинного обучения.
Источниками для подготовки набора данных могут являться:
1. Открытые наборы данных (доступные для переработки).
2. Базы данных, к которым есть доступ.
3. Иные наборы данных, права использования которых позволяют создавать на их основе новые результаты интеллектуальной деятельности (например, полученные в рамках коммерческого договора на оказание услуг по разметке набора данных).
§1. Требования к эталонным наборам данных
Для обучения, внутренней и внешней валидации, клинико-технических и клинических испытаний технологий искусственного интеллекта применяют эталонные данные — наборы биомедицинских данных. Требования к таким наборам разработаны нами в ходе аналитических и научных исследований.
В лучевой диагностике набор эталонных данных — это упорядоченная совокупность:
— диагностических изображений одной модальности и/или однотипных медицинских документов (например, протоколов описаний результатов исследований);
— сведений о наличии, характере и локализации патологических изменений на изображениях; для текстовых документов — библиотеки ключевых слов, словосочетаний и их критичных сочетаний;
— сведений о верификации диагноза (опционально).
Информация о наличии, характере и локализации патологических изменений (в том числе в соответствии с Международной классификацией болезней) может быть подтверждена объективно — в таком случае набор данных именуется верифицированным. Подробнее об этом будет сказано далее.
Размер эталонного набора данных (математически — размер выборки) для оценки диагностических характеристик алгоритма ИИ устанавливается с помощью методик определения размера выборки для пропорций. Для каждого конкретного случая (клинического сценария) должны быть заданы желаемые параметры точности оценки диагностических характеристик алгоритма ИИ; необходимо задать ожидаемую пропорцию и желаемую точность (ширину доверительного интервала) ее оценки. Надо учитывать, что чем выше желаемая точность оценки (т.е. чем уже доверительный интервал) и чем ближе пропорция к 50%, тем большее количество размеченных исследований понадобится включить в набор данных.
Эталонный набор данных должен быть проверен профильной медицинской научно-исследовательской организацией на предмет полноты и качества содержащейся в нем информации. Рекомендуется при проведении клинических испытаний применять эталонные наборы данных, имеющие государственную регистрацию в качестве базы данных.
Эталонный набор данных должен содержать такие сведения (описательного характера):
1. Номер свидетельства о государственной регистрации базы данных (рекомендательно).
2. Характеристика популяции (гендерно-возрастные показатели, этнический состав, регионы проживания и т.д.); сведения о деперсонализации; сведения о медицинских организациях, послуживших источниками для формирования набора данных.
3. Характеристика исследований: анатомическая область (и), модальность, проекции, типы медицинских изделий — диагностических приборов, виды и характеристики протоколов исследований.
4. Целевая патология в соответствии с Международной классификацией болезней.
5. Общее количество клинических случаев, исследований, изображений, документов и их распределение по диагностическим группам.
6. Соотношение случаев «норма»: «патология» (случаи «патология» могут быть разделены на несколько подклассов).
7. Сведения о верификации (патогистологическом или ином окончательном диагнозе).
8. Методология разметки (ранее представленной в виде научных публикаций, методических рекомендаций или патентов).
Эталонный набор данных должен отвечать таким требованиям:
1. Структура набора данных должна соответствовать поставленной цели его формирования (решаемой клинической задаче).
2. Включаемые данные должны быть получены из реальной клинической практики (не допускается получение синтезированных данных, применение фильтров и математических средств постобработки при выгрузке данных из медицинских информационных систем).
3. Соотношение «норма»: «патология» должно соответствовать распространенности целевой патологии в популяции.
4. При формировании эталонного набора должны использоваться данные из нескольких медицинских организаций.
5. Демографические, социально-экономические характеристики и основные показатели здоровья пациентов, чьи данные включаются в эталонный набор данных, должны соответствовать усредненным характеристикам популяции территории, на которой планируется использование ИИ.
6. Обязательно включение в набор исследований, выполненных с нарушением методики, содержащих дефекты, а также — исследований аналогичной модальности, но иной анатомической области.
7. Количество включенных элементов (клинических случаев, наблюдений, исследований) должно быть достаточным для достижения статистической значимости результата работы алгоритмов ИИ.
8. Планируемый размер эталонного набора данных должен быть обоснован в протоколе исследования, исходя из статистических соображений и желаемой точности оценки основных метрик, указанных выше.
9. Разметка должна быть проведена с использованием стандартизированной терминологии — т.н. тезауруса (кодированной библиотеки типовых формулировок, соответствующих нормативно-правовой документации, клиническим рекомендациям или рекомендациям профессиональных врачебных ассоциаций).
10. Подготовка и разметка должны быть проведены подготовленными техническими и медицинскими специалистами, имеющими соответствующие навыки и компетенции.
11. Эталонные наборы данных, используемые в процессе клинических испытаний для регистрации ПО в качестве медицинского изделия, не должны быть публично доступны (для исключения возможности обучения алгоритмов ИИ на эталонных наборах данных).
§2. Классификация наборов данных
Наборы данных для обучения и тестирования алгоритмов искусственного интеллекта можно классифицировать различными способами. Например, выделяют наборы со структурированными, частично структурированными и неструктурированными данными.
Мы рекомендуем разделять «датасеты» по источникам их формирования, условиям использования, типам биомедицинских и клинических данных, по временным характеристикам, файловой структуре, наконец — по видам задач, для решения которых наборы сформированы и т. д. Однако, изучив имеющиеся подходы с позиций их практического применения в лучевой диагностике, мы пришли к выводу об их несостоятельности. Предложенные классификации носили либо чересчур абстрактный характер, либо имели значение для математиков-разработчиков, но были неприменимы врачами. Некоторые систематики слишком специализированы, посвящены отдельным, относительно «узким» задачам.
В итоге было принято решение о создании совершенно иной классификации наборов данных для лучевой диагностики, которая должна была отличаться:
— клинической ориентированностью,
— универсальностью,
— простой применения.
Использовав аналитические методы научной работы, мы предложили две классификации: по диагностической ценности и по функциональному назначению.
В таблице 6 приведена классификация наборов данных по диагностической ценности.
