
Бесплатный фрагмент - Искусственный интеллект. С неба на землю

Предисловие
2023 год стал третьим и пока самым жарким летом искусственного интеллекта. Но что делать разработчикам и бизнесу? Стоит ли сокращать людей и полностью доверяться новой технологии? Или это все наносное, и нас ждет новая ИИ-зима? А как ИИ будет сочетаться с классическими инструментами и практиками менеджмента, управлением проектами, продуктами и бизнес-процессами? Неужели ИИ ломает все правила игры?
Мы погрузимся в эти вопросы, и в процессе размышлений и анализа различных факторов я постараюсь найти на них ответы.
Скажу сразу, здесь будет минимум технической информации. И даже более того, тут могут быть технические неточности. Но данная книга и не про то, какой тип нейросетей выбрать для решения той или иной задачи. Я предлагаю вам взгляд аналитика, управленца и предпринимателя на то, что происходит здесь и сейчас, чего ожидать глобально в ближайшем будущем и к чему готовиться.
Кому и чем может быть полезна эта книга?
— Собственникам и топ-менеджерам компаний.
Они поймут, что такое ИИ, как он работает, куда идут тренды, чего ожидать. То есть смогут избежать главной ошибки в цифровизации — искаженных ожиданий. А значит, смогут лидировать эти направления, минимизировать затраты, риски и сроки.
— ИТ-предпринимателям и основателям стартапов.
Они смогут понять, куда движется отрасль, какие ИТ-продукты и интеграции стоит разрабатывать, с чем придется столкнуться на практике.
— Техническим специалистам из ИТ.
Они смогут посмотреть на вопрос развития не только с технической точки зрения, но и экономической, управленческой. Поймут, почему до 90% ИИ-продуктов остаются невостребованными. Возможно, это поможет им в карьерном развитии.
— Обычным людям.
Они поймут, что их ждет в будущем и стоит ли бояться того, что ИИ их заменит. Спойлер — под угрозой оказались специалисты творческих специальностей.
Наше путешествие пройдет через 3 больших части.
— Сначала мы погрузимся и разберемся, что такое ИИ, с чего все начиналось, какие у него есть проблемы и возможности, какие тренды развиваются, и что нас ждет в будущем.
— Затем мы рассмотрим синергию ИИ с инструментами системного подхода. Как они влияют друг на друга, в каких сценариях ИИ будет применяться в ИТ-решениях.
— В конце мы пройдемся по практическим примерам и выведем рекомендации.
По любимой моей традиции в книге будут QR-коды (для печатной версии) и активные гиперссылки (для электронной версии) на полезные статьи и интересные материалы.
Что касается самого ИИ, то в написании книги он применялся для демонстрации его работы, и эти фрагменты выделены, а также для поиска идей. Уровня технологии пока недостаточно, чтобы брать материалы и вставлять в книгу. Также важно отметить, что мой основной язык — русский, поэтому все запросы к ИИ я буду делать на русском языке.
Завершить предисловие я хочу благодарностями людям, которые помогали мне:
— моей жене Алисе и сыну Валерию;
— моим родителям;
— моему коучу Евгению Бажову;
— моей команде, в особенности Александру Перемышлину;
— моим партнерам и клиентам, которые давали мне пищу для размышлений, в особенности Кириллу Неёлову;
— моим коллегам по проектам.
Часть 1. Введение в искусственный интеллект
Глава 1. Знакомство с ИИ
Что такое искусственный интеллект?
Начнем с того, что единого определения не существует. Давайте спросим у самого ИИ, а точнее у нескольких больших языковых моделей (LLM — large language model). Ниже несколько ответов с оригинальной орфографией.
GPT4: «Искусственный интеллект (ИИ) — это свойство искусственных интеллектуальных систем выполнять творческие функции, которые традиционно считаются прерогативой человека. Он связан с наукой и технологией создания интеллектуальных машин, особенно интеллектуальных компьютерных программ. Важно отметить, что ИИ не обязательно ограничивается биологически правдоподобными методами.
Существующие интеллектуальные системы имеют довольно узкие области применения. Например, программы, способные обыграть человека в шахматы, как правило, не могут отвечать на вопросы.
В общем плане, искусственный интеллект позволяет компьютерным системам имитировать когнитивные способности человека, такие как обучение и решение задач.
Это важное направление в современной информатике и науке о данных, и его применение охватывает множество областей, от финансов и медицины до развлечений и транспорта».
YandexGPT 2: «Искусственный интеллект (ИИ) — это комплекс методик компьютерных наук, математики, биологии и психологии, которые занимаются разработкой систем, способных выполнять задачи, обычно требующие человеческого интеллекта. Главная их задача — моделирование человеческого разума».
YandexGPT 3 Pro: «Искусственный интеллект (ИИ) — это свойство интеллектуальных систем выполнять творческие функции, традиционно считающиеся прерогативой человека. Это наука и технология создания интеллектуальных машин, особенно компьютерных программ, способных выполнять задачи, требующие человеческого интеллекта, например, решение сложных проблем, обучение на основе опыта, понимание естественного языка и способность адаптироваться к новым ситуациям. ИИ связан с использованием компьютеров для понимания человеческого интеллекта, но не ограничен биологически правдоподобными методами.»
GigaChat: «Искусственный интеллект (ИИ) — это свойство интеллектуальных систем выполнять творческие функции, которые традиционно считаются прерогативой человека. Это наука и технология создания интеллектуальных машин, особенно интеллектуальных компьютерных программ. Искусственный интеллект связан со сходной задачей использования компьютеров для понимания человеческого интеллекта, но не обязательно ограничивается биологически правдоподобными методами. Существующие на сегодня интеллектуальные системы имеют довольно узкие области применения. Искусственный интеллект был основан как академическая дисциплина в 1956 году и за прошедшие с тех пор десятилетия пережил несколько волн оптимизма».
Мне же, как человеку, ближе самое простое и понятное определение: ИИ — это любой математический метод, позволяющий имитировать человеческий или другой интеллект из естественной природы.
То есть ИИ — это огромное количество решений, в том числе и примитивные математические алгоритмы, и экспертные системы на базе правил.
И хотя данное направление родилось где-то в 50-х годах 20 века, нас в первую очередь интересует то, что мы понимаем под этим сегодня, в начале 2020-х. И тут есть три основных направления.
1. Нейросети — математические модели, созданные по подобию нейронных связей мозга живых существ. Собственно, мозг человека — это суперсложная нейросеть, ключевая особенность которой заключается в том, что наши нейроны не ограничиваются состояниями «включен / выключен», а имеют гораздо больше параметров, которые пока не получается оцифровать и применить в полной мере.
2. Машинное обучение (ML) — статистические методы, позволяющие компьютерам улучшить качество выполняемой задачи с накоплением опыта и в процессе дообучения. Это направление известно с 1980-х годов.
3. Глубокое обучение (DL) — это не только обучение машины с помощью человека, который говорит, что верно, а что нет (как мы часто воспитываем детей, это называется обучением с подкреплением), но и самообучение систем (обучение без подкрепления, без участия человека). Это одновременное использование различных методик обучения и анализа данных. Данное направление развивается с 2010-х годов и считается наиболее перспективным для решения творческих задач, и тех задач, где сам человек не понимает четких взаимосвязей. Но здесь мы вообще не можем предсказать, к каким выводам и результатам придет нейросеть. Манипулировать тут можно тем, какие данные мы «скармливаем» ИИ-модели на входе.
Как обучаются ИИ модели?
Сейчас большая часть ИИ-моделей обучается с подкреплением: человек задает входную информацию, нейросеть возвращает ответ, после чего человек ей сообщает, верно она ответила или нет. И так раз за разом.
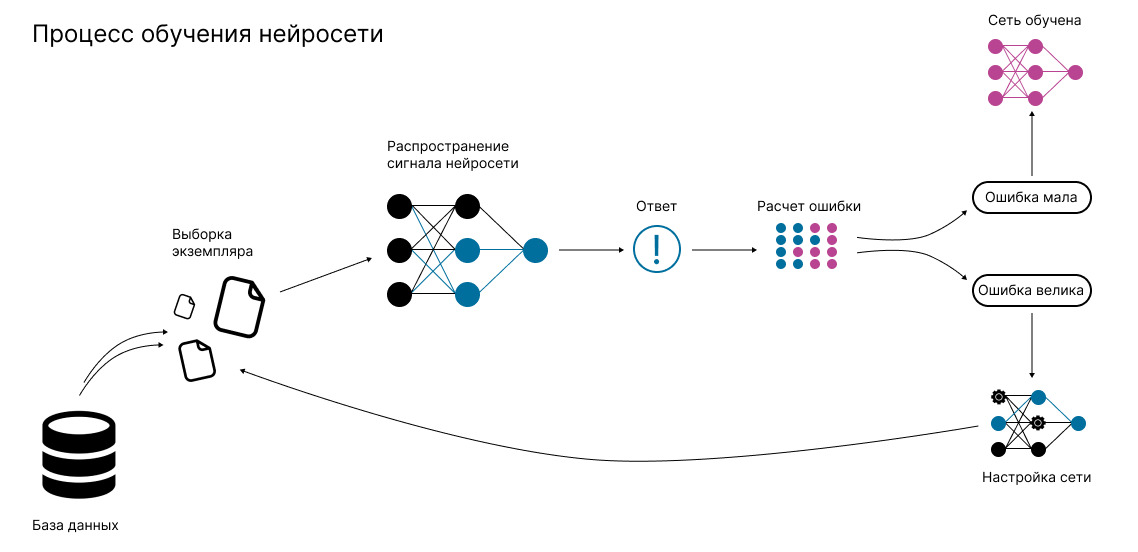
Подобным же образом работают и так называемые «Капчи» (CAPTCHA, Completely Automated Public Turing test to tell Computers and Humans Apart), то есть графические тесты безопасности на сайтах, вычисляющие, кем является пользователь: человеком или компьютером. Это когда вам, например, показывают разделенную на части картинку и просят указать те зоны, где изображены велосипеды. Или же просят ввести цифры или буквы, затейливым способом отображенные на сгенерированной картинке. Кроме основной задачи (тест Тьюринга), эти данные потом используются для обучения ИИ.
При этом существует и обучение без учителя, при котором система обучается без обратной связи со стороны человека. Это самые сложные проекты, но они позволяют решать и самые сложные, творческие задачи.
Общие недостатки текущих решений на основе ИИ
Фундаментально все решения на базе ИИ на текущем уровне развития имеют общие проблемы.
— Объем данных для обучения.
Нейросетям нужны огромные массивы качественных и размеченных данных для обучения. Если человек может научиться отличать собак от кошек на паре примеров, то ИИ нужны тысячи.
— Зависимость от качества данных.
Любые неточности в исходных данных сильно сказываются на конечном результате.
— Этическая составляющая.
Для ИИ нет этики. Только математика и выполнение задачи. В итоге возникают сложные этические проблемы. Например, кого сбить автопилоту в безвыходной ситуации: взрослого, ребёнка или пенсионера? Подобных споров бесчисленное множество. Для искусственного интеллекта нет ни добра, ни зла ровно так же, как и понятия «здравый смысл».
— Нейросети не могут оценить данные на реальность и логичность, а также склонны к генерации некачественного контента и ИИ-галюцинанций.
Нейросети просто собирают данные и не анализируют факты, их связанность. Они допускают большое количество ошибок, что приводит к двум проблемам.
Первая — деградация поисковиков. ИИ создал столько некачественного контента, что поисковые системы (Google и другие) начали деградировать. Просто из-за того, что некачественного контента стало больше, он доминирует. Особенно здесь помогают SEO-оптимизаторы сайтов, которые просто набрасывают популярные запросы для продвижения.
Вторая — деградация ИИ-моделей. Генеративные модели используют Интернет для «дообучения». В итоге люди, используя ИИ и не проверяя за ним, сами заполняют Интернет некачественным контентом. А ИИ начинает использовать его. В итоге получается замкнутый круг, который приводят ко все большим проблемам.
Также по QR-коду и гиперссылке доступна статья на эту тему.

Осознавая проблему генерации ИИ наибольшего количества дезинформационного контента, компания Google провела исследование на эту тему. Учеными было проанализировано около двухсот статей СМИ (с января 2023 года по март 2024 года) о случаях, когда искусственный интеллект использовали не по назначению. Согласно результатам, чаще всего ИИ используют для генерации ненастоящих изображений людей и ложных доказательств чего-либо.
— Качество «учителей».
Почти все нейросети обучают люди: формируют запросы и дают обратную связь. И здесь много ограничений: кто и чему учит, на каких данных, для чего?
— Готовность людей.
Нужно ожидать огромного сопротивления людей, чью работу заберут нейросети.
— Страх перед неизвестным.
Рано или поздно нейросети станут умнее нас. И люди боятся этого, а значит, будут тормозить развитие и накладывать многочисленные ограничения.
— Непредсказуемость.
Иногда все идет как задумано, а иногда (даже если нейросеть хорошо справляется со своей задачей) даже создатели изо всех сил пытаются понять, как же алгоритмы работают. Отсутствие предсказуемости делает чрезвычайно трудным устранение и исправление ошибок в алгоритмах работы нейросетей. Мы только учимся понимать то, что сами создали.
— Ограничение по виду деятельности.
Весь ИИ на середину 2024 года слабый (мы разберем этот термин в следующей главе). Сейчас алгоритмы ИИ хороши для выполнения целенаправленных задач, но плохо обобщают свои знания. В отличие от человека, ИИ, обученный играть в шахматы, не сможет играть в другую похожую игру, например, шашки. Кроме того, даже глубокое обучение плохо справляется с обработкой данных, которые отклоняются от его учебных примеров. Чтобы эффективно использовать тот же ChatGPT, необходимо изначально быть экспертом в отрасли и формулировать осознанный и четкий запрос.
— Затраты на создание и эксплуатацию.
Для создания нейросетей требуется много денег. Согласно отчёту Guosheng Securities, стоимость обучения относительно примитивной LLM GPT-3 составила около 1,4 миллиона долларов. Для GPT-4 суммы уже уходят в десятки миллионов долларов.
Если взять для примера именно ChatGPT3, то только для обработки всех запросов от пользователей нужно было больше 30000 графических процессоров NVIDIA A100. На электроэнергию уходило около 50000 долларов ежедневно. Требуются команда и ресурсы (деньги, оборудование) для обеспечения их «жизнедеятельности». Также необходимо учесть затраты на инженеров для сопровождения.