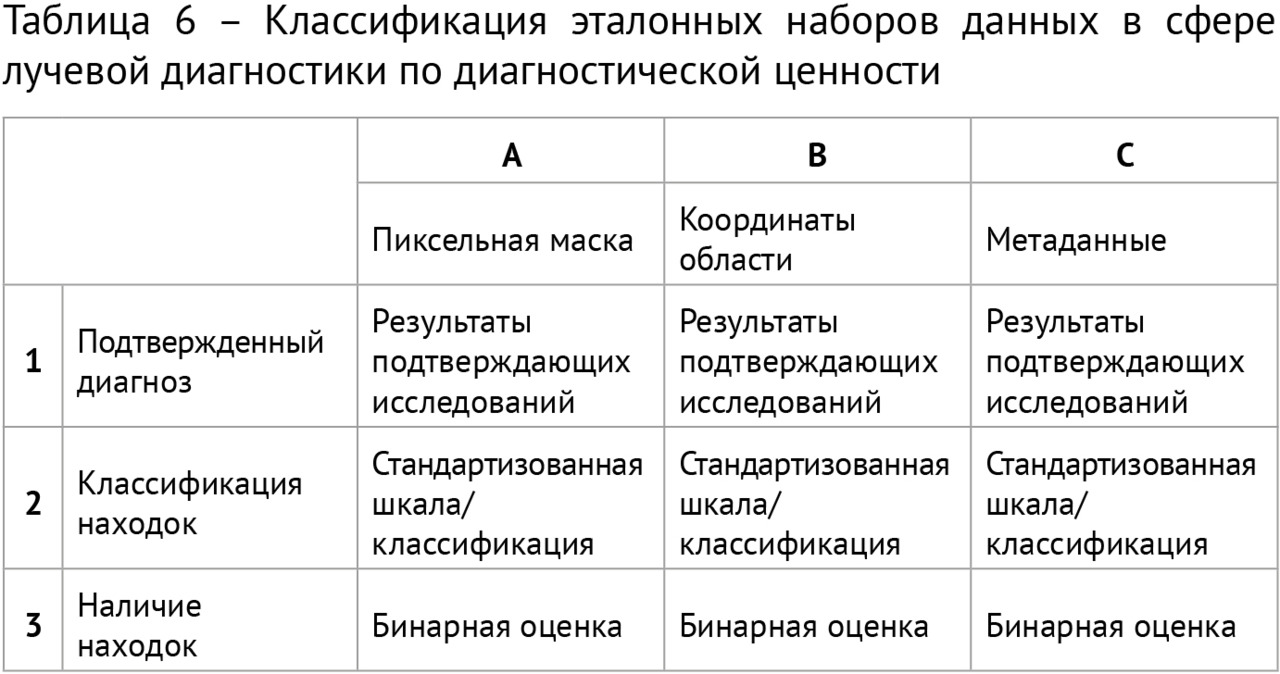
Классификация предполагает разделение наборов на три вида (1, 2, 3) и три класса (A, B, C).
Вид подразумевает типовой способ верификации:
1. Бинарная оценка факта наличия или отсутствия целевой патологической находки.
2. Классификация целевой патологической находки в соответствии со стандартизованными клинико-рентгенологическими классификациями, шкалами, системами.
3. Наличие данных о верификации природы целевой патологической находки.
Класс подразумевает типовой способ отображения патологической находки в результатах лучевого исследования:
1. Информация о наличии/отсутствии целевой патологической находке содержится в метаданных (то есть в аннотации — сопроводительных файлах), отсутствует на изображении.
2. Информация об имеющейся целевой патологической находке представлена в виде координат. Может помещаться в метаданные (аннотация, сводный табличный сопроводительный файл) и/или присутствовать на изображении в виде отметки области расположения простой геометрической фигурой.
3. Информация об имеющейся целевой патологической находке представлена на изображении в виде пиксельной маски (оконтуренной области изображения), дополнительно может содержаться в метаданных (в аннотации).
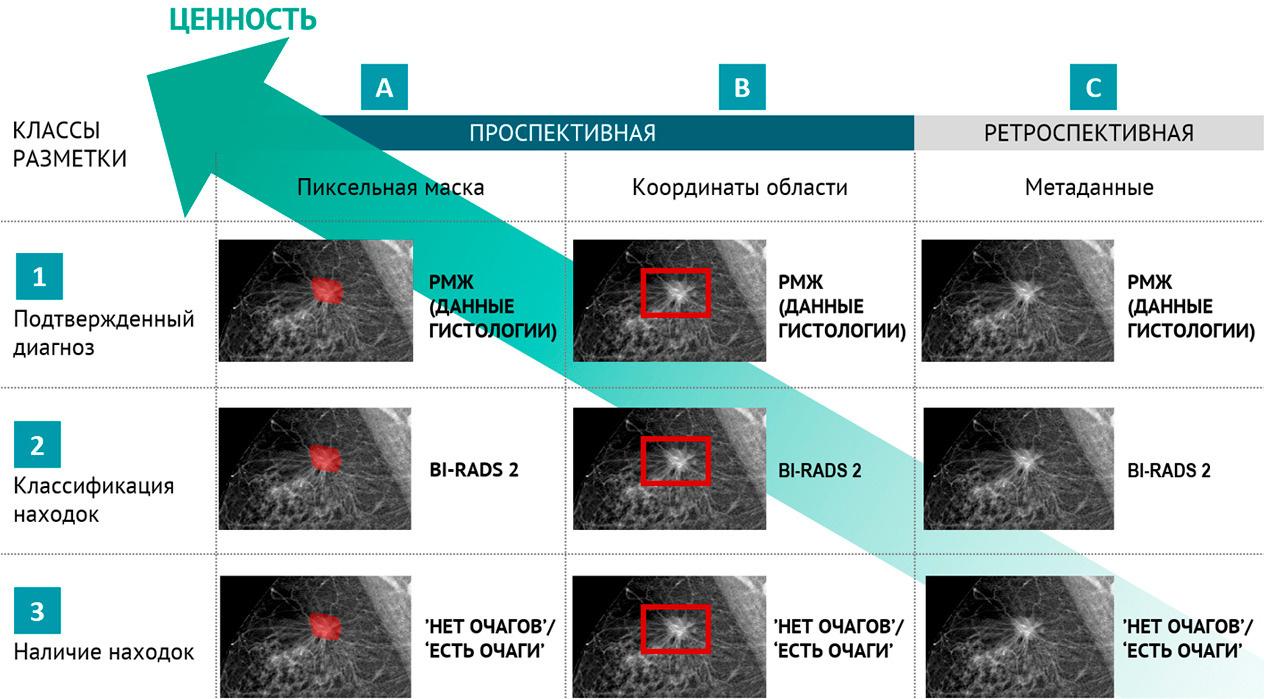
Классификация может применяться в отношении наборов данных для любых клинических задач в сфере лучевой диагностики. Она не зависит от типов (модальности) диагностических данных, но вместе с тем четко отображает взаимосвязь между собой: а) объемов и качества исходных данных; б) трудозатрат на подготовку; в) методик разметки и работы с первичными данными; г) диагностической ценности. На рис. 9 приведен пример использования классификации в отношении наборов данных для обучения алгоритмов ИИ в целях скрининга злокачественных новообразований молочной железы.