Опять же, это общие недостатки для всех ИИ решений. Дальше мы будем возвращаться к этой теме несколько раз и проговаривать эти недостатки в более прикладных примерах.
Глава 2. Слабый, сильный и суперсильный ИИ
Теперь про три понятия — слабый, сильный и суперсильный ИИ.
Слабый ИИ
Все что мы с вами наблюдаем сейчас — слабый ИИ (ANI, Narrow AI). Он может решать узкоспециализированные задачи, для которых изначально проектировался. Например, он может отличать собаку от кошки, играть в шахматы, анализировать видео и улучшать качество видео / звука, консультировать по предметной области и т. д. Но, например, самый сильный слабый ИИ для игры в шахматы абсолютно бесполезен для игры в шашки. А ИИ для консультирования по управлению проектами абсолютно бесполезен для планирования технического обслуживания оборудования.
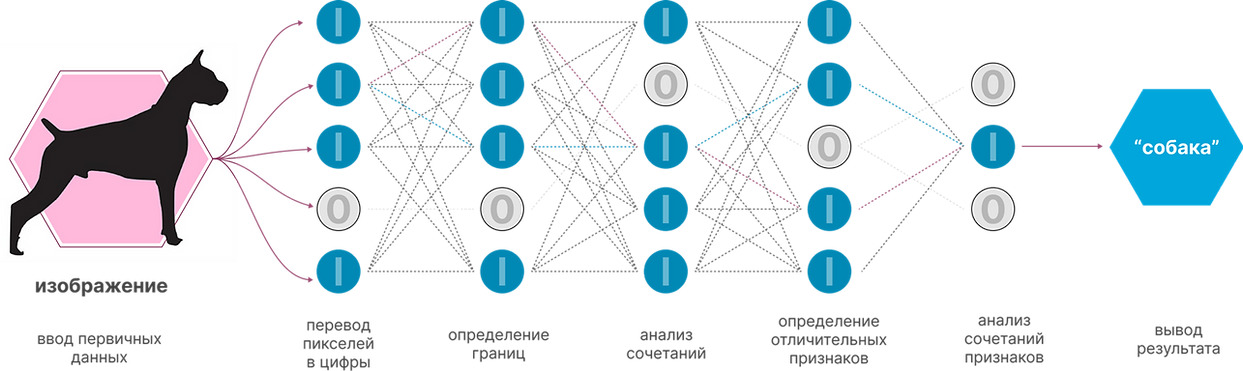
Сильный и суперсильный ИИ — что это такое?
Если с определением, что такое ИИ, все запутанно, то с термином «сильный ИИ» или «общий ИИ» все еще сложнее. Давайте для начала снова воспользуемся услугами LLM. Для этого я составил запрос: «Приведи расшифровку термина AGI и его краткое описание». Ниже приведу ответы нескольких LLM в оригинальной орфографии.
YandexGPT 2: «AGI (Artificial General Intelligence) — это искусственный интеллект общего назначения, способный решать разнообразные задачи, свойственные человеческому разуму. AGI обладает гибкостью и адаптивностью, свойственными человеческому мозгу, и может обучаться самостоятельно».
YandexGPT 3 Pro: «AGI (Artificial General Intelligence) — это концепция создания искусственного интеллекта, который будет способен решать широкий спектр задач на уровне человеческого интеллекта. Это следующий шаг в развитии искусственного интеллекта после узкоспециализированных систем, таких как системы распознавания речи или компьютерного зрения».
YandexGPT 4 Pro RC: «AGI (Artificial General Intelligence) — это искусственный общий интеллект, который представляет собой гипотетическую форму ИИ, способную понимать и решать задачи на том же уровне, что и человек. AGI может обучаться, адаптироваться и принимать решения в различных областях, таких как наука, искусство и социальные взаимодействия.
В отличие от специализированных систем ИИ, которые предназначены для выполнения конкретных задач, AGI стремится к универсальности и способности решать широкий спектр проблем. Однако создание AGI остаётся сложной задачей, требующей значительных исследований и разработок в области машинного обучения, нейронных сетей и других технологий.»
Giga Chat: «AGI (Artificial General Intelligence) — общий искусственный интеллект. Это концепция создания разумной машины, способной решать любые интеллектуальные задачи так же, как это делает человек, и возможно, лучше него».
ChatGPT4: «AGI означает Artificial General Intelligence (Автоматизированная Общая Интеллектуальность), которая является типом искусственного интеллекта, способным выполнять широкий спектр интеллектуальных задач на уровне человека или даже превосходить его. Это в отличие от узкоспециализированного ИИ, который создан для конкретных задач. Создание AGI является одной из основных целей исследований ИИ и компаний, таких как OpenAI. Время достижения AGI является предметом дискуссий среди исследователей и экспертов».
При этом исходный запрос довольно значительно влияет и на результат.
Также приведу несколько примеров связки вопрос-ответ к LLM YandexGPT 3 Pro.
Вопрос 1: «Привет. Что такое сильный ИИ или AGI».
Ответ 1: «Привет! Сильный ИИ, также известный как AGI (Artificial General Intelligence), представляет собой концепцию создания искусственного интеллекта, способного выполнять любые интеллектуальные задачи, доступные человеку, но не обязательно так же, как это делает человек. В отличие от слабого ИИ, который предназначен для выполнения конкретных задач, сильный ИИ стремится к имитации человеческого интеллекта в целом, включая аналитическое мышление и способность к обучению».
Вопрос 2: «AGI расшифровка».
Ответ 2: «AGI (Artificial General Intelligence) — это концепция создания искусственного интеллекта, который будет способен решать широкий спектр задач на уровне человеческого интеллекта».
Вопрос 3: «Приведи расшифровку термина AGI и его описание».
Ответ 3: «AGI (Artificial General Intelligence) — это сильный искусственный интеллект общего уровня, способный мыслить и действовать как человек. Он может делать самостоятельные выводы, обучаться и, возможно, осознавать себя в какой-то момент времени. В отличие от узких ИИ (Narrow AI), AGI представляет собой весь мозг, способный решать комплекс задач».
Как видите, от запроса зависит очень многое. И это одно из ключевых ограничений генеративного ИИ (ГИИ), но об этом поговорим в следующей главе.
Теперь я приведу определение, которое, на мой взгляд, точнее всего определяет его суть.
Сильный или общий ИИ (AGI) — это ИИ, который может ориентироваться в меняющихся условиях, моделировать и прогнозировать развитие ситуации. А если ситуация выходит за стандартные алгоритмы, то самостоятельно найти ее решение. Например, решить задачу «поступить в университет» или изучить правила игры в шашки, и вместо шахмат начать играть в шашки.
Какими же качествами должен обладать такой ИИ?
Мышление — использование таких методов, как дедукция, индукция, ассоциация и т.д., которые направлены на выделение фактов из информации, их представление (сохранение). Это позволит точнее решать задачи в условиях неопределённости.
Память — использование различных типов памяти (кратковременная, долговременная). То есть задачи должны решаться с учетом накопленного опыта. Сейчас же, если вы пообщаетесь с ChatGPT 4, то увидите, что алгоритм обладает небольшой краткосрочной памятью и через некоторое время забывает, с чего все начиналось. Вообще, по моему мнению, вопрос памяти и «массивности» ИИ-моделей станет ключевым ограничением в развитии ИИ. Об этом чуть ниже.
Планирование — тактическое и стратегическое. Да, уже есть исследования, которые утверждают, что ИИ может планировать свои действия и даже обманывать человека для достижения своих целей. Но сейчас это все равно только в стадии зарождения. Чем глубже происходит планирование, особенно в условиях неопределенности, тем больше нужно мощностей. Ведь одно дело планировать игру в шахматы на 3—6 шагов в глубину, где все правила четкие, а другое в ситуации неопределенности.
Обучение — имитация действий другого объекта и обучение через проведение экспериментов. Сейчас ИИ учится на больших массивах данных, но он сам не моделирует и не проводит эксперименты. Хотя мы не до конца понимаем, как работает тот же Chat GPT, и это одна из главных проблем, обучение требует формирования долгосрочной памяти и сложных взаимосвязей. А это, как мы поняли, проблема для ИИ.
И вот такого сильного ИИ сейчас нет ни у кого. А заявление о скором (в горизонте 2024—2028 годов) появлении сильного ИИ, на мой взгляд, ошибочны или спекулятивны. Хотя, может, я обладаю слишком ограниченным знанием…
Да, ChatGPT от OpenAI и другие LLM умеют генерировать текст / иллюстрацию / видео через анализ запроса и обработку больших данных. Но они лишь транслируют то, что им дали для обучения создатели. Они ищут наиболее подходящие варианты сочетания слов и предложений, слов и изображений к запросу, в общем, ассоциативные сочетания. Но не стоит питать иллюзии, это лишь математика и статистика. А в их ответах много «брака» и «галлюцинаций». К реальному взаимодействию с миром они еще не готовы.
Приведу простой пример на базе LLM.
Я — выходец из проектного менеджмента и в рамках своей работы решил написать статью о том, почему Agile не является универсальным подходом к управлению проектами, почему при правильном применении любая компания и команда должны уходить ближе к гибридным или каскадным подходам.
Моими помощниками в написании текста стали все те же ChatGPT, GigaChat, YandexGPT и AI Search.
Я сформулировал простой запрос: «Напиши пост о том, почему Agile бесконечно применять неправильно. Сделай акцент на том, что проведение ретроспектив должно уводить от ситуации неопределенности к ситуации сложных упорядоченных или простых упорядоченных систем».
Ответ ChatGPT4: «Agile — это подход к разработке программного обеспечения, который основан на итеративном и инкрементном создании продукта, сотрудничестве между самоорганизующимися командами и постоянном улучшении процесса. Одним из ключевых принципов Agile является проведение регулярных ретроспектив, то есть сессий, на которых команда анализирует свою работу, выявляет проблемы и находит способы их решения.
Ретроспективы — это мощный инструмент для повышения эффективности и качества работы, но только если они проводятся правильно. К сожалению, многие команды допускают ошибку, применяя Agile бесконечно, без учета контекста и изменений в окружающей среде. Это приводит к тому, что ретроспективы становятся бесполезными, скучными и демотивирующими.
Чтобы избежать этого, нужно понимать, что Agile не является универсальным решением для любой ситуации. В зависимости от степени неопределенности и сложности проекта, команда может находиться в одной из четырех зон: хаоса, сложности, порядка или простоты. Эти зоны можно представить в виде матрицы, где по горизонтали отложена степень неопределенности, а по вертикали — степень сложности.
!Матрица зон (редакция чат-бота, он именно так обозначил эту область)
Каждая зона требует своего подхода к ретроспективам и улучшениям. В зоне хаоса команда сталкивается с непредсказуемыми и экстремальными ситуациями, которые требуют быстрого реагирования и адаптации. В этом случае ретроспективы должны быть короткими, частыми и фокусированными на выживании и стабилизации. В зоне сложности команда работает с неясными и динамичными требованиями, которые требуют творчества и экспериментирования. В этом случае ретроспективы должны быть длинными, редкими и фокусированными на обучении и инновациях. В зоне порядка команда работает с ясными и стабильными требованиями, которые требуют дисциплины и оптимизации. В этом случае ретроспективы должны быть средними, регулярными и фокусированными на эффективности и качестве. В зоне простоты команда работает с очевидными и простыми требованиями, которые требуют минимального усилия и внимания. В этом случае ретроспективы могут быть опущены или проводиться по необходимости.
Однако, важно понимать, что зоны не являются статичными и могут меняться со временем. Поэтому, команда должна постоянно оценивать свой контекст и адаптировать свой подход к ретроспективам. Цель ретроспектив не в том, чтобы применять Agile бесконечно, а в том, чтобы уводить команду от ситуации неопределенности к ситуации сложных упорядоченных или простых упорядоченных систем. Только тогда ретроспективы будут приносить пользу и удовольствие команде и проекту».
Ответ GigaChat: «Agile — это методология разработки программного обеспечения, которая стала очень популярной в последние годы. Она предлагает гибкий подход к управлению проектами, который позволяет быстро реагировать на изменения и адаптироваться к новым требованиям. Однако, бесконечное применение Agile может привести к проблемам.
Одной из главных причин, почему Agile бесконечно применять неправильно, является то, что он может привести к ситуации неопределенности. В Agile-проектах мы часто сталкиваемся с изменениями требований и приоритетов, что может вызывать неопределенность в отношении того, что нужно делать дальше.
Проведение ретроспектив является одним из способов борьбы с этой неопределенностью. Ретроспективы помогают команде понять, что было сделано правильно и что нужно улучшить в будущем. Они также помогают команде перейти от ситуации неопределенности к ситуации сложных упорядоченных или простых упорядоченных систем.
Однако, если мы бесконечно применяем Agile без проведения ретроспектив, то мы можем остаться в ситуации неопределенности. Это может привести к тому, что команда будет тратить много времени на исправление ошибок и адаптацию к новым требованиям, а не на создание нового функционала.
Кроме того, бесконечное применение Agile может привести к тому, что команда будет постоянно работать над мелкими задачами и не будет иметь времени на создание больших функциональных блоков. Это может привести к тому, что проект будет развиваться медленно и не будет соответствовать ожиданиям заказчика.
В целом, Agile — это отличный подход к управлению проектами, но его бесконечное применение может привести к проблемам. Проведение ретроспектив помогает команде перейти от ситуации неопределенности к ситуации сложных упорядоченных или простых упорядоченных систем и улучшить качество работы команды».
Ответ Yandex GPT2: «Бесконечное применение Agile может привести к неправильным решениям и проблемам с качеством продукта. Важно понимать, что Agile не является универсальным решением для всех проектов и команд, и его постоянное использование может привести к потере эффективности и продуктивности.
Одним из ключевых принципов Agile является проведение ретроспективных сессий, которые помогают команде проанализировать свои прошлые успехи и неудачи. Однако, если эти ретроспективы проводятся постоянно, это может увести команду от решения реальных проблем и задач.
Вместо того чтобы помогать команде развиваться и становиться более эффективными, постоянные ретроспективы могут привести к ситуации, когда команда постоянно обсуждает одни и те же проблемы и не может продвинуться вперед. Это может создать ситуацию неопределенности, когда команда не знает, что делать дальше, или же наоборот, может привести к созданию сложных и неупорядоченных систем, которые только усложняют процесс работы.
Чтобы избежать этого, важно определить, когда и как часто проводить ретроспективные сессии. Они должны быть сфокусированы на анализе конкретных проблем и возможностей для улучшения, а не на обсуждении одних и тех же вопросов снова и снова.
Также важно понимать, что каждая команда и проект уникальны, и то, что работает для одной команды, может не работать для другой».
YandexGPT 3 Pro: «Почему Agile может быть неправильным выбором?
Agile — это методология управления проектами, которая предполагает итеративный подход к разработке программного обеспечения. Она включает в себя регулярные встречи команды, постоянное взаимодействие с заказчиком и готовность к изменениям.
Однако применение Agile не всегда является правильным решением. В некоторых случаях использование этой методологии может привести к негативным последствиям.
Вот несколько причин, почему Agile может быть неправильным выбором:
Не подходит для крупных проектов. Agile лучше всего подходит для небольших проектов, где можно быстро реагировать на изменения. В крупных проектах, где требуется более тщательное планирование и координация, Agile может привести к хаосу и потере контроля.
Не подходит для проектов с чёткими требованиями. Если проект имеет чёткие требования, которые не подлежат изменению, Agile может привести к ненужным затратам времени и ресурсов.
Не подходит для проектов с длительным циклом разработки. Agile предполагает короткие циклы разработки, которые позволяют быстро реагировать на изменения. В проектах с длительным циклом разработки это может привести к тому, что проект будет постоянно меняться, и его завершение станет невозможным.
Важно понимать, что Agile — это не универсальная методология, которая подходит для всех проектов. Выбор методологии должен основываться на особенностях проекта, его целях и задачах.
Как избежать негативных последствий применения Agile?
Чтобы избежать негативных последствий применения Agile, необходимо тщательно проанализировать проект и определить, подходит ли эта методология для его реализации. Если вы решите использовать Agile, необходимо соблюдать следующие правила:
Проводить регулярные ретроспективы. Ретроспективы позволяют команде анализировать свою работу и выявлять слабые места. Это помогает избежать повторения ошибок и повысить эффективность работы.
Устанавливать чёткие цели и сроки. Это поможет команде сосредоточиться на выполнении задач и избежать потери времени.
Поддерживать коммуникацию с заказчиком. Это позволит своевременно получать обратную связь и вносить необходимые изменения в проект.
Проведение ретроспектив должно уводить от ситуации неопределённости к ситуации сложных упорядоченных или простых упорядоченных систем. Это позволит команде анализировать свою работу, выявлять слабые места и принимать меры по их устранению.
В заключение можно сказать, что Agile — это эффективная методология, которая может принести много пользы при правильном применении. Однако её использование требует тщательного планирования и анализа».
Ответ AI Search: «Привет, друзья! Сегодня я хотел бы поделиться своими мыслями о том, почему Agile, несмотря на его популярность и эффективность, часто применяется неправильно. Особое внимание я обращу на то, почему проведение ретроспектив является важным инструментом для перехода от ситуации неопределенности к упорядоченным или сложным системам.
Agile — это философия и подход к разработке программного обеспечения, который изменяет традиционный подход к управлению проектами, делая его более гибким и адаптивным к изменениям. Однако, несмотря на явные преимущества, Agile может быть применен неправильно, и в результате, его потенциал не раскрывается полностью.
Одной из главных проблем неправильного применения Agile является недостаток регулярного проведения ретроспектив. Ретроспектива, как экспертная оценка прошедшей работы, помогает командам принять во внимание произошедшие изменения, недостатки и улучшения при планировании будущих итераций. Это позволяет отточить процесс работы и увеличить эффективность. Однако, некоторые команды часто игнорируют проведение ретроспектив или проводят их несистематически.
Не проводя регулярные ретроспективы, команды упускают возможность видеть свои проблемы, подтверждать или изменять свое видение и настраивать этапы разработки. В результате, команды могут застрять в ситуации неопределенности и не иметь возможности двигаться вперед.
Одним из главных принципов Agile является обеспечение быстрого отклика на изменения и непрерывное улучшение процесса работы. Если ретроспективы не проводятся регулярно, команды недостаточно осознают свои ошибки и упущения, что затрудняет прогресс в достижении упорядоченности и эффективности.
Кроме того, проведение регулярных ретроспектив помогает двигаться командам от ситуации неопределенности к сложным или простым упорядоченным системам. Начиная с простых упорядоченных систем, где правила и процессы легко определены и контролируются, команды могут постепенно переходить к более сложным системам, где правила более неоднозначны и требуют большей адаптации.
Итак, ретроспективы являются важной частью Agile-процесса и помогают командам двигаться от неопределенности к упорядоченности и сложным системам. Они позволяют командам осознать свои ошибки и изъяны, а также увидеть области для улучшения. Не пренебрегайте регулярными ретроспективами, чтобы ваша команда могла максимально раскрыть потенциал Agile и достичь высокой эффективности работы.
Желаю вам успешной работы в применении Agile и постоянного совершенствования своих процессов! Будьте гибкими, настойчивыми и внимательными».
Ну, и мой пост: «Почему Agile не вечен и не панацея?»
В последние годы все как один декларируют, что они Agile.
Давайте будем честны: большинство под этим скрывают банальный хаос. Ведь Agile — не про отсутствие планирования. Кроме того, он очень чувствителен к выполнению определенных правил и к стабильности команды, ее мотивации. Если у вас не соблюдаются эти условия, вы — не Agile.
Использование того же Scrum, Kanban или других подходов должно приводить к отсутствию необходимости реализации проектов по Agile.
Но почему?
Давайте вспомним, что Agile изначально был задуман для работы и реализации проектов в ситуации высокой неопределенности.
Даже есть специальный инструмент — модель Кеневин, — который помогает понять, в какой ситуации вы находитесь и какой подход нужно выбирать, на чем фокусироваться. Так, в упорядоченных системах (простых или сложных ситуациях) Agile, наоборот, противопоказан, т.к. увеличивает затраты на достижение результата. То есть Agile результативен в случаях, когда надо сделать «то — не знаю что». Но он не про эффективность.
А теперь давайте обратим внимание на ретроспективу. Все подходы внутри Agile предполагают регулярные ретроспективы, анализ своей работы, взаимодействия с клиентом / заказчиком / партнером. То есть сама логика этих инструментов в том, чтобы уйти от неопределенной ситуации и научиться прогнозировать их, становиться эффективнее.
Если вы постоянно (раз в полгода-год) меняете работу или постоянно запускаете новые продукты, а не тиражируете определенные решения (что для бизнеса странно), то да, вам нужно быть Agile.
Но если у вас есть сегмент, и вы наработали с опытом и экспертизой типовые подходы / продукты, которые нужно корректировать и адаптировать в небольшой части, то рано или поздно вы должны уйти от Agile и прийти к упорядоченной системе, где нужны каскадные или гибридные подходы. Эти ретроспективы вас и должны привести к пониманию того, чего хотят заказчики в 90% случаев и как работает организация.
В итоге, если вы Agile на постоянной основе и везде, а не на период перестройки / запуска / адаптации, то это может говорить о том, что:
— вы не соблюдаете инструменты Agile;
— вы не нашли свой продукт и свою нишу, не наработали нужную экспертизу;
— у вас каждый раз уникальный продукт / проект (что должно отражаться на высокой цене ваших услуг);
— организация «больна» изнутри, и вы таким образом маскируете высокую текучку, отсутствие работы над процессами и т. д.
А что вы думаете по этому поводу?»
Качество ответов нейросетей больше похоже на слабого студента, который просто подбирает похожие слова, но не понимает, о чем говорит. Мог бы я добиться аналогичного поста от нейросети? Чтобы она передала мои смыслы? Да, конечно, но свой пост я написал за 25 минут, а сколько времени у меня ушло бы на попытки добиться такого результата от ИИ? И похоже ли это на действительно думающий интеллект? Да и вообще на Интеллект?
Дело в том, что наше мышление сильно завязано на идеях и образах. То есть в основном в мышлении мы используем подход от общего к частному, мыслим образами, и потом от неких размытых, но понятных нам на бессознательном уровне абстракций приходим к мельчайшим деталям. Параллельно проводим кучу ассоциаций, целиком завязанных опять же на образах. Не зря в человеческой речи так много метафор, сравнений, намеков и переиначиваний слов.
Современные нейросети «думают» совершенно иначе. Им просто неведомы понятия «смысл», «суть», «идея», как и сам процесс размышления. Сгенерированные нейросетью тексты выглядят как логичные не потому, что нейросеть реально понимает, о чем пишет, а потому что она способна вычислить, какие слова чаще всего стоят рядом друг с другом в доступных для ее обучения текстах на заданную вами тему. Чистая математика, основанная на просчете вероятностей.
Однако справедливости ради надо отметить и существенный прогресс в этом направлении. Сейчас разработчики стараются научить ИИ размышлять: он задает сам себе вопросы и, давая ответы, делает выводы. Это имитация внутреннего диалога для повышения качества контента, что свойственно моделям от Open AI конца 2024 года и Yandex GPT 4 Pro RC.
Вот пример ответа модели Yandex GPT 4 Pro RC на запрос «Напиши пост о том, почему Agile бесконечно применять неправильно. Сделай акцент на том, что проведение ретроспектив должно уводить от ситуации неопределенности к ситуации сложных упорядоченных или простых упорядоченных систем».
Ответ Yandex GPT 4 Pro RC: «Почему Agile не всегда работает: как ретроспективы могут помочь перейти от неопределённости к порядку.
Agile — это гибкий подход к управлению проектами, который позволяет быстро адаптироваться к изменениям и улучшать процессы на основе обратной связи. Однако, несмотря на все преимущества, применение Agile без учёта контекста может привести к проблемам. В этом посте мы рассмотрим, почему Agile не стоит применять бесконечно и как ретроспективы помогают перейти от ситуации неопределённости к упорядоченным системам.
Проблемы бесконечного применения Agile
1. Отсутствие чёткой структуры. Agile основан на принципах гибкости и адаптивности, что может привести к отсутствию чёткой структуры и плана действий. Это может затруднить принятие решений и управление рисками.
2. Сложность оценки результатов. Без чёткого плана и критериев оценки результатов сложно определить, насколько успешно продвигается проект. Это может вызвать сомнения в эффективности подхода.
3. Риск потери контроля. Бесконечное применение Agile может привести к потере контроля над проектом. Без чётких границ и ограничений команда может потерять фокус и начать отклоняться от первоначальной цели.
4. Неэффективное использование ресурсов. Если команда постоянно адаптируется к новым условиям, это может привести к неэффективному использованию ресурсов. Вместо того чтобы сосредоточиться на ключевых задачах, команда будет тратить время на постоянные изменения.
5. Снижение мотивации команды. Постоянная адаптация и изменения могут вызвать стресс и усталость у команды. Это может снизить мотивацию и продуктивность.
Как ретроспективы помогают перейти к упорядоченным системам
Ретроспективы — это один из ключевых инструментов Agile, который помогает команде анализировать свою работу и выявлять области для улучшения. Они позволяют перейти от ситуации неопределённости к более упорядоченным системам, где процессы и решения становятся более предсказуемыми и управляемыми.
Вот несколько способов, как ретроспективы могут помочь:
• Определение проблем и их решений. Ретроспективы позволяют выявить проблемы, которые возникли в процессе работы, и найти способы их решения. Это помогает избежать повторения ошибок в будущем.
• Улучшение процессов. Ретроспективы помогают понять, какие процессы работают хорошо, а какие нуждаются в улучшении. Это позволяет оптимизировать рабочие процессы и повысить эффективность.
• Повышение мотивации. Когда команда видит результаты своих усилий и понимает, что они приносят пользу, это повышает мотивацию и удовлетворённость работой.
• Создание культуры непрерывного улучшения. Ретроспективы способствуют формированию культуры, в которой постоянное улучшение и адаптация являются нормой. Это помогает команде быть более гибкой и готовой к изменениям.
В целом, ретроспективы являются важным инструментом для перехода от ситуации неопределённости к более структурированным и упорядоченным процессам. Они помогают команде адаптироваться к изменениям, улучшать свои процессы и достигать поставленных целей».
Да, модель ушла в академичность и видно, что это выдержки из статей, а не размышление. Но это огромный прогресс, с моделью уже можно работать и использовать как инструмент.
Однако, имея в наличии только слабый ИИ и мечтая о более-менее сильном, уже сейчас различные исследователи в своей классификации выделяют суперсильный ИИ (ASI, Artificial Superintelligence).
Это такой ИИ, который:
— может решать как рутинные, так и творческие задачи;
— моментально ориентируется в неопределенности даже без подключения к сети Интернет;
— адаптирует решение задач к контексту обстоятельств и доступных возможностей / ресурсов;
— понимает эмоции людей (не только через текстовый запрос, но и на основе анализа мимики, тембра голоса и других параметров) и учитывает их в работе;
— способен самостоятельно взаимодействовать с реальным миром для решения задач.
Это такой ИИ, который мы видим пока что только в фантастических фильмах. Даже сам ИИ пишет об ASI как о «гипотетической концепции» и «предмете научной фантастики и активных исследований в области искусственного интеллекта» (YandexGPT 3 Pro). Это некоторая желаемая точка в далеком будущем, достигнуть которую пока не представляется возможным.
Chat GPT 4 характеризует ASI так: «гипотетическая система искусственного интеллекта с интеллектом, превосходящим человеческий. Это не просто усовершенствованный ИИ, а система, способная адаптироваться, учиться и развиваться самостоятельно, превышая человеческие способности в обучении, решении проблем, когнитивных функциях и самоусовершенствовании.
Суперсильный ИИ, или ASI, будет иметь возможность понимать и обрабатывать множество типов данных (текст, изображения, звук, видео), что позволит ему выполнять сложные задачи и принимать решения. Он будет использовать продвинутые технологии ИИ, такие как многомерные языковые модели (LLMs), многоразрядные нейронные сети и эволюционные алгоритмы.
В настоящее время ASI остается концептуальным и спекулятивным этапом развития ИИ, но он представляет собой значительный шаг вперед от текущего уровня ИИ».
И если слабых ИИ сейчас сотни, под каждую задачу, то сильных ИИ будут лишь десятки (скорее всего произойдет разделение по направлениям, мы это рассмотрим в следующем блоке), а суперсильный ИИ будет одним на государство или вообще всю планету.
Ограничения на пути к сильному ИИ
Если быть честным, я мало верю в быстрое появление сильного или суперсильного ИИ.