В соответствии с классификацией минимальный вариант набора (С3) данных представляет собой результаты цифровой маммографии с информацией «Есть очаги» / «Нет очагов» в дополнительном файле (электронной таблице). Максимальный вариант (А1) — это результаты цифровой маммографии, на которых пиксельной маской отмечены патологические очаги, а в дополнительных файлах содержатся результаты патогистологического исследования материала, полученного при биопсии или хирургическом вмешательстве. Очевидно, что с учетом трудозатрат вариант С3 можно подготовить простой выгрузкой данных из медицинской информационной системы (т.н. ретроспективная разметка — подробнее об этом будет сказано далее). Однако этот же вариант наименее ценен с диагностической точки зрения; объяснимость решений алгоритма ИИ, разработанного на его основе, будет сомнительной. Вариант А1 требует длительного сбора данных, скорее всего из различных источников, информационных систем; также необходима непосредственная работа квалифицированных врачей-рентгенологов по нанесению пиксельной маски на изображения согласно определенной методике. Впрочем, именно вариант А1 позволит алгоритму не просто научиться отличать норму от болезни, но четко указывать локализацию и тип патологической находки (вплоть до отделения потенциально злокачественных находок от потенциально доброкачественных). «Золотая середина» для клинической задачи скрининга — это набор данных В2. В таком случае на изображении выделены области расположения патологических очагов, а само исследование классифицировано по стандартизированному инструменту BI-RADS. Следовательно, алгоритм ИИ сможет не просто выбрать исследования с патологией, но сразу сформировать предложения по дальнейшей маршрутизации пациентки.
Вторая классификация наборов данных — по функциональному назначению (таблица 7).
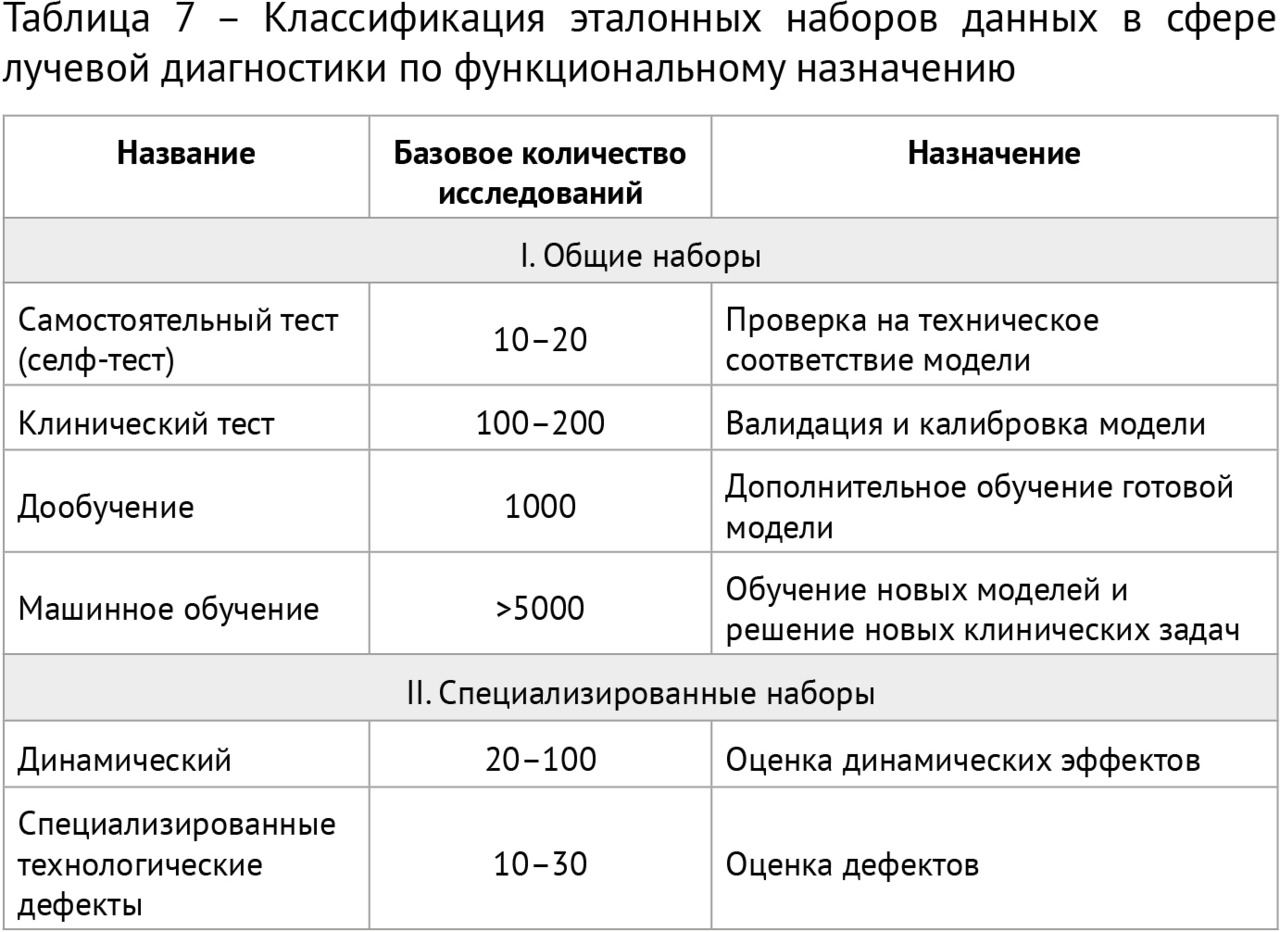
Медицинские данные подразделяются на несколько подмножеств, каждое из которых является важным компонентом в обучении, оценке качества алгоритмов ИИ и используется для других прикладных и фундаментальных задач в сфере искусственного интеллекта для здравоохранения. Каждый компонент (подмножество, набор) данных направлен на решение определенной задачи.
Обе предложенные классификации успешно применяются для подготовки эталонных наборов данных в службе лучевой диагностики города Москвы.
§3. Методология формирования наборов данных
Общие принципы. Формирование наборов данных состоит из двух взаимосвязанных процессов подготовки и разметки (аннотирования) данных.
Подготовка данных — процесс выгрузки структурированных и неструктурированных данных из медицинских информационных систем по заданным критериям (фильтрам).
Разметка (аннотация) данных — обработка структурированных и неструктурированных данных, формируемых ретро- или проспективно, в процессе которой данным (в том числе диагностическим изображениям) присваиваются идентификаторы, отражающие тип данных (классификация данных), и/или вносится информация об интерпретации данных для решения конкретной клинической задачи.