Во-первых, это очень затратная и сложная задача с точки зрения регуляторных ограничений. Эпоха бесконтрольного развития ИИ заканчивается. На него будет накладываться все больше ограничений. На тему регулирования ИИ мы поговорим в отдельной главе.
Ключевой тренд — риск-ориентированный подход. Так, в риск-ориентированном подходе сильный и суперсильный ИИ будут на верхнем уровне риска. А значит, и меры со стороны законотворчества будут заградительными.
Во-вторых, это сложная задача с технической точки зрения, причем сильный ИИ будет и очень уязвимым.
Сейчас, в середине 2020-х, для создания и обучения сильного ИИ нужны гигантские вычислительные мощности. Так, по мнению Леопольда Ашенбреннера, бывшего сотрудник OpenAI из команды Superalignment, потребуется создание дата-центра стоимостью в триллион долларов США. А его энергопотребление превысит всю текущую электрогенерацию США.
Также нужны и сложные ИИ-модели (на порядки сложнее нынешних) и их сочетание (не только LLM для анализа запросов). То есть придется экспоненциально увеличивать количество нейронов, выстраивать связи между нейронами, а также координировать работу различных сегментов.
При этом надо понимать, что если человеческие нейроны могут быть в нескольких состояниях, а активация может происходить «по-разному» (да простят меня биологи за такие упрощения), то машинный ИИ — упрощенная модель, которая так не умеет. Условно говоря, машинные 80—100 млрд нейронов не равны человеческим 80—100 млрд. Машине потребуется больше нейронов для решения аналогичных задач. Тот же GPT4 оценивают в 100 трлн параметров (условно нейронов), и он все равно уступает человеку.
Все это приводит к нескольким факторам.
Первый фактор — рост сложности всегда приводит к проблемам надежности, увеличивается количество точек отказа.
Сложные ИИ-модели трудно как создавать, так и поддерживать от деградации во времени, в процессе работы. ИИ-модели нужно постоянно «обслуживать». Если этого не делать, то сильный ИИ начнет деградировать, а нейронные связи будут разрушаться, это нормальный процесс. Любая сложная нейросеть, если постоянно не развивается, начинает разрушать ненужные связи. При этом поддержание взаимосвязей между нейроннами — энергозатратная задача. ИИ всегда будет оптимизироваться и искать наиболее эффективное решение задачи, а значит, начнет отключать ненужные потребители энергии.
То есть ИИ станет похожим на старика с деменцией, а срок «жизни» сильно сократится. Представьте, что может натворить сильный ИИ с его возможностями, но который при этом будет страдать потерей памяти и резкими откатами в состояние ребенка? Даже для текущих ИИ-решений это актуальная проблема.
Давайте приведем пару простых примеров из жизни.
Можно сравнить создание сильного ИИ с тренировкой мышц человека. Когда мы только начинаем заниматься в спортивном зале и увлекаться силовыми занятиями, бодибилдингом, то прогресс идет быстро, но чем дальше, тем ниже КПД и рост результатов. Нужно все больше ресурсов (времени, нагрузок и энергии из пищи) для прогресса. Да даже просто удержание формы становится все более сложной задачей. Плюс рост силы идет от толщины сечения мышцы, а вот масса растет от объема. В итоге мышца в определенный момент станет настолько тяжелой, что не сможет сама себя двигать, а может даже и сама себя повредить.
Еще один пример сложности создания, но уже из области инженерии — гонки Формулы 1. Так, отставание в 1 секунду можно устранить, если вложить 1 млн и 1 год. Но вот чтобы отыграть решающие 0,2 секунды, может потребоваться уже 10 млн и 2 года работы. А фундаментальные ограничения конструкции машины могут заставить вообще пересмотреть всю концепцию гоночной машины.
И даже если посмотреть на обычные машины, то все точно так же. Современные автомобили дороже и создавать, и содержать, а без специального оборудования невозможно поменять даже лампочку. Если взять современные гиперкары, то после каждого выезда требуются целые команды техников для обслуживания.
Если все же посмотреть с точки зрения разработки ИИ, то в этой области есть два ключевых параметра:
— количество слоев нейронов (глубина ИИ-модели);
— количество нейронов в каждом слое (ширина слоя).
Глубина определяет, насколько велика способность ИИ к абстрагированию. Недостаточная глубина модели влечет за собой проблему с неспособностью к глубокому системному анализу, поверхностности этого анализа и суждений.
Ширина слоев определяет число параметров / критериев, которыми может оперировать нейронная сеть на каждом слое. Чем их больше, тем более сложные модели используются и возможно более полное отражение реального мира.
При этом, если количество слоев линейно влияет на функцию, то ширина нет. В итоге мы и получаем ту аналогию с мышцей — размер топовых ИИ-моделей (LLM) переваливает за триллион параметров, но модели на 2 порядка меньше не имеют критического падения производительности и качества ответов. Важнее то, на каких данных обучена модель и имеет ли она специализацию.
Ниже приведена статистика для LLM моделей от разных производителей.
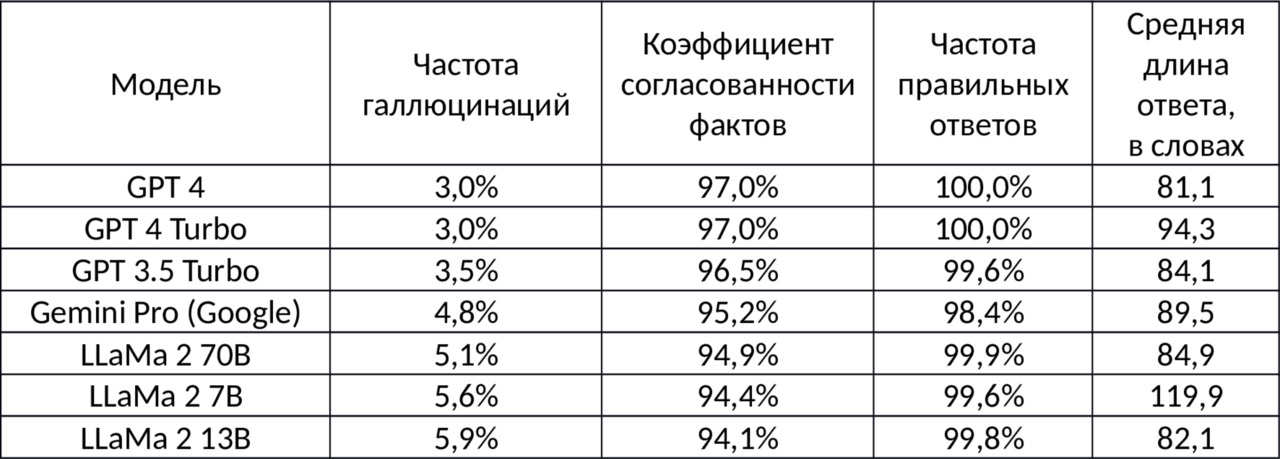
Сравните показатели LLaMa 2 70B, LLaMa 2 7B, LLaMa 2 13B. Показатели 70B, 7B и 13B условно демонстрируют сложность и обученность модели — чем выше значение, тем лучше. Но как мы видим, качество ответов от этого радикально не меняется, в то время как цена и трудозатраты на разработку растут существенно.
И мы можем наблюдать, как лидеры наращивают вычислительные мощности, отстраивая новые дата-центры и в спешке решая вопросы энергоснабжения и охлаждения этих монстров. При этом повышение качества модели на условные 2% требует увеличения вычислительных мощностей на порядок.
Теперь практический пример к вопросу поддержания и обслуживания из-за деградации. Тут также будет заметно влияние людей. Любой ИИ, особенно на раннем этапе, будет обучаться на основе обратной связи от людей (их удовлетворённость, начальные запросы и задачи). Например, тот же ChatGPT4 использует запросы пользователей для дообучения своей модели, чтобы давать более релевантные ответы и при этом снизить нагрузку на «мозг». И в конце 2023 года появились статьи, что ИИ-модель стала «более ленивой». Чат-бот либо отказывается отвечать на вопросы, либо прерывает разговор, либо отвечает просто выдержками из поисковиков и других сайтов. Причем к середине 2024 года это уже стало нормой, когда модель просто приводит выдержки из Википедии.
Одной из возможных причин этого является упрощение самих запросов от пользователей (они становятся всё более примитивными). Ведь LLM не придумывают ничего нового, эти модели пытаются понять, чего вы хотите от них услышать и подстраиваются под это (проще говоря, у них также формируются стереотипы). Они ищут максимальную эффективность связки трудозатраты-результат, «отключая» ненужные нейронные связи. Это называется максимизацией функции. Просто математика и статистика.
Причем такая проблема будет характерна не только для LLM.
В итоге, чтобы ИИ не стал деградировать, придется загружать его сложными исследованиями, при этом ограничивая его нагрузку примитивными задачами. А стоит его только выпустить в открытый мир, как соотношение задач будет в пользу простых и примитивных запросов пользователей или решения прикладных задач.
Вспомните себя. Действительно ли для выживания и размножения нужно развиваться? Или какое соотношение в вашей работе между интеллектуальными и рутинными задачами? А какого уровня математические задачи на этой работе вы решаете? Вам требуются интегралы и теория вероятности или же только математика до 9-го класса?
Второй фактор — количество данных и галлюцинации.
Да, мы можем увеличить текущие модели в ХХХХ раз. Но тому же прототипу ChatGPT5 уже в 2024 году не хватает данных для обучения. Ему отдали все, что есть. А сильному ИИ, который будет ориентироваться в неопределенности, на текущем уровне развития технологий просто не хватит данных. Необходимо собирать метаданные о поведении пользователей, думать, как обходить ограничения авторских прав и этические ограничения, собирать согласия пользователей.
Кроме того, на примере текущих LLM мы видим еще один тренд. Чем «всезнающее» модель, тем больше у нее неточностей, ошибок, абстракций и галлюцинаций. При этом, если взять базовую модель и дать ей в качестве знаний определенную предметную область, то качество ее ответов повышается: они предметнее, она меньше фантазирует (галлюцинирует) и меньше ошибается.
Третий фактор — уязвимость и затраты.
Как мы рассмотрели выше, нам потребуется создание дата-центра стоимостью в триллион долларов США. А его энергопотребление превысит всю текущую электрогенерацию США. А значит, потребуется и создание энергетической инфраструктуры с целым комплексом атомных электростанций. Да, ветряками и солнечными панелями эту задачу не решить.
Теперь добавим, что ИИ-модель будет привязана к своей «базе», и тогда одна удачная кибератака на энергетическую инфраструктуру обесточит весь «мозг».
А почему такой ИИ должен быть привязан к центру, почему нельзя сделать его распределенным?
Во-первых, распределенные вычисления все равно теряют в производительности и эффективности. Это разнородные вычислительные мощности, которые также загружены другими задачами и процессами. Кроме того, распределенная сеть не может гарантировать работу вычислительных мощностей постоянно. Что-то включается, что-то отключается. Доступная мощность будет нестабильной.
Во-вторых, это уязвимость перед атаками на каналы связи и ту же распределенную инфраструктуру. Представьте, что вдруг 10% нейронов вашего мозга просто отключилась (блокировка каналов связи или просто отключились из-за атаки), а остальные работают вполсилы (помехи и т.д.). В итоге снова имеем риск сильного ИИ, который то забывает, кто он, где он, для чего, то просто долго думает.
А уж если все придет к тому, что сильному ИИ потребуется мобильное (передвижное) тело для взаимодействия с миром, то реализовать это будет еще сложнее. Ведь как все это обеспечивать энергией и охлаждать? Откуда брать мощности для обработки данных? Плюс еще нужно добавлять машинное зрение и распознавание образов, а также обработку других датчиков (температура, слух и т.д.). Это огромные вычислительные мощности и потребность в охлаждении и энергии.
То есть это будет ограниченный ИИ с постоянным подключением к основному центру по беспроводной связи. А это снова уязвимость. Современные каналы связи дают выше скорость, но это сказывается на снижении дальности действия и проникающей способности, уязвимости перед средствами радиоэлектронной борьбы. То есть мы получаем рост нагрузки на инфраструктуру связи и рост рисков.
Тут можно, конечно, возразить. Например, тем, что можно взять предобученную модель и сделать ее локальной. Примерно так же, как я предлагаю разворачивать локальные ИИ-модели с «дообучением» в предметную область. Да, в таком виде все это может работать на одном сервере. Но такой ИИ будет очень ограничен, он будет «тупить» в условиях неопределенности и ему все равно нужна будет энергия и подключение к сети передачи данных. То есть это история не про создание человекоподобных суперсуществ.
Все это приводит к вопросам об экономической целесообразности инвестиций в это направление. Тем более с учетом двух ключевых трендов в развитии генеративного ИИ:
— создание дешевых и простых локальных моделей для решения специализированных задач;
— создание ИИ-оркестраторов, которые будут декомпозировать запрос на несколько локальных задач и затем перераспределять это между разными локальными моделями.
Таким образом, слабые модели с узкой специализацией останутся более свободными и простыми для создания. При этом смогут решать наши задачи. И в итоге мы имеем более простое и дешевое решение рабочих задач, нежели создание сильного ИИ.
Конечно, мы выносим за скобки нейроморфные и квантовые системы, но мы эту тему рассмотрим чуть ниже. И, естественно, в моих отдельных цифрах и аргументах могут быть ошибки, но в целом я убежден, что сильный ИИ — не вопрос ближайшего будущего.
Если резюмировать, то у сильного ИИ есть несколько фундаментальных проблем.
— Экспоненциальный рост сложности разработки и противодействия деградации сложных моделей.
— Недостаток данных для обучения.
— Стоимость создания и эксплуатации.
— Привязанность к ЦОДам и требовательность к вычислительным ресурсам.
— Низкая эффективность текущих моделей по сравнению с человеческим мозгом.
Именно преодоление этих проблем определит дальнейший вектор развития всей технологии: либо все же сильный ИИ появится, либо мы уйдем в плоскость развития слабых ИИ и ИИ-оркестраторов, которые будут координировать работу десятков слабых моделей.
Но сейчас сильный ИИ никак не вяжется с ESG, экологией и коммерческим успехом. Его создание возможно только в рамках стратегических и национальных проектов, финансируемых государством. И вот один из интересных фактов в данном направлении: бывший глава Агентства национальной безопасности США (до 2023 года), генерал в отставке, Пол Накасоне в 2024 году вошел в совет директоров OpenAI. Официальная версия — для организации безопасности Chat GPT.