Следовательно, разметка — это процесс определения значения признаков или характеристик у элемента данных в наборе. В лучевой диагностике обычно таким «элементом» является диагностическое изображение, одно или в виде серии. На основе разметки становится возможным провести классификацию элементов, отнести их к той или иной группе. А под словами «определение значения» чаще всего понимают кластеризацию и классификацию исследований по группам (наличие или отсутствие рентгенологических признаков выбранного заболевания — целевой патологии), а также графическое обозначение области интереса, соответствующей искомым признакам (например, очаги демиелинизации при рассеянном склерозе на МР-изображениях головного мозга).
Для разметки может использоваться как уже имеющаяся на момент отбора исходных данных информация (ретроспективная подготовка данных), так и разметка, сделанная специалистом уже после этапа отбора (проспективная подготовка данных). Таким образом, подготовка наборов данных может производиться ретроспективно или проспективно.
Ретроспективная подготовка — это сбор элементов (результатов лучевых исследований) в соответствии с указанными метаданными, перечень которых выбирают в соответствии с поставленной клинической задачей. Ретроспективная подготовка обеспечивает формирование наборов данных класса С. Такую подготовку проводят путем выгрузки данных из медицинской информационной системы по предустановленным фильтрам. Этот подход не предполагает какой-либо обработки элементов, то есть аннотирования, анализа, нанесения меток и проч. на диагностические изображения. Для каждого элемента набора данных устанавливают его соответствие медицинской информации (протоколу описания, диагнозу согласно принятой классификации, результатам лабораторных, инструментальных или иных лучевых исследований и т.п.). Эта подготовка не требует участия врача, а может быть выполнена техническим специалистом, который имеет опыт работы с наборами данных.
Пример ретроспективной подготовки: набор данных — результаты лучевых исследований пациентов с подтвержденной коронавирусной болезнью. Перечень метаданных в таком случае будет следующим: идентификационный номер, дата рождения, дата выполнения лучевого исследования, результаты иммунологических исследований и т. п. Значит, при ретроспективной подготовке суть разметки состоит в соотнесении результатов лучевого исследования с некими данными из медицинской документации пациента без критического или экспертного анализа такого соответствия. В этом процессе могут быть использованы данные сопроводительных документов (например, тексты заключений для результатов инструментальных исследований), медицинских информационных систем, электронных медицинских карт, а также метаданные, генерируемые автоматически диагностическим устройством при проведении исследования и хранящиеся в исходных данных. Очевидное преимущество ретроспективного подхода заключается в значительно меньших временных затратах со стороны врачей, так как большую часть работы выполняет специалист по работе с данными.
Проспективная подготовка — это сбор элементов (результатов лучевых исследований) в соответствии с поставленной клинической задачей, а также проведение дополнительных манипуляций с элементами, то есть разметки, аннотирования. Проспективная подготовка обеспечивает формирование наборов данных классов А и В.
Пример разметки — непосредственно на изображение наносятся метки, аннотирования — определяются координаты и морфометрические характеристики объектов. Проспективная подготовка предполагает активное вовлечение обученного медицинского персонала в процесс аннотирования содержания данных или их частей набора. Этот процесс может происходить в графической или текстовой формах либо в их комбинации. Фактически он означает «насыщение» набора данных дополнительной информацией, позволяющей разделить его элементы на категории. Степень вовлечения медицинского персонала может быть более или менее затратной: в первом случае экспертам предлагается обвести контур области интереса, во втором — обозначить ее координаты простой геометрической фигурой.
Обязательный подготовительный этап перед проспективной подготовкой — выбор конкретной методики разметки (аннотирования), определение объемов, критериев, программного обеспечения для этой работы, подготовка инструкций для врачей-разметчиков, формирование и обучение команды. В процесс подготовки такой инструкции, по возможности, должна быть вовлечена та рабочая группа, которая определяла клиническую задачу на этапе планирования. Надо подчеркнуть, что в зависимости от клинической задачи и технических условий в одном наборе могут комбинироваться данные, подготовленные ретро- и проспективно.
Как видим, набор данных содержит результаты диагностических исследований, при этом наличие целевой патологии определяется извлечением информации из сопутствующей медицинской документации и/или интерпретацией изображений врачом-рентгенологом, осуществляющим разметку. В целом такую разметку можно назвать экспертной. Набор данных может быть дополнен информацией не только о наличии целевой патологии, но и об объективном подтверждении этого факта, то есть о верификации первичной диагностической гипотезы. Соответственно, такой набор называют верифицированным.
Верифицированный набор данных — это эталонный набор данных для обучения или тестирования алгоритмов искусственного интеллекта, подготовленный проспективно и содержащий данные из медицинской документации об окончательном и/или патологоанатомическом диагнозе.
Верификация осуществляется путем внесения в набор данных результатов (в порядке убывания диагностической ценности):
— патологоанатомических, патогистологических и цитологических исследований;
— лабораторных исследований (прежде всего, молекулярно-биологических, серологических, иммунологических);
— иных инструментальных исследований (например, эндоскопических);
— результатов динамического наблюдения (повторных исследований аналогичной модальности, выполненных через установленный интервал времени);
— открытого консенсуса не менее 3-х врачей-экспертов по каждому отдельному случаю;
— слепого анализа набора данных несколькими экспертами с достижением заданного уровня согласованности их решений.
Условно выражаясь, верификация обеспечивает степень «доверия» набору данных со стороны разработчиков или специалистов по оценке работы интеллектуальных систем.
В тех случаях, когда экспертное мнение является наиболее весомым фактором при определении значений признаков или характеристик данных, разумным решением будет проведение одновременного чтения исследования двумя независимыми экспертами. В случае несогласованности между двумя экспертами спорные исследования направляются третьему, более квалифицированному эксперту (по практическому опыту, наличию степени либо другим критериям). Исследования, оставшиеся спорными после трех экспертов, могут быть признаны «некачественными» и исключены из набора данных.
Оптимальный и наиболее ценный вариант — это верификация диагноза патологоанатомическими, клеточными и лабораторными методами. Консенсус и слепой анализ, как правило, приводят к исключению значительного количества выгруженных элементов (результатов исследований) из окончательного набора. По собственному опыту авторов до 25,0% исследований могут оказаться спорными после двух независимых чтений; до 4% могут остаться таковыми даже после чтения третьим, более квалифицированным экспертом (медицинский стаж которого более 5 лет).
Организация работы и контроль качества. Формирование набора данных должно быть тщательно спланировано, обеспечено ресурсами и эффективным управлением. Обязателен мониторинг процессов подготовки и разметки (аннотирования) для непрерывного улучшения качества.
Врачей-разметчиков рационально объединять в группы. В группу должны входить специалисты с достаточным опытом интерпретации и описаний результатов определенного вида исследования (обычно — от трех лет и выше); идеальный вариант — это наличие субспециализации. Группой должен руководить модератор, который не принимает непосредственного участия в разметке, но распределяет и регулирует срочность, очередность и объем работы между разметчиками. Также ключевая задача модератора — это контроль качества, в частности:
— проверка соблюдения требований к набору данных в соответствии с поставленной задачей и характеристиками эталонного набора;
— проверка отсутствия пропусков элементов в наборе данных;
— проверка отсутствия некорректных элементов для решения поставленных задач;
— проверка качества элементов и манипуляций с ними (разметки, аннотирования) в соответствии с установленными критериями.
Подготовка и разметка данных в лучевой диагностике. В лучевой диагностике стандартный набор данных состоит из диагностических изображений в формате DICOM, отобранных в соответствии с клинической задачей. Диагностическое изображение, включенное в набор, может содержать информацию о целевой патологической находке и иные сведения в метаданных или в сопроводительном файле — аннотации. Существуют такие виды аннотаций:
1. Полуструктурированное текстовое описание визуальных наблюдений с указанием содержащих их анатомических объектов и типов нарушений.
2. Структурированное описание с использованием стандартизированной терминологии (тезауруса).
3. Сводный табличный файл для всех изображений, включенных в набор, с координатами (x, y, z) и морфометрическими данными целевых патологических находок.
Конкретная информация о локализации целевых патологических находок может быть представлена с разным уровнем точности и детализации:
— приблизительное обозначение координат посредством задания ограничивающего параллелепипеда, эллипсоида или иной простой геометрической фигуры либо их сочетания;
— полная сегментация на основе маски минимальных элементов, обозначающей положение целевой патологической находки на фоне остальной части изображения.
Пример. Методика разметки результатов компьютерной томографии органов грудной клетки для клинической задачи: скрининг злокачественных новообразований легкого путем выявления очагов более 5 мм в диаметре.
1. Действия врача:
1.1. Просматривает срезы в аксиальной, фронтальной и сагиттальной проекциях (допустимо использование режима Maximum intensity projection для более четкого различения очагов на фоне кровеносных сосудов).
1.2. В случае выявления очага на одной из проекций отмечает при помощи мыши сферу, ограничивающую все пораженные ткани.
2. Важные функциональные требования к программному обеспечению:
— нанесенная сфера должна синхронно отображаться на всех трех проекциях;
— должна быть возможность нанести метку на одной проекции, а затем внести в нее изменения (расширить или переместить) на другой;
— для каждого обнаруженного и отмеченного очага автоматически формируются пространственные координаты сферы и ее диаметр.
Примечание. В методике используется научно обоснованная кластерная модель определения локализации очаговых образований. Для выбора оптимальной геометрической фигуры был проведен численный эксперимент, в котором установлено соотношение между точностью и скоростью разметки при аппроксимации различными фигурами. Доказано, что разметка сферами обладает наименьшей сложностью и лишь ненамного уступает по точности разметке эллипсоидами. Для очагов простой формы (как правило, близкой к сферической) достаточно указать координаты центра очага и диаметр сферы, охватывающей весь очаг и часть прилегающих к нему здоровых тканей. Для объектов сложной формы (вытянутых вдоль какого-то направления или состоящих из конгломерата сферических очагов) формируется так называемый кластер.
Кластер — это покрытие очага несколькими сферами, каждая из которых захватывает какую-то часть данного объекта. Эти сферы, пересекаясь друг с другом, фиксируют локализацию всей опухоли. Пересекающиеся между собой сферы, объединенные в кластер, считаются относящимися к одному образованию. Условием отнесения группы сфер к одному кластеру является расстояние между центрами, не превышающее диаметра сферы. Фактически кластер является массивом записей о сферических отметках, допускающим несколько вариантов представления.
3. Действия врача:
3.1. Вводит параметры обнаруженного и отмеченного очага:
А. Обозначение типа текстуры очага:
— сóлидный (очаг типичной структуры локального уплотнения округлой формы мягкотканой плотности с различными контурами);
— полусóлидный (очаг имеет более плотный участок в центре и зоны низкой плотности по типу «матового стекла» по периферии);
— по типу «матового стекла» (очаг характеризуется незначительным повышением плотности легочной ткани, с сохранением видимости сосудов и бронхов в зоне патологического процесса).
В. Злокачественность очага:
— «да»,
— «нет» (для фиброзных уплотнений, кист и прочих доброкачественных образований).
4. Действия эксперта:
— просматривает ранее сделанные врачом-разметчиком отметки и отвечает на стандартные вопросы по каждой из них (три варианта ответа: «Согласен с отметкой», «Согласен частично», «Не согласен»);
— при выборе «Согласен частично» в поле описания добавляет информацию о причинах разногласий.
§4. Процесс создания наборов данных
На рис. 10 изображена схема жизненного цикла набора данных от независимых друг от друга исследований до конечного продукта.