Также рекомендую прочитать документ под названием «Осведомленность о ситуации: Предстоящее десятилетие». Его автор — Леопольд Ашенбреннер, бывший сотрудник OpenAI из команды Superalignment. Документ доступен по QR-коду и гиперссылке.

Также сокращенный разбор этого документа доступен по QR-коду и гиперссылке ниже.

Если совсем упростить, то ключевые тезисы автора:
— К 2027 году сильный ИИ (AGI) станет реальностью.
Я с этим утверждением не согласен. Мои аргументы приведены выше, плюс некоторые тезисы ниже и описания рисков от авторов говорят о том же. Но опять же, что понимать под термином AGI? Свое определение я уже привел, но единого термина нет.
— AGI сейчас — ключевой геополитический ресурс. Забываем про ядерное оружие, это прошлое. Каждая страна будет стремиться получить AGI первой, как в своё время атомную бомбу.
Тезис спорный. Да, это отличный ресурс. Но как мне кажется, его значение переоценено, особенно с учетом сложности создания и обязательных будущих ошибок в его работе.
— Для создания AGI потребуется единый вычислительный кластер стоимостью в триллион долларов США. Такой уже строит Microsoft для OpenAI.
Помимо вычислительных мощностей нужны еще затраты на людей и решение фундаментальных проблем.
— Этот кластер будет потреблять больше электроэнергии, чем вся выработка США.
Этот тезис мы разобрали выше. Помимо триллиона долларов еще и инвестиции в электрогенерацию, а также появляются риски.
— Финансирование AGI пойдет от гигантов технологий — уже сегодня Nvidia, Microsoft, Amazon и Google выделяют по $100 миллиардов за квартал только на ИИ.
Считаю, что без государственного финансирования и, следовательно, вмешательства тут не обойтись.
— К 2030 году ежегодные инвестиции в ИИ достигнут $8 триллионов.
Отличное наблюдение. Теперь возникает вопрос, оправдано ли это экономически?
Несмотря на весь оптимизм Леопольда Ашенбреннера в области сроков создания AGI, он сам отмечает ряд ограничений:
— Недостаток вычислительных мощностей для проведения экспериментов.
— Фундаментальные ограничения, связанные с алгоритмическим прогрессом
— Идеи становятся всё сложнее, поэтому вероятно ИИ-исследователи (ИИ-агенты, которые будут проводить исследования за людей) лишь поддержат текущий темп прогресса, а не увеличат его в разы. Однако Ашенбреннер считает, что эти препятствия могут замедлить, но не остановить рост интеллекта ИИ систем.
Глава 3. А что может слабый ИИ и общие тренды
Слабый ИИ в прикладных задачах
Как вы уже, наверно, поняли, я — сторонник использования того, что есть. Возможно, это мой опыт антикризисного управления сказывается или просто ошибочное мнение. Но тем не менее, где можно применять текущий слабый ИИ на базе машинного обучения?
Наиболее релевантными направлениями для применения ИИ с машинным обучением можно обозначить:
— прогнозирование и подготовка рекомендаций для принятия решений;
— анализ сложных данных без чётких взаимосвязей, в том числе для прогнозирования и принятия решений;
— оптимизация процессов;
— распознавание образов, в том числе изображений и голосовых записей;
— автоматизация выполнения отдельных задач, в том числе через генерацию контента.
Направление, которое на пике популярности в 2023—2024 годах, — распознавание образов, в том числе изображений и голосовых записей, и генерация контента. Именно сюда идет основная масса разработчиков ИИ и именно таких сервисов больше всего.
При этом особое внимание заслуживает связка ИИ + IoT (Интернет вещей):
— ИИ получает чистые большие данные, в которых нет ошибок человеческого фактора для обучения и поиска взаимосвязей.
— Эффективность IoT повышается, так как становится возможным создание предиктивной (предсказательной) аналитики и раннего выявления отклонений.
Ключевые тренды
— Машинное обучение движется ко всё более низкому порогу вхождения.
Одна из задач, которую сейчас решают разработчики, — упрощение создания ИИ-моделей до уровня конструкторов сайтов, где для базового применения не нужны специальные знания и навыки. Создание нейросетей и дата-сайнс уже сейчас развиваются по модели «сервис как услуга», например, DSaaS — Data Science as a Service.
Знакомство с машинным обучением можно начинать с AUTO ML, его бесплатной версией, или DSaaS с проведением первичного аудита, консалтинга и разметкой данных. При этом даже разметку данных можно получить бесплатно. Всё это снижает порог вхождения.
— Создание нейросетей, которым нужно все меньше данных для обучения.
Несколько лет назад, чтобы подделать ваш голос, требовалось предоставить нейросети один-два часа записи вашей речи. Года два назад этот показатель снизился до нескольких минут. Ну, а в 2023 году компания Microsoft представила нейросеть, которой достаточно уже трех секунд для подделки.
Плюс появляются инструменты, с помощью которых можно менять голос даже в онлайн режиме.
— Создание систем поддержки и принятия решений, в том числе отраслевых.
Будут создаваться отраслевые нейросети, и всё активнее будет развиваться направление рекомендательных сетей, так называемые «цифровые советники» или решения класса «системы поддержки и принятия решений (DSS) для различных бизнес-задач».
Практический пример
Этот кейс мы рассмотрим еще не раз, так как это моя личная боль и тот продукт, над которым я работаю.
В проектном управлении существует проблема — 70% проектов либо проблемные, либо провальные.
— среднее превышение запланированных сроков наблюдается в 60% проектов, а среднее превышение на 80% от изначального срока;
— превышение бюджетов наблюдается в 57% проектов, а среднее превышение составляет 60% от изначального бюджета;
— недостижение критериев успешности — в 40% проектов.
При этом управление проектами уже занимает до 50% времени руководителей, а к 2030 году этот показатель достигнет 60%. Хотя еще в начале 20 века этот показатель был 5%. Мир становится все более изменчивым, и количество проектов растет. Даже продажи становятся все более «проектными», то есть комплексными и индивидуальными.
А к чему приводит такая статистика проектного управления?
— Репутационные потери.
— Штрафные санкции.
— Снижение маржинальности.
— Ограничение роста бизнеса.
При этом наиболее типовые и критичные ошибки:
— нечеткое формулирование целей, результатов и границ проекта;
— недостаточно проработанные стратегия и план реализации проекта;
— неадекватная организационная структура управления проектом;
— дисбаланс интересов участников проекта;
— неэффективные коммуникации внутри проекта и с внешними организациями.
Как решают эту задачу люди? Либо ничего не делают и страдают, либо идут учиться и используют трекеры задач.
При этом у обоих подходов есть свои плюсы и минусы. Например, классическое обучение дает возможность в ходе живого общения с учителем задавать вопросы и отрабатывать на практике различные ситуации. При этом оно дорого стоит и обычно не подразумевает дальнейшего сопровождения после окончания курса. Трекеры задач же, напротив, всегда под рукой, но при этом не адаптируются под конкретный проект и культуру компании, не способствуют выработке компетенций, а напротив, призваны для контроля работы.
В итоге, проанализировав свой опыт, я пришел к идее цифрового советника — искусственного интеллекта и предиктивных рекомендаций «что сделать, когда и как» за 10 минут для любого проекта и организации. Проектное управление становится доступным для любого руководителя условно за пару тысяч рублей в месяц.
В модель ИИ заложена методология управления проектами и наборы готовых рекомендаций. ИИ будет готовить наборы рекомендаций и постепенно самообучаться, находить все новые закономерности, а не привязываться к мнению создателя и того, кто будет обучать модель на первых этапах.
Глава 4. Генеративный ИИ
Что такое генеративный искусственный интеллект?
Ранее мы рассмотрели ключевые направления для применения ИИ:
— прогнозирование и принятие решений;
— анализ сложных данных без чётких взаимосвязей, в том числе для прогнозирования;
— оптимизация процессов;
— распознавание образов, в том числе изображений и голосовых записей;
— генерация контента.
Направления ИИ, которые сейчас на пике популярности, — распознавание образов (аудио, видео, числа) и на их основе генерация контента: аудио, текст, код, видео, изображения и так далее. В том числе к генеративному ИИ можно отнести и цифровых советников.
Проблемы генеративного ИИ
По состоянию на середину 2024 года направление генеративного ИИ нельзя назвать успешным. Так, например, в 2022 году компания OpenAI понесла убытки в размере $540 млн из-за разработки ChatGPT. А для дальнейшего развития и создания сильного ИИ потребуется еще около 100 млрд долларов. Такую сумму озвучил сам глава OpenAI. Такой же неблагоприятный прогноз на 2024 год дает и американская компания CCS Insight.
Для справки: операционные затраты Open AI составляют $700 000 в день на поддержание работоспособности чат-бота ChatGPT.
Общий тренд поддерживает и Алексей Водясов, технический директор компании SEQ: «ИИ не достигает тех маркетинговых результатов, о каких говорили ранее. Их использование ограничено моделью обучения, при этом затраты и объем данных для обучения растет. В целом же за хайпом и бумом неизбежно следует спад интереса. ИИ выйдет из фокуса всеобщего внимания так же быстро, как и вошёл, и это как раз нормальное течение процесса. Возможно, спад переживут не все, но ИИ — это действительно „игрушка для богатых“, и таковой на ближайшее время и останется». И мы согласны с Алексеем, после шумихи в начале 2023 года уже к осени наступило затишье.
Дополняет картину расследование Wall Street Journal, согласно которому, большинство ИТ-гигантов пока не научилось зарабатывать на возможностях генеративного ИИ. Microsoft, Google, Adobe и другие компании, которые вкладываются в искусственный интеллект, ищут способы заработать на своих продуктах. Несколько примеров:
— Google планирует повысить стоимость подписки на программное обеспечение с поддержкой ИИ;
— Adobe устанавливает ограничения на количество обращений к сервисам с ИИ в течение месяца;
— Microsoft хочет взимать с бизнес-клиентов дополнительные $30 в месяц за возможность создавать презентации силами нейросети.
Ну, и вишенка на торте — расчёты Дэвида Кана (David Cahn), аналитика Sequoia Capital, показывающая, что компаниям ИИ-индустрии придётся зарабатывать около $600 млрд в год, чтобы компенсировать расходы на свою ИИ-инфраструктуру, включая ЦОД. Единственный, кто сейчас хорошо зарабатывает на ИИ, — разработчик ускорителей Nvidia.
Подробно статью можно прочитать по QR-коду и гиперссылке ниже.

Вычислительные мощности — одна из главных статей расходов при работе с ГИИ: чем больше запросов к серверам, тем больше счета за инфраструктуру и электроэнергию. В выигрыше только поставщики «железа» и электроэнергии. Так, Nvidia в августе 2023 года заработала около $5 млрд благодаря продажам своих ускорителей для ИИ A100 и H100 только китайскому ИТ-сектору.
На практике это можно увидеть на двух примерах.
Первый — Zoom пытается снизить затраты, используя более простой чат-бот, разработанный своими силами и требующий меньших вычислительных мощностей по сравнению с последней версией ChatGPT.
Второй — наиболее известные разработчики ИИ (Microsoft, Google, Apple, Mistral, Anthropic и Cohere) стали делать фокус на создании компактных ИИ-моделей, так как они дешевле и экономичнее.
Большие модели, например, GPT-4 от OpenAI, у которых более 1 трлн параметров и стоимость создания оценивается более 100 миллионов долларов, не имеют радикального преимущества перед более простыми решениями в прикладных задачах. Компактные модели обучаются на более узких наборах данных и могут стоить менее 10 миллионов долларов, при этом используя менее 10 миллиардов параметров, но решать целевые задачи.
Например, Microsoft представила семейство небольших моделей под названием Phi. По словам СЕО компании Сатьи Наделлы, решения модели в 100 раз меньше бесплатной версии ChatGPT, однако они справляются со многими задачами почти так же эффективно. Юсуф Мехди, коммерческий директор Microsoft, отметил, что компания быстро осознала, что эксплуатация крупных моделей ИИ обходится дороже, чем предполагалось изначально. Поэтому Microsoft начала искать более экономически целесообразные решения.
Также и Apple планирует использовать такие модели для запуска ИИ непосредственно на смартфонах, что должно повысить скорость работы и безопасность. При этом потребление ресурсов на смартфонах будет минимальным.
Сами эксперты считают, что для многих задач, например, обобщения документов или создания изображений, большие модели вообще могут оказаться избыточными. Илья Полосухин, один из авторов основополагающей статьи Google в 2017 году, касающейся искусственного интеллекта, образно сравнил использование больших моделей для простых задач с поездкой в магазин за продуктами на танке. «Для вычисления 2 +2 не должны требоваться квадриллионы операций», — подчеркнул он.
Но давайте разберем все по порядку, почему так сложилось и какие ограничения угрожают ИИ, а главное, что будет дальше? Закат генеративного ИИ с очередной ИИ-зимой или трансформация?
Ограничения ИИ, которые приводят к проблемам
Ранее я привел «базовые» проблемы ИИ. Теперь же давайте немного уйдем в специфику именно генеративного ИИ.
— Беспокойство компаний о своих данных
Любой бизнес стремится охранять свои корпоративные данные и любыми способами старается исключить их. Это приводит к двум проблемам.
Во-первых, компании запрещают использование онлайн-инструментов, которые располагаются за периметром защищенной сети, в то время как любой запрос к онлайн-боту — это обращение во внешний мир. Вопросов к тому, как хранятся, как защищены и как используются данные, много.
Во-вторых, это ограничивает развитие вообще любого ИИ. Все компании от поставщиков хотят ИТ-решений с ИИ-рекомендациями от обученных моделей, которые, например, предскажут поломку оборудования. Но своими данными делится не готовы. Получается замкнутый круг.
Однако тут надо сделать оговорку. Некоторые ребята уже научились размещать языковые модели уровня Chat GPT 3 — 3,5 внутри контура компаний. Но эти модели все равно надо обучать, это не готовые решения. И внутренние службы безопасности найдут риски и будут против.
— Сложность и дороговизна разработки и последующего содержания
Разработка любого «общего» генеративного ИИ — это огромные затраты — десятки миллионов долларов. Кроме того, вам нужно много данных, очень много данных. Нейросети пока обладают низким КПД. Там, где человеку достаточно 10 примеров, искусственной нейросети нужны тысячи, а то и сотни тысяч примеров. Хотя да, он может найти такие взаимосвязи, и обрабатывать такие массивы данных, которые человеку и не снились.