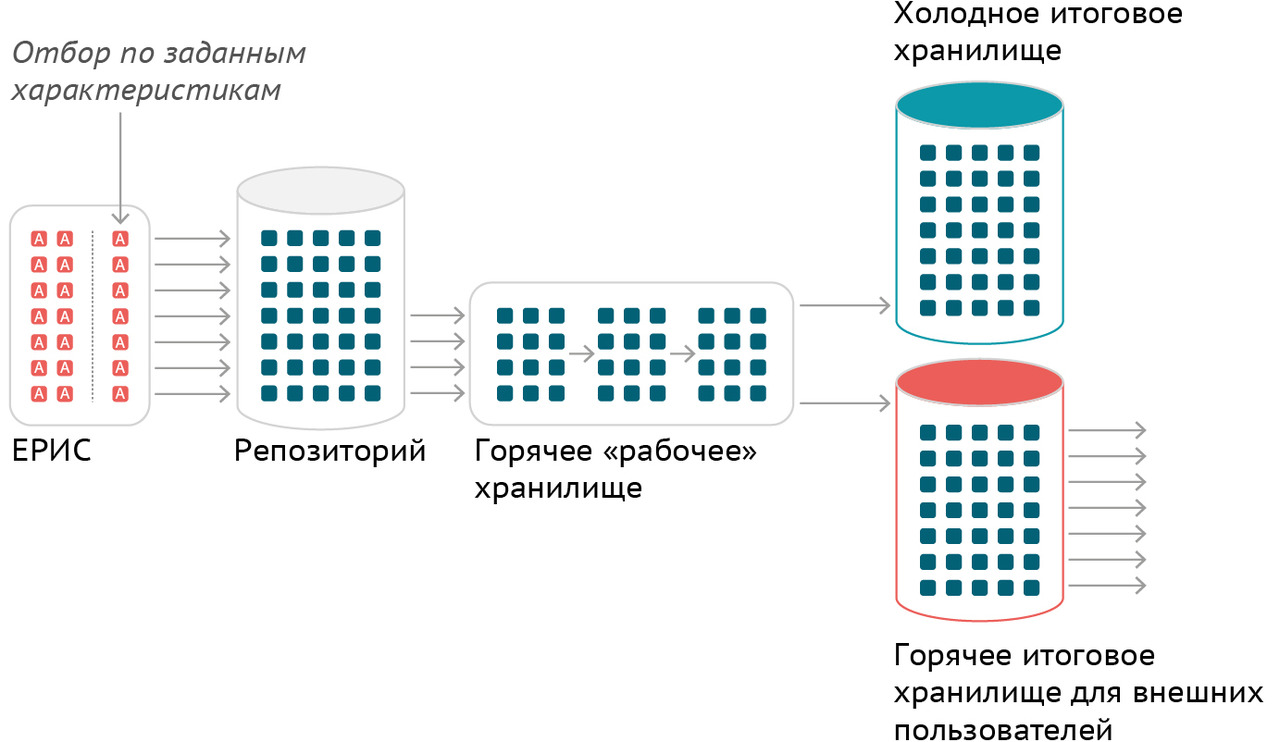
Процесс подготовки набора данных состоит из 5 основных этапов:
— планирование;
— документирование;
— сбор данных;
— разметка и верификация;
— хранение и предоставление доступа.
Каждый этап, в свою очередь, состоит из совокупности процедур, выполнение которых позволяет получить качественный набор данных и в конечном итоге достигнуть цели обучения и тестирования алгоритма искусственного интеллекта.
I этап. Планирование. Основные процедуры этапа:
1. Постановка клинической задачи в сфере лучевой диагностики, которая потенциально решается путем автоматизации с помощью интеллектуальных систем. Составление перечня признаков и/или характеристик исходных данных, информацию о которых планируется получать от интеллектуальной системы в процессе решения поставленной задачи и по которым возможно оценить корректность принятого системой решения, то есть формирование требований к результатам работы технологий искусственного интеллекта по решению данной клинической задачи.
2. Определение цели применения набора данных: обучение, выполнение тестирования на этапе разработки или выполнение валидации (клинических испытаний) алгоритмов ИИ.
3. Оценка необходимости получения одобрения Комитета по биоэтике для сбора данных или использования деидентифицированных данных с целью подготовки набора данных. При выявленной необходимости — получение такого одобрения.
4. Выбор вида подготовки (ретроспективный или проспективный), методов разметки (аннотации), способа верификации значений выбранных признаков и/или характеристик у элементов формируемого набора данных.
5. Определение источников данных, критериев включения, невключения и исключения данных из набора. Определение значимых характеристик данных, необходимых для оценки не только точности, но и пределов надежности и масштабируемости интеллектуальной системы.
Постановка клинической задачи — одна из наиболее ответственных задач, стоящих перед создателем набора данных. Недостаточное внимание к ней приводит к внезапно всплывающим вопросам как в процессе подготовки набора данных, так и уже при внедрении диагностического алгоритма на основе ИИ в клиническую практику. В постановке задачи должна участвовать рабочая группа из профессионалов различных профилей: врачей-клиницистов, организаторов здравоохранения, специалистов по обработке медицинских данных, инженеров-исследователей (занимающихся машинным обучением или проводящих валидацию решений на основе ИИ), а также администраторов, обеспечивающих доступ и выгрузку исходных данных. В таком случае может быть поставлена задача, имеющая клиническое, организационно-управленческое и социально-экономическое значение для практического здравоохранения, а также потенциально качественно решаемая именно интеллектуальными технологиями.
Клиническая задача должна позволить создателям набора данных ответить на следующие вопросы:
— Какие модальности, какие процедуры, какую клиническую, демографическую и подобного рода информацию следует принимать на вход алгоритму для ее решения, и что принимать за одну единицу данных?
— Какие признаки должны определяться с помощью технологий ИИ?
— Каким нозологиям или группам нозологий относятся искомые признаки?
— Как решение задачи помогает клиническому специалисту?
— Какое количество единиц данных необходимо и достаточно для цели применения создаваемого набора данных?
Из клинической задачи логическим образом вытекают критерии, по которым интеллектуальная система принимает решение, отнести ли то или иное исследование или найденную на изображении область к группе интереса. Речь идет о так называемых базовых диагностических требованиях к работе ИИ. Они включают формальное описание искомых признаков на исследовании, а также составляют перечень признаков и/или характеристик, на основе которых в дальнейшем будет проводиться разметка данных в наборе. Эта информация позволяет разработчикам точнее настроить решения для определения требуемых признаков, а специалистам по подготовке набора — составить инструкцию по разметке и верификации данных.
Критерии включения и невключения чаще определяются клинической и/или практической задачей, тогда как критерии исключения обычно дополняются в ходе работы с первичными данными, так как находятся те или иные критерии, негативно сказывающиеся на структурированности и унификации набора данных. Критерии могут носить как медицинский (например, возраст — от 18 до 99 лет, наличие сохранной структуры искомого органа и т. д.), так и технический характер (фильтр КТ — мягкотканный, ядро свертки — FC51 и т. д.). Унификация данных необходима для надежной работы инструментов оценки работы решения на основе ИИ.
Существуют два основных принципа отбора данных для формирования набора:
а) включение медицинских данных (патологических находок, заболеваний, состояний, артефактов, нормальной картины), отражающее максимальную вариативность, то есть и частые, и редкие случаи представлены в одинаковом объеме;
б) представление медицинских данных согласно их частоте встречаемости, претестовой вероятности, заболеваемости, распространенности в популяции.
II этап. Сбор данных. Основные процедуры этапа:
1. Получение доступа к источнику данных.
2. Отбор исходных (первичных, «сырых») данных.
3. Перенос данных в информационную систему для разметки (аннотирования), документирования набора данных.
Медицинская организация, участвующая и/или выполняющая подготовку набора, должна обеспечить доступ к необходимым данным в медицинской информационной системе. Кроме того, нужно обеспечить выполнение операций поиска, чтения, сбора и выгрузки данных, а в идеальной ситуации — еще и обезличивания данных средствами самой медицинской информационной системы. Процесс доступа следует оптимально изложить в виде документа (регламента, соглашения и проч.), прежде всего для обеспечения защиты данных, в том числе персональной информации согласно действующему законодательству.
Подход к получению (выгрузке) исходных данных зависит от источника и способа хранения данных. Общие принципы отбора первичных данных:
— выбор как можно большего спектра исследований интересующей модальности и процедуры;
— сохранение необходимого для решения клинической задачи количества сопроводительной информации (включая текстовые документы, описывающие результаты исследования, клинический диагноз пациента, которым закончился медицинский случай, и др.);
— обезличивание исследований в информационном контуре медицинской организации (медицинской информационной системе), в которой происходит отбор данных.
На этапе отбора применяются также критерии включения и невключения исследования в будущий набор. Эта операция может проводиться как непосредственно при отборе исследований в медицинскую информационную систему (МИС), так и сразу после выгрузки (уже вне пределов информационного контура медицинской организации). Необходимо учитывать, что этот шаг может повлечь за собой уменьшение набора данных в несколько десятков раз.
Набор данных для обучения или тестирования алгоритмов ИИ не должен содержать какую-либо персональную информацию. В соответствии с действующим законодательством любая персональная информация должна быть удалена из исходных данных и метаданных. Стандартно проводится удаление номера полиса обязательного медицинского страхования застрахованного лица, наименования МО, фамилии, имени, отчества пациента, места проживания, даты исследования; иные идентификаторы, посредством которых потенциально можно установить личность пациента; проводится автоматическая замена сведений о дате рождения на точный возраст (годы, месяцы) на момент исследования.
Важно подчеркнуть, что в информированном добровольном согласии пациента, которое оформляется для проведения исследования, должно быть и согласие на обработку персональных данных, включая обезличивание.
Деидентификация метаданных изображений проводится в стандарте DICOM (E Attribute Confidentiality Profiles) в соответствии с ГОСТ Р ИСО 17432–2009.
III этап. Разметка и верификация. Основные процедуры этапа:
1. Формирование задания на разметку, обеспечение наличия команды разметчиков, требуемых методических материалов и программного обеспечения.
2. Проведение разметки (аннотирования).
3. Внесение данных о верификации.
Подробно перечисленные процедуры были описаны выше.
В целях эффективной разметки наборов данных в лучевой диагностике необходимо программное обеспечение, позволяющее «насытить» исходные медицинские данные дополнительной полезной информацией, полученной в ходе работы медицинских специалистов. Такое программное обеспечение должно соответствовать определенным критериям. Далее представлен список необходимых и желательных функциональных критериев для программного продукта, используемого для создания размеченных наборов данных.
1. Критерии пользователей:
а. Разметка с использованием изображений нескольких серий, модальностей.
б. Возможность оставлять комментарии при разметке, которые направляются от пользователя к модератору разметки и наоборот.
в. Отображение изображений в трех ортогональных плоскостях с указанием локализации отображаемого слоя.
г. Изменение фона во время разметки по выбору пользователя (однородный черный/серый/белый).
д. Возможность указания на клинический случай, который сложен для интерпретации врачом.
е. Указание времени, которое тратится на среднюю разметку одного кейса пользователем.
ж. Возможность пропустить представленный кейс.
2. Критерии разработчиков методологии разметки:
а. Поддержка совместимости с разными типами входных данных и данных, содержащих результаты разметки.
б. Создание собственных дополнительных модулей.
в. Возможность подключения Clara Nvidia segmentation models (ML based) или других решений для помощи в разметке.
г. Программирование автоматического выполнения отдельных шагов пользователя.
д. Модификация пользовательского интерфейса под текущую задачу.
3. Требования к ИТ-реализации:
а. Автосохранение в процессе работы — обязательно.
б. Возможность подключения к PACS — обязательно.
в. Не требователен к ресурсам компьютера (графический процессор) при визуализации (обязательное требование для desktop-продуктов).
г. Open-source — желательно.
д. Веб-интерфейс — обязательно.
IV этап. Документирование. Основные процедуры этапа:
1. Оформление сопроводительной документации (в том числе в соответствии с рекомендованной базовой структурой readme-файла).
2. Внесение информации о наборе данных во внутренний учетный реестр организации, проводящей его формирование.
3. Государственная регистрация набора в качестве базы данных (результата интеллектуальной деятельности) в соответствии с действующим законодательством.
В процессе подготовки набора данных неизбежно упускаются те или иные критерии, всплывающие при непосредственной работе с набором конечными пользователями. Внесение нужных корректировок должно быть прозрачным для всех участников процесса и пользователей. Ведение версионирования набора данных позволяет отслеживать подобные изменения.
Нами предложен следующий оригинальный подход как вариация семантического версионирования:
1. Мажорная версия (Major) — увеличивается при изменении значимых параметров набора данных, связанных с клинической задачей, целью, принципами разметки и верификации данных.
2. Минорная версия (Minor) — увеличивается при замене, добавлении или удалении единиц данных в наборе без изменения других значимых его параметров; при этом алгоритмы обучения или валидации могут использовать новую минорную версию без изменения кода. При выпуске новой мажорной версии минорная версия устанавливается равной 0.
3. Патч-версия (Patch) — увеличивается при внесении корректировок в сопроводительную документацию, исправлении опечаток и иных ошибок в файлах разметки; при этом не меняется количество и качество единиц данных в наборе. При выпуске новой мажорной и/или минорной версии патч-версия устанавливается равной 0.
В целях удобства использования набора данных в корневую директорию помещается файл с названием README.md в формате Markdown и сгенерированный на его основе README. pdf в формате Adobe PDF. Единый подход к структуре README файла (рис. 11) позволяет организовать удобный поиск и фильтрацию по всем опубликованным наборам.
С точки зрения удобства ведения отчетности, практическую ценность имеет единый реестр подготовленных наборов данных. Минимальный набор рекомендуемых полей реестра:
1. Порядковый номер записи в реестре.
2. Внутренний код, уникальный для набора данных в текущем реестре и/или учреждении.
3. Назначение набора данных, область применения.
4. Модальность/процедура (характеристики исследований, пригодные для их поиска и выбора в МИС).
5. Искомые признаки и/или целевая патология (при возможности — с указанием кода Международной классификации болезней).
6. Определение единицы данных.
7. Количество единиц данных (при возможности — с указанием выходного объема данных в Мб, Гб или Тб).
8. Классы разметки с указанием количества записей в каждом классе.
V этап. Хранение и предоставление доступа. Основные процедуры этапа:
1. Передача готового к использованию набора данных в локальное или внешнее хранилище-репозиторий (публикация набора данных).
2. Организация доступа к набору данных авторизованных пользователей.
3. Применение набора данных.