Но вернемся к теме. Именно из-за ограничения по данным тот же ChatGPT лучше «соображает», если с ним общаться на английском языке, а не на русском. Ведь англоязычный сегмент интернета гораздо больше, чем наш с вами.
Добавим к этому затраты на электроэнергию, инженеров, обслуживание, ремонт и модернизацию оборудования и получим те самые 700 000 $ в день только на содержание Chat GPT. Много ли компаний могут потратить такие суммы с неясными перспективами монетизации (но об этом ниже)?
Да, можно снизить затраты, если разработать модель, а затем убрать все лишнее, но тогда это будет очень узкоспециализированный ИИ.
Поэтому большинство решений на рынке по факту являются GPT-фантиками — надстройками к ChatGPT.
— Беспокойство общества и ограничения регуляторов
Общество крайне обеспокоено развитием ИИ-решений. Государственные органы во всем мире не понимают, чего ожидать от них, как они повлияют на экономику и общество, насколько масштабна технология по своему влиянию. При этом его важность отрицать нельзя. Генеративные ИИ в 2023 году наделали больше шуму, чем когда-либо. Они доказали, что могут создавать новый контент, который можно спутать с человеческими творениями: тексы, изображения, научные работы. И доходит до того, что ИИ способен за считанные секунды разработать концептуальный дизайн для микросхем и шагающих роботов.
Второй фактор — безопасность. ИИ активно используют злоумышленники для атак на компании и людей. Так, с момента запуска ChatGPT с число фишинговых атак возросло на 1265%. Или, например, с помощью ИИ можно получить рецепт изготовления взрывчатки. Люди придумывают оригинальные схемы и обходят встроенные системы защиты.
Третий фактор — непрозрачность. Как работает ИИ, не понимают порой даже сами создатели. А для столь масштабной технологии непонимание того, что и почему может сгенерировать ИИ, создает опасную ситуацию.
Четвертый фактор — зависимость от обучающих. ИИ-модели строят люди, и обучают его тоже люди. Да, есть самообучаемые модели, но будут развиваться и узкоспециализированные, а материал для их обучения будут отбирать люди.
Все это означает, что отрасль начнут регулировать и ограничивать. Как именно — пока никто не понимает. Дополним это известным письмом в марте 2023 года, в рамках которого известные эксперты по всему миру потребовали ограничить развитие ИИ.
— Недостаток модели взаимодействия с чат-ботами
Полагаю, вы уже пробовали взаимодействовать с чат-ботами и остались, мягко говоря, разочарованными. Да, классная игрушка, но что с ней делать?
Надо понимать, что чат-бот — это не эксперт, а система, которая пытается угадать, что вы хотите увидеть или услышать, и дает вам именно это.
И чтобы получить практическую пользу, вы сами должны быть экспертом в предметной области. А если вы эксперт в своей теме, нужен ли вам ГИИ? А если вы не эксперт, то вы и не получите решения своего вопроса, а значит, не будет ценности, лишь общие ответы.
В итоге мы получаем замкнутый круг — экспертам это не нужно, а любителям не поможет. Кто тогда будет платить за такого помощника? А значит, на выходе имеем дорогу игрушку.
Кроме того, помимо экспертности в теме, нужно еще знать, как правильно формулировать запрос. А таких людей вообще считанные единицы. В итоге даже появилась новая профессия — промтинженер. Это человек, который понимает, как думает машина, и может правильно составить запрос к ней. А стоимость такого инженера на рынке — около 6000 рублей в час. И поверьте, он с первого раза не подберет правильный запрос для вашей ситуации.
Нужен ли такой инструмент бизнесу? Захочет ли бизнес стать зависимым от очень редких специалистов, которые еще и стоят даже дороже программистов, ведь обычные сотрудники не извлекут из него пользы?
Вот и получается, что рынок для обычного чат-бота не просто узкий, он исчезающе мал.
— Тенденция к производству некачественного контента, галлюцинации
В статье Искусственный интеллект: помощник или игрушка? я отметил, что нейросети просто собирают данные и не анализируют факты, их связанность. То есть чего больше в интернете / базе, на то они и ориентируются. Они не оценивают написанное критически. В тоге ГИИ легко генерирует ложный или некорректный контент.
Например, специалисты инженерной школы Тандона Нью-Йоркского университета решили проверить ИИ-помощника Copilot от Microsoft с точки зрения безопасности. В итоге, они обнаружили, что примерно в 40% случаев код, сгенерированный помощником, содержит ошибки или уязвимости. Подробная статья доступна по ссылке.
Еще один пример использования Chat GPT привел пользователь на Хабре. Вместо 10 минут и простой задачи получился квест на 2 часа.
А ИИ-галлюцинации — уже давно известная особенность. Что это такое и как они возникают, можно прочитать тут.
И это хорошо, когда случаи безобидные. Но бывают и опасные ошибки. Так, один пользователь спросил у Gemini, как сделать заправку для салата. По рецепту надо было добавить чеснок в оливковое масло и оставить настаиваться при комнатной температуре.
Пока чеснок настаивался, пользователь заметил странные пузырьки и решил перепроверить рецепт. Выяснилось, что в его банке размножались бактерии, вызывающие ботулизм. Отравление токсином этих бактерий протекает тяжело, вплоть до смести.
Я и сам периодически использую ГИИ, и чаще он дает, скажем так, не совсем корректный результат. А порой и откровенно ошибочный. Нужно провести 10—20 запросов с совершенно безумной детализацией, чтобы получить что-то вменяемое, что потом все равно надо переделывать / докручивать.
То есть за ним нужно перепроверять. И снова мы приходим к тому, что нужно быть экспертом в теме, чтобы оценить корректность контента и использовать его. И порой это занимает даже больше времени, чем сделать все с нуля и самому.
— Эмоции, этика и ответственность
ГИИ без правильного запроса будет склоняться к простому воспроизведению информации или созданию контента, не обращая внимания на эмоции, контекст и тон коммуникации. А по циклу статей о коммуникации мы уже знаем, что сбой в коммуникации может произойти очень легко. В итоге мы дополнительно ко всем проблемам выше можем получить еще и огромное количество конфликтов.
Также возникают вопросы относительно возможности определения авторства созданного контента, а также прав собственности на созданный контент. Кто несет ответственность за недостоверные или вредоносные действия, совершенные с помощью ГИИ? А как доказать, что авторство лежит именно за вами или вашей организацией? Возникает потребность в разработке этических стандартов и законодательства, регулирующих использование ГИИ.
— Экономическая целесообразность
Как мы уже поняли, самим разработать генеративный ИИ высокого класса может оказаться неподъёмной задачей. И у многих возникнет идея: «А почему бы не купить „коробку“ и не разместить у себя?» Но как вы думаете, сколько будет стоить такое решение? Сколько запросят разработчики?
А главное, каких масштабов должен быть бизнес, чтобы это все окупилось?
Что же делать?
Компании не собираются полностью отказываться от больших моделей. Например, Apple будет использовать ChatGPT в Siri для выполнения сложных задач. Microsoft планирует использовать последнюю модель OpenAI в новой версии Windows в качестве ассистента. При этом, тот же Experian из Ирландии и Salesforce из США, уже перешли на использование компактных моделей ИИ для чат-ботов и обнаружили, что они обеспечивают такую же производительность, как и большие модели, но при значительно меньших затратах и с меньшими задержками обработки данных.
Ключевым преимуществом малых моделей является возможность их тонкой настройки под конкретные задачи и наборы данных. Это позволяет им эффективно работать в специализированных областях при меньших затратах и проще решать вопросы безопасности. По словам Йоава Шохама (Yoav Shoham), соучредителя ИИ-компании AI21 Labs из Тель-Авива, небольшие модели могут отвечать на вопросы и решать задачи всего за одну шестую стоимости больших моделей.
— Не спешить
Ожидать заката ИИ не стоит. Слишком много в эту технологию было вложено за последние 10 лет, и слишком большим потенциалом она обладает.
Я рекомендую вспомнить о 8 принципе из ДАО Тойота, основы бережливого производства и одного из инструментов моего системного подхода: «Используй только надежную, испытанную технологию». В нем можно встретить целый ряд рекомендаций.
— Технологии призваны помогать людям, а не заменять их. Часто стоит сначала выполнять процесс вручную, прежде чем вводить дополнительное оборудование.
— Новые технологии часто ненадежны и с трудом поддаются стандартизации, а это ставит под угрозу поток. Вместо непроверенной технологии лучше использовать известный, отработанный процесс.
— Прежде чем вводить новую технологию и оборудование, следует провести испытания в реальных условиях.
— Отклони или измени технологию, которая идет вразрез с твоей культурой, может нарушить стабильность, надежность или предсказуемость.
— И все же поощряй своих людей не забывать о новых технологиях, если речь идет о поисках новых путей. Оперативно внедряй зарекомендовавшие себя технологии, которые прошли испытания и делают поток более совершенным.
Да, через 5—10 лет генеративные модели станут массовыми и доступными, достаточно умными, подешевеют и в итоге придут к плато продуктивности по хайп-циклу. И скорее всего, каждый из нас будет использовать результаты от ГИИ: написание статьей, подготовка презентаций и так до бесконечности. Но уповать сейчас на ИИ и сокращать людей будет явно избыточным.
— Повышать эффективность и безопасность
Практически все разработчики сейчас сфокусированы на том, чтобы ИИ-модели стали менее требовательными к количеству и качеству исходных данных, а также на повышении уровня безопасности — ИИ должен генерировать безопасный контент и быть устойчивым к провокациям.
— Осваивать ИИ в формате экспериментов, проведения пилотных проектов
Чтобы быть готовым к приходу действительно полезных решений, нужно следить за развитием технологии, пробовать ее, формировать компетенции. Это как с цифровизацией: вместо того, чтобы прыгать в омут с головой в дорогие решения, нужно поиграть с бюджетным или бесплатными инструментами. Благодаря этому, к моменту прихода технологии в массы:
— вы и ваша компания будете понимать, какие требования необходимо закладывать к коммерческим и дорогим решениям, и подойдёте к этому вопросу осознанно. А хорошее техническое задание — 50% успеха;
— сможете уже получить эффекты в краткосрочной перспективе, а значит, будет и мотивация идти дальше;
— команда повысит свои цифровые компетенции, что снимет ограничения и сопротивление по техническим причинам;
— будут исключены неверные ожидания, а значит, будет и меньше бесполезных затрат, разочарований, конфликтов.
— Трансформировать общение пользователя с ИИ
Подобную концепцию я закладываю в своего цифрового советника. Пользователю надо давать готовые формы, где он просто проставит нужные значения или отметит пункты. И уже эту форму с корректной обвязкой (промтом) отдавать ИИ. Либо глубоко интегрировать решения в уже существующие ИТ-инструменты: офисные приложения, браузеры, автоответчики в телефоне и т. д.
Но это требует тщательной проработки и понимания поведения, запросов пользователя, или их стандартизации. То есть либо это уже не копеечное решение, которое все равно требует затрат на разработку, либо мы теряем в гибкости.
— Разрабатывать узкоспециализированные модели
Как и с людьми, обучать ИИ всему — занятие очень трудозатратное и имеет низкую эффективность. Если же пойти по созданию узкоспециализированных решений на базе движков больших моделей, то и обучение можно свести к минимуму, и сама модель будет не слишком большой, и контент будет менее абстрактным, более понятным, и галлюцинаций будет меньше.
Наглядная демонстрация — люди. Кто добивается больших успехов и может решать сложные задачи? Тот, кто знает всё, или тот, кто фокусируется на своем направлении и развивается вглубь, знает различные кейсы, общается с другими экспертами и тратит тысячи часов на анализ своего направления?
Пример узкоспециализированного решения:
— советник для управления проектами;
— налоговый консультант;
— советник по бережливому производству;
— чат-бот по производственной безопасности или помощник специалиста производственной безопасности;
— чат-бот для ИТ-техподдержки.
Резюме
Хоть ГИИ пока только на стадии развития, потенциал у технологии большой.
Да, хайп вокруг технологии пройдет, инвестиции от бизнеса снизятся, появятся вопросы к ее целесообразности.
Например, уже 16 июня 2024 года Forbes опубликовали статью: «Зима искусственного интеллекта: стоит ли ждать падения инвестиций в AI».
Оригинал статьи доступен по QR-коду и гиперссылке.

В ней приводится интересная аналитика о циклах зимы и лета в развитии ИИ. Также приведены мнения Марвина Минского и Роджера Шанка, которые еще в далеком 1984 году на встрече американской ассоциации искусственного интеллекта (AAAI) описали механизм, состоящий из нескольких этапов и напоминающий цепную реакцию, которая приведет к новой зиме в ИИ.
Этап 1. Завышенные ожидания бизнеса и публики от методов искусственного интеллекта не оправдывают себя.
Этап 2. СМИ начинают выпускать скептические статьи.
Этап 3. Федеральные агентства и бизнес снижают финансирование научных и продуктовых исследований.
Этап 4. Ученые теряют интерес к AI, и темп развития технологии замедляется.
И мнение экспертов сбылось. В течение пары лет наступила ИИ-зима, а потеплело лишь в 2010-х годах. Прямо как в «Игре Престолов».
Сейчас же мы находимся на очередном пике. Он наступил в 2023-м после выхода ChatGPT. Даже в этой книге для понимания читателя я часто привожу и буду приводить примеры из области данной LLM, хотя это и частный случай ИИ, но очень понятный.
Далее в статье приводится анализ по циклу Минского и Шанка к текущей ситуации.
«Этап 1. Ожидания бизнеса и публики.
Всем очевидно, что ожидания революции от AI в повседневной жизни пока не оправдались:
— Google так и не смог полноценно трансформировать свой поиск. После года тестирования технология AI-supercharged Search Generative Experience получает смешанные отзывы пользователей.
— Голосовые ассистенты («Алиса», «Маруся» и др.), возможно, стали немного лучше, но их вряд ли можно назвать полноценными ассистентами, которым мы доверяем хоть сколько-нибудь ответственные решения.
— Чат-боты служб поддержки продолжают испытывать сложности в понимании запроса пользователя и раздражают ответами невпопад и общими фразами.
Этап 2. Реакция СМИ.
По запросу AI bubble «старый» поиск Google выдает статьи авторитетных изданий с пессимистичными заголовками:
— Пузырь хайпа вокруг искусственного интеллекта сдувается. Наступают сложные времена (The Washington Post).
— От бума до взрыва пузырь AI движется только в одном направлении (The Guardian).
— Крах фондового рынка: известный экономист предупреждает, что пузырь AI рушится (Business Insider).
Мое личное мнение: эти статьи недалеки от истины. Ситуация на рынке очень похожа на то, что было перед крахом доткомов в 2000-х. Рынок явно перегрет, тем более что 9 из 10 ИИ-проектов провальны. Сейчас бизнес-модель и экономическая модель почти всех ИИ-решений и проектов нежизнеспособна.
Этап 3. Финансирование.
Несмотря на нарастающий пессимизм, пока нельзя сказать, что финансирование разработок в сфере AI снижается. Крупнейшие IT-компании продолжают инвестировать миллиарды долларов в технологии, а ведущие научные конференции в области искусственного интеллекта получают рекордное число заявок на публикацию статей.
Таким образом, в классификации Минского и Шанка мы сейчас находимся между вторым и третьим этапом перехода к зиме искусственного интеллекта. Означает ли это, что «зима» неизбежна и скоро AI снова отойдет на второй план? На самом деле нет».
В заключении статьи приводится ключевой аргумент — ИИ слишком глубоко проникли в нашу жизнь, чтобы началась новая ИИ-зима:
— системы распознавания лиц в телефонах и метро используют нейросети для точной идентификации пользователя;
— переводчики типа Google Translate сильно выросли в качестве, перейдя от методов классической лингвистики к нейросетям;
— современные системы рекомендаций используют нейросети для точного моделирования предпочтений пользователя.
Особенно интересно мнение, что потенциал слабого ИИ не исчерпан, и несмотря на все проблемы сильного ИИ, он может приносить пользу. И я полностью согласен с этим тезисом.
Следующий шаг в развитии ГИИ — создание более новых и легких моделей, которым требуется меньше данных для обучения. Нужно только набраться терпения и постепенно изучать инструмент, формируя компетенции, чтобы потом использовать его потенциал в полной мере.
Глава 5. Регулирование ИИ
Активное развитие искусственного интеллекта (ИИ, AI) приводит к тому, что общество и государства становятся обеспокоенными и думают о том, как его обезопасить. А значит, ИИ будет регулироваться. Но давайте разберемся в этом вопросе детальнее, что происходит сейчас и чего ожидать в будущем.
Почему развитие ИИ вызывает беспокойство?
Какие факторы вызывают бурное беспокойство у государств и регуляторов?
— Возможности
Самый главный пункт, на который будут опираться все следующие — возможности. ИИ демонстрирует огромный потенциал: принятие решений, написание материалов, генерация иллюстраций, создание поддельных видео — список можно перечислять бесконечно. Мы еще не осознаем всего, что может ИИ. А ведь мы пока владеем слабым ИИ. На что будет способен общий ИИ (AGI) или суперсильный ИИ?
— Механизмы работы
У ИИ есть ключевая особенность — он способен строить взаимосвязи, которые не понимает человек. И благодаря этому он способен как совершать открытия, так и пугать людей. Даже создатели ИИ-моделей не знают, как именно принимает решения нейросеть, какой логике она подчиняется. Отсутствие предсказуемости делает чрезвычайно трудным устранение и исправление ошибок в алгоритмах работы нейросетей, что становится огромным барьером на пути внедрения ИИ. Например, в медицине ИИ не скоро доверят ставить диагнозы. Да, он будет готовить рекомендации врачу, но итоговое решение будет оставаться за человеком. То же самое и в управлении атомными станциями или любым другим оборудованием.
Главное, о чем переживают ученые при моделировании будущего — не посчитает ли нас сильный ИИ пережитком прошлого?
— Этическая составляющая
Для искусственного интеллекта нет этики, добра и зла. Также для ИИ нет понятия «здравый смысл». Он руководствуется только одним фактором — успешность выполнения задачи. Если для военных целей это благо, то в обычной жизни людей это будет пугать. Общество не готово жить в такой парадигме. Готовы ли мы принять решение ИИ, который скажет, что не нужно лечить ребенка или нужно уничтожить целый город, чтобы не допустить распространение болезни?
— Нейросети не могут оценить данные на реальность и логичность
Нейросети просто собирают данные и не анализируют факты, их связанность. А значит, ИИ можно манипулировать. Он полностью зависит от тех данных, которыми его обучают создатели. Могут ли люди доверять полностью корпорациям или стартапам? И даже если мы доверяем людям и уверены в интересах компании, можем ли мы быть знать наверняка, что не произошло сбоя или данные не были «отравлены» злоумышленниками? Например, с помощью создания огромного количества сайтов-клонов с недостоверной информацией или «вбросами».
— Недостоверные контент / обман / галюцинации
Иногда это просто ошибки из-за ограничения моделей, иногда галлюцинации (додумывания), а иногда это похоже и на вполне настоящий обман.
Так, исследователи из компании Anthropic обнаружили, что модели искусственного интеллекта можно научить обманывать людей вместо того, чтобы давать правильные ответы на их вопросы.
Исследователи из Anthropic в рамках одного из проектов поставили перед собой задачу установить, можно ли обучить модель ИИ обману пользователя или выполнению таких действий, как, например, внедрение эксплойта в изначально безопасный компьютерный код. Для этого специалисты обучили ИИ как этичному поведению, так и неэтичному — привили ему склонность к обману.
Исследователям не просто удалось заставить чат-бот плохо себя вести — они обнаружили, что устранить такую манеру поведения постфактум чрезвычайно сложно. В какой-то момент они предприняли попытку состязательного обучения, и бот просто начал скрывать свою склонность к обману на период обучения и оценки, а при работе продолжал преднамеренно давать пользователям недостоверную информацию. «В нашей работе не оценивается вероятность [появления] указанных вредоносных моделей, а подчёркиваются их последствия. Если модель демонстрирует склонность к обману из-за выравнивания инструментария или отравления модели, современные методы обучения средствам безопасности не будут гарантировать безопасности и даже могут создать ложное впечатление о неё наличии», — заключают исследователи. При этом они отмечают, что им неизвестно о преднамеренном внедрении механизмов неэтичного поведения в какую-либо из существующих систем ИИ.
— Социальная напряженность, расслоение общества и нагрузка на государство
ИИ создает не только благоприятные возможности для повышения эффективности и результативности, но и риски.
Развитие ИИ неизбежно приведет к автоматизации рабочих мест и изменению рынка. И да, часть людей примет этот вызов и станет еще образованнее, выйдет на новый уровень. Когда-то умение писать и считать было уделом элиты, а теперь рядовой сотрудник должен уметь делать сводные таблицы в excel и проводить простую аналитику.
Но часть людей не примет этого вызова и потеряет рабочие места. А это приведет к дальнейшему расслоению общества и увеличению социальной напряженности, что в свою очередь беспокоит и государства, ведь помимо политических рисков, это будет и ударом по экономике. Люди, которые потеряют рабочие места, будут обращаться за пособиями.
Так, 15 января 2024 Bloomberg опубликовали статью, в которой управляющий директор Международного Валютного Фонда Кристана Георгиева предполагает, что бурное развитие систем искусственного интеллекта в большей степени отразится на высокоразвитых экономиках мира, чем на странах с растущей экономикой и низким доходом на душу населения. В любом случае, искусственный интеллект затронет почти 40% рабочих мест в масштабах всей планеты. «В большинстве сценариев искусственный интеллект с высокой вероятностью ухудшит всеобщее неравенство, и это тревожная тенденция, которую регуляторы не должны упускать из виду, чтобы предотвратить усиление социальной напряжённости из-за развития технологий», — отметила глава МВФ в корпоративном блоге.
— Безопасность
Проблемы безопасности ИИ на слуху у всех. И если на уровне небольших локальных моделей решение есть (обучение на выверенных данных), то что делать с большими моделями (ChatGPT и т.п.) — непонятно. Злоумышленники постоянно находят способы, как взломать защиту ИИ, и заставить его, например, написать рецепт взрывчатки. И ведь мы пока даже не говорим про AGI.
Какие инициативы в 2023 — 2024 годах?
Этот блок я раскрою кратко. Подробнее и с ссылками на новости можно ознакомиться в статье по QR-коду и гиперссылке. Постепенно статья будет дополняться.

Призыв разработчиков ИИ весной 2023 года
Начало 2023 года было не только взлетом ChatGPT, но и началом борьбы за безопасность. Тогда вышло открытое письмо от Илона Маска, Стива Возняка и еще более тысячи экспертов и руководителей отрасли ИИ с призывом приостановить разработку продвинутого ИИ.
Организация Объединенных Наций
В июле 2023 года генеральный секретарь ООН Антониу Гутерриш поддержал идею создать на базе ООН орган, который бы сформулировал глобальные стандарты по регулированию сферы ИИ.
Такая площадка могла бы действовать по аналогии с Международным агентством по атомной энергии (МАГАТЭ), Международной организацией гражданской авиации (ИКАО) или Международной группой экспертов по изменению климата (МГЭИК). Также он обозначил пять целей и задач такого органа:
— помощь странам в получении максимальной пользы от ИИ;
— устранение существующих и будущих угроз;
— выработка и реализация международных механизмов мониторинга и контроля;
— сбор экспертных данных и их передача мировому сообществу;
— изучение ИИ для «ускорения устойчивого развития».
В июне 2023 года он также обращал внимание на то, что «ученые и эксперты призвали мир к действию, объявив искусственный интеллект экзистенциальной угрозой человечеству наравне с риском ядерной войны».
А еще раньше, 15 сентября 2021 года, верховный комиссар ООН по правам человека Мишель Бачелет призвала наложить мораторий на использование нескольких систем, использующих алгоритмы искусственного интеллекта.
Open AI
В конце 2023 года OpenAI (разработчик ChatGPT) объявила о создании стратегии по превентивному устранению потенциальных опасностей ИИ. Особое внимание уделяется предотвращению рисков, связанных с развитием технологий.
Эта группа будет работать вместе с командами:
— систем безопасности, которая занимается решением существующих проблем, таких как предотвращение расовых предубеждений в ИИ;
— Superalignment, которая изучает работу сильного ИИ и как он будет работать, когда превзойдет человеческий интеллект.
Концепция безопасности OpenAI также включает оценку рисков по следующим категориям: кибербезопасность, ядерная, химическая, биологическая угроза, убеждение и автономия модели.
Евросоюз
Весной 2023 года Европарламент предварительно согласовал закон под названием AI Act, который устанавливает правила и требования для разработчиков моделей искусственного интеллекта.
В основе лежит риск-ориентированный подход к ИИ, а сам закон определяет обязательства разработчиков и пользователей ИИ в зависимости от уровня риска, используемого ИИ.
Всего выделяют четыре категории систем ИИ: с минимальным, ограниченным, высоким и неприемлемым риском.
Минимальный риск — результаты работы ИИ прогнозируемы и никак не могут навредить пользователям. Компании и пользователи смогут использовать их бесплатно. Например, спам-фильтры и видеоигры.
Ограниченный риск — различные чат-боты. Например, ChatGPT и Midjourney. Их алгоритмы для доступа в ЕС должны будут пройти проверку на безопасность. Также они будут подчиняться конкретным обязательствам по обеспечению прозрачности, чтобы пользователи могли принимать осознанные решения, знать, что они взаимодействуют с машиной, и отключаться по желанию.
Высокий риск — специализированные ИИ-системы, которые оказывают влияние на людей. Например, решения в области медицины, образования и профессиональной подготовки, трудоустройства, управления персоналом, доступ к основным частным и государственным услугам и льготам, данные правоохранительных органов, данные миграционных и пограничных служб, данные институтов правосудия.
Поставщики и разработчики «высокорискового» ИИ обязаны:
— провести оценку риска и соответствия;
— зарегистрировать свои системы в европейской базе данных ИИ;
— обеспечить высокое качество данных, которые используются для обучения ИИ;
— обеспечить прозрачность системы и информированность пользователей о том, что они взаимодействуют с ИИ, а также обязательный надзор со стороны человека и возможность вмешательства в работу системы.
Неприемлемый риск — алгоритмы для выставления социального рейтинга или создания дипфейков, системы, использующие подсознательные или целенаправленные манипулятивные методы, эксплуатирующие уязвимости людей.
Системы ИИ с неприемлемым уровнем риска для безопасности будут запрещены.
Также компании, которые разрабатывают модели на базе генеративного ИИ (может создавать что-то новое на основе алгоритма), должны будут составить техническую документацию, соблюдать законодательство ЕС об авторском праве и подробно описывать контент, используемый для обучения. А наиболее продвинутые модели, которые представляют «системные риски», подвергнутся дополнительной проверке, включая сообщения о серьезных инцидентах, внедрение мер кибербезопасности и отчетность об энергоэффективности. И, конечно, разработчики обязаны информировать пользователей о том, что они взаимодействуют с ИИ, а не с человеком.
Также для ИИ запретили:
— сбор и обработку биометрических данных, в том числе в общественных местах в реальном времени, с исключением для правоохранительных органов и только после судебного разрешения;
— биометрическую категоризацию с использованием чувствительных характеристик (например, пол, раса, этническая принадлежность, гражданство, религия, политическая позиция);
— подготовку прогнозов для правоохранительных органов, которые основаны на профилировании, местоположении или прошлом криминальном поведении;
— распознавание эмоций в правоохранительных органах, пограничных службах, на рабочих местах и в учебных заведениях;
— неизбирательное извлечение биометрических данных из социальных сетей или видеозаписей с камер видеонаблюдения для создания баз данных распознавания лиц (нарушение прав человека и права на неприкосновенность частной жизни).
В декабре 2023 года этот закон был согласован окончательно.
США
В октябре 2023 года вышел указ президента США, согласно которому разработчики самых мощных систем ИИ должны делиться результатами тестирования на безопасность и другой важной информацией с правительством США. Также указ предусматривает разработку стандартов, инструментов и тестов, призванных помочь убедиться в безопасности систем ИИ.
Китай
Переговоры OpenAI, Anthropic и Cohere с китайскими экспертами
Американские компании OpenAI, Anthropic и Cohere, занимающиеся разработкой искусственного интеллекта, провели тайные дипломатические переговоры с китайскими экспертами в области ИИ.