Завершающим этапом процесса подготовки набора данных является его публикация. Этот этап включает в себя формирование структурированного набора файлов и директорий, помещенного в отдельное подразделение файлового хранилища, имеющего доступ к сети «Интернет». Возможность передачи опубликованных наборов третьим лицам, а также получать наборы, сформированные третьими лицами, появляется после подписания соглашения о передаче данных в двустороннем порядке. Соглашение регламентирует цели, задачи, порядок, сроки и условия передачи данных, а также ответственности сторон за нарушение условий соглашения.
Публикация набора данных представляет собой организацию доступа пользователей к его первой мажорной версии (1.0.0), обязательно снабженной сопроводительной документацией.
Хранение набора данных может быть организовано на локальном сервере или с использованием облачного хранения (ГОСТ Р ИСО/МЭК 17826–2015). В первом случае обеспечивается более высокий уровень доступности и безопасности, а во втором — становятся возможными совместное использование данных и более надежное резервное копирование. Доступ пользователей к набору данных проводится в соответствии с установленными стандартными процедурами (для разработчиков, исследователей, сотрудников, проводящих клинические испытания и т.д.). Вопросы публикации и использования наборов данных должны быть урегулированы с медицинской организацией, на базе которой формируется сам набор.
Организационно могут использоваться два репозитория:
1. Холодное итоговое хранилище. Используется для хранения готовых наборов данных, доступ к которым имеет ограниченный круг лиц по внутренней сети учреждения. Не требует большой скорости, поскольку нет больших и частых объемов работы с ним.
2. Горячее итоговое хранилище. Горячее хранилище выделено отдельно для опубликованных наборов данных, к которым необходимо обеспечить доступ для внешних пользователей согласно принятому регламенту. Скорость должна быть по возможности высокой и стабильной для пользователей.
Авторский пример хранения наборов данных представлен на рис. 12.
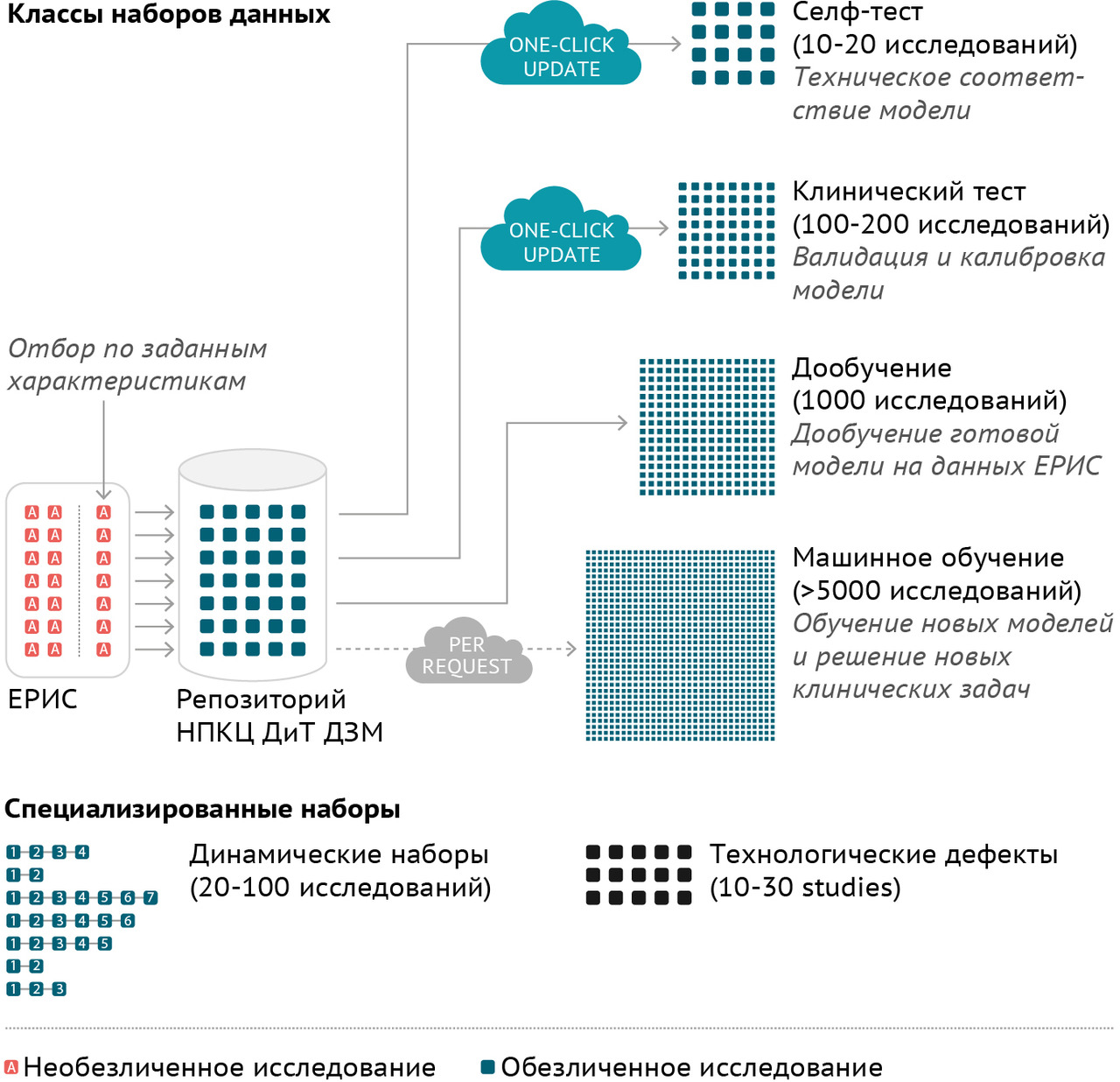
К публикации допускаются наборы данных, соответствующие следующим условиям:
1. Набору данных присвоен внутренний код. Для составления внутреннего кода допустимо использование латинских букв, цифр и нижних подчеркиваний.
В качестве предложения сформулирован подход к названию набора данных (рис. 13), в соответствии с которым в наименование входят:
— классификация по диагностической ценности;
— общее количество исследований, вошедших в набор данных;
— область исследования;
— характеристика пациентов или изображения;
— клиническая задача;
— дополнительная информация о данных и/или разметке и/или верификации.

2. Набор данных внесен в общий реестр наборов учреждения, которое осуществляет их разработку. Общий реестр представляет из себя таблицу, где ведется отчетность по готовности набора: указывается название и основная информация по нему (модальность, количество исследований, статус регистрации, анатомическая область, целевая задача, внутренний код, класс разметки, версионность, путь к набору и ответственные лица).
Бесплатный фрагмент закончился.
Купите книгу, чтобы продолжить чтение.