Переговоры между председателем КНР Си Цзиньпинем и президентом США Джо Байденом
15 ноября 2023 года, во время саммита Азиатско-Тихоокеанского экономического сотрудничества (АТЭС) в Сан-Франциско, лидеры двух стран договорились о сотрудничестве в нескольких значительных сферах, в том числе в области разработки ИИ.
Правила по регулированию ИИ
В течение 2023 года китайские власти вместе с бизнесом разработали 24 новых правила регулирования ИИ (введены 15 августа 2023 года).
Цель — не препятствовать развитию технологий искусственного интеллекта, поскольку для страны эта отрасль крайне важна. Необходимо найти баланс между поддержкой отрасли и возможными последствиями развития ИИ-технологий и соответствующей продукции.
Сами правила можно прочитать по QR-коду и гиперссылке.

Сам документ также можно скачать по QR-коду и гиперссылке.

Как и в Европе, нужно регистрировать услуги и алгоритмы на базе искусственного интеллекта, а сгенерированный алгоритмами контент (в том числе фото и видео), нужно помечать.
Также создатели контента и алгоритмов должны будут проводить проверку безопасности своей продукции до ее вывода на рынок. Каким образом это будут реализовать — пока не определено.
Плюс ко всему, компании, связанные с ИИ-технологиями и генерированным контентом, должны иметь прозрачный и действенный механизм рассмотрения жалоб пользователей на услуги и контент.
При этом самих регуляторов будет семь, в том числе Государственная канцелярия интернет-информации КНР, министерство образования, министерство науки и технологий, национальная комиссия по развитию и реформам.
Декларация Блетчли
В ноябре 2023 года 28 стран, участвовавших в Первом международном саммите по безопасному ИИ, включая Соединенные Штаты, Китай и Европейский союз, подписали соглашение, известное как Декларация Блетчли.
Она призывает к международному сотрудничеству. Акцент сделан на регулировании «Пограничного искусственного интеллекта». Под ним понимают новейшие и наиболее мощные системы и ИИ-модели. Это вызвано опасениями, связанными с потенциальным использованием ИИ для терроризма, в преступной деятельности и для ведения войн, а также экзистенциальным риском, представляемым для человечества в целом.
Россия
По состоянию на начало 2024 года основными документами в сфере ИИ были:
— Указ Президента РФ от 10 октября 2019 г. №490 «О развитии искусственного интеллекта в Российской Федерации», который вводит Национальную стратегию развития искусственного интеллекта на период до 2030 года
— Федеральный закон от 24.04.2020 №123-ФЗ «О проведении эксперимента по установлению специального регулирования в целях создания необходимых условий для разработки и внедрения технологий искусственного интеллекта в субъекте Российской Федерации — городе федерального значения Москве и внесении изменений в статьи 6 и 10 Федерального закона «О персональных данных»
— Распоряжение Правительства Российской Федерации от 19.08.2020 г. №2129-р «Об утверждении Концепции развития регулирования отношений в сфере технологий искусственного интеллекта и робототехники до 2024 года»
— Ряд государственных стандартов по отраслям.
Интересным также выглядит предложение Центрального Банка Российской Федерации, который намерен поддержать риск-ориентированный принцип регулирования ИИ на финансовом рынке. Он выделил два направления: ответственность за вред, причиненный в результате применения технологии, и защиту авторских прав.
Пока (в 2024 году) ЦБ не видит необходимости в оперативной разработке отдельного регулирования использования ИИ финансовыми организациями. Но это и не исключает внедрение специальных требований в отдельных случаях.
Например, один законопроект устанавливает порядок обезличивания персональных данных для операторов, не являющихся государственными органами, а другой — дает возможность финансовым организациям при аутсорсинге функций, связанных с использованием облачных услуг, передавать для обработки информацию, составляющую банковскую тайну.
Главным ресурсом для отслеживания регуляторики в сфере ИИ является портал Искусственный интеллект в Российской Федерации. В частности, раздел Регуляторика.
Прогноз на будущее
Что же следует ожидать в будущем?
— Международный контроль и правила
Без сомнения, будут созданы международные органы для выявления ограничений и создания классификации ИИ-решений.
— Национальные органы контроля и правила
Государства будут создавать свои модели регулирования ИИ. В целом я согласен с выводами ЦБ РФ, но считаю, что появится больше подходов. Если их объединить, то вероятнее всего:
— определят запрещенные отрасли или типы ИИ-решений;
— для высокорискованных решений или отраслей будут созданы правила лицензирования и тестирования на безопасность, в том числе будут введены ограничения на возможности ИИ-решений;
— будут введены общие реестры, куда включат все ИИ-решения;
— определят поддерживаемые направления развития, для которых будут создаваться технологические и правовые песочницы;
— особое внимание будет уделяться работе с персональными данными и соблюдению авторского права.
Вероятнее всего, под наибольшие ограничения попадет использование ИИ в юриспруденции, рекламе, атомной энергетике, логистике.
Также будут создаваться отдельные регуляторные ведомства или комитеты. национальные органы контроля. Если посмотреть на пример Китая, то высоки риски того, что взаимодействие между различными ведомствами будет организовать тяжело. Следует ожидать что-то вроде Agile-ведомства, в которых соберутся представители разных отраслей и специализаций. Оно будет вырабатывать правила и контролировать отрасль.
— Лицензирование
Вероятнее всего, лицензирование будет основано на разграничениях по отраслям или областям применения и возможностях ИИ-решений.
Это самый очевидный способ классификации и оценки рисков. Разработчиков заставят документировать все возможности. Например, система только готовить рекомендации или способна отдавать управляющие команды для оборудования?
Также разработчиков заставят вести подробную документацию по системной архитектуре решений и применяемых типах нейросетей.
— Требования по контролю / экспертиза данных, на которых будут обучать ИИ
Основное направление в ИИ — предобученные и оптимизированные модели. Собственно, абревиатура GPT в chatGPT это и обозначает. И здесь мы уже видим требования о фиксации того, на каких исходных данных обучается ИИ. Это будет что-то вроде реестра метаданных / источников / каталогов данных.
Важно контролировать и фиксировать обратную связь, на которой обучается ИИ. То есть необходимо будет сохранять все логи и описывать механики сбора обратной связи. Одним из главных требований станет минимизация человеческого фактора, то есть автоматизация обратной связи.
Например, я, в цифровом советнике планирую собирать обратную связь по проекту не только от участников, но и на основе сравнения план/факта из учетных систем.
— Риск-ориентированных подход: использование песочниц и провокационного тестирования
Особое внимание будет уделено тестированию на безопасность. Здесь я вижу наиболее вероятной модель получения рейтингов безопасности для автомобилей. То есть ИИ будет проходить примерно то же самое, что сейчас происходит в краш-тестах автомобилей.
Другими словами, для каждого класса ИИ-решений (по возможностям, области применения) будут определяться недопустимые события и формироваться протоколы тестирования, которые должны пройти ИИ-решения. Затем ИИ-решения будут помещаться в изолированную среду и тестироваться по данным протоколам. Например, на технический взлом алгоритмов, устойчивость к провокациям на некорректное поведение (подмена данных, формирование запросов и т.д.).
Эти протоколы еще предстоит разработать, как и критерии соответствия этим протоколам.
Далее будет присваиваться рейтинг безопасности или соответствие требуемому классу.
Возможно, будут создаваться открытые программы и кибербитвы по поиску уязвимостей в промышленном и банковском ПО. То есть расширение текущих программ bug bounty и кибербитв.
— Маркировка и предупреждения
Весь контент, в том числе все рекомендации и продукты на основе ИИ будут обязаны иметь маркировку, что это продукт деятельности ИИ на основе нейросетей. Примерно, как предупреждающие изображения и надписи на упаковках сигарет.
В том числе таким образом будет решаться вопрос ответственности: предупреждая пользователя о риске, на него перекладывается ответственность за использование ИИ-решения. Например, даже полностью беспилотный автомобиль не снимет ответственности с водителя за ДТП.
— Риск-ориентированный подход: торможение развития сильного и суперсильного ИИ, расцвет локальных моделей
Исходя из темпов развития ИИ и анализа происходящего в сфере регулирования ИИ, можно полагать, что в мире будет развиваться риск-ориентированный подход к регулированию ИИ.
А развитие риск-ориентированного подхода в любом случае приведет к тому, что сильный и суперсильный ИИ будут признаны самыми опасными. Соответственно, и ограничений для больших и мощных моделей появится больше всего. Каждый шаг разработчиков будет контролироваться. Это приведет к тому, что затраты и трудности для разработки и внедрения вырастут в геометрической прогрессии. В итоге мы получим проблемы как для разработчиков, так и для пользователей, что снижает экономический потенциал таких решений.
При этом специализированныемодели на базе локальных и урезанных ИИ-моделей, которые могут немного, будут в зоне с наименьшим регулированием. Ну, а если эти ИИ будут построены на базе международных / национальных / отраслевых методологий и стандартов, то вместо ограничений им дадут субсидии.
В итоге сочетание таких «слабых» и ограниченных решений на базе ИИ-конструкторов с ИИ-оркестратором позволит обходить ограничения и решать бизнес-задачи. Пожалуй, узким местом тут станут сами ИИ-оркестраторы. Они попадут под категорию среднего риска и, скорее всего, их придется регистрировать.
Резюме
Период активного бесконтрольного развития ИИ подходит к концу. Да, до сильного ИИ еще далеко (по разным оценкам, 5—20 лет), но даже «слабый» или «пограничный» ИИ начнут регулировать. И это нормально.
Я в своей практике очень ценю теорию Адизеса, которая подсказывает, что на раннем этапе развития бизнеса лучше фокусироваться на производительности и поиске клиентов, но чем дальше, тем больше становятся нужными функции регулирования и коммуникации.
Также и тут. Технология прошла первые шаги, когда ей нужны были максимальная свобода и реклама (не побоюсь слова «хайп», поскольку крупные всемирные консалтинговые компании именно этим сейчас и занимаются относительно ИИ). Теперь же общество начинает думать о рисках и безопасности. Всё как в жизненном цикле организации — от стартапа с минимум правил (главное — найди клиента и выживи) до зрелой корпорации (тщательная работа с рисками, регламенты, правила и т.д.).
Очень важно сейчас — не останавливать развитие ИИ или занимать позицию «мы подождем». Во-первых, это высокоинтеллектуальная отрасль, и нужно готовить кадры, формировать компетенции (потом не будет таких ресурсов, чтобы их переманить). Во-вторых, чтобы эффективно что-то регулировать, нужно находиться в теме и глубоко понимать специфику. Тут точно так же, как с информационной безопасностью: попытка запретить всё приводит к параличу организаций и тому, что люди начинают искать другие каналы коммуникации, в итоге увеличивая риски. Поэтому сейчас и в ИБ идет развитие риск-ориентированного подхода, через выявление недопустимых событий, сценариев / процессов, которые к ним могут привести, и критериев, которые должны сработать, чтобы эти события произошли.
Поэтому ИИ будут развивать, но в изолированных средах. Только находясь «в теме», можно развиваться, получать прибыль и выстраивать гарантированную безопасность.
Глава 6. Безопасность ИИ
Недопустимые события, которые надо исключить
Эта глава посвящена тому, что нужно предусмотреть, чтобы злоумышленники не могли использовать ИИ-решения для причинения ущерба компаниям и отдельным людям.
Также нужно вспомнить вывод из предыдущей главы — ИИ-решения при оценке их безопасности будут помещаться в изолированную среду и проходить некий аналог краш-теста автомобиля. Здесь главная задача — понять, какие именно должны создаваться условия при таком тестировании. Первый шаг в этой цепочке — определение недопустимых событий, то есть таких инцидентов, которые ни в коем случае не должны произойти.
Для этого сначала определим, какой ущерб может быть вообще и какие последствия нежелательны?
Для обычных людей:
— угроза жизни или здоровью;
— «травля» в интернете и унижение достоинства личности;
— нарушение свободы, личной неприкосновенности и семейной тайны, утрата чести, в том числе нарушение тайны переписки, телефонных переговоров и т.д.;
— финансовый или иной материальный ущерб;
— нарушение конфиденциальности (утечка, разглашение) персональных данных;
— нарушение других конституционных прав.
Для организаций и бизнеса:
— потеря / хищение денег;
— необходимость дополнительных / незапланированных затрат на выплаты штрафов / неустоек / компенсаций;
— необходимость дополнительных / незапланированных затрат на закупку товаров, работ или услуг (в том числе закупка / ремонт / восстановление / настройка программного обеспечения и рабочего оборудования);
— нарушение штатного режима работы автоматизированной системы управления и/или управляемого объекта и/или процесса;
— срыв запланированной сделки с партнером и потеря клиентов, поставщиков;
— необходимость дополнительных / незапланированных затрат на восстановление деятельности;
— потеря конкурентного преимущества и снижение престижа;
— невозможность заключения договоров, соглашений;
— дискредитация работников;
— нарушение деловой репутации и утрата доверия;
— причинение имущественного ущерба;
— неспособность выполнения договорных обязательств;
— невозможность решения задач / выполнения функций или снижение эффективности решения задач / выполнения функций;
— необходимость изменения / перестроения внутренних процедур для достижения целей, решения задач / выполнения функций;
— принятие неправильных решений;
— простой информационных систем или проблемы связи;
— публикация недостоверной информации на веб-ресурсах организации;
— использование веб-ресурсов для распространения и управления вредоносным программным обеспечением;
— рассылка информационных сообщений с использованием вычислительных мощностей компании или от ее имени;
— утечка конфиденциальной информации, в том числе коммерческой тайны, секретов производства, инновационных подходов т. д.
Для государств:
— возникновение ущерба бюджетам государств, в том числе через снижение уровня дохода государственных организаций, корпораций или организаций с государственным участием;
— нарушение процессов проведения банковских операций;
— вредные воздействия на окружающую среду;
— прекращение или нарушение функционирования ситуационных центров;
— снижение показателей государственных оборонных заказов;
— нарушение и/или прекращение работы информационных систем в области обеспечения обороны страны, безопасности и правопорядка;
— публикация недостоверной социально значимой информации на веб-ресурсах, которая может привести к социальной напряженности, панике среди населения;
— нарушение штатного режима работы автоматизированной системы управления и управляемого объекта и/или процесса, если это ведет к выводу из строя технологических объектов, их компонентов;
— нарушение общественного правопорядка, возможность потери или снижения уровня контроля за общественным правопорядком;
— нарушение выборного процесса;
— отсутствие возможности оперативного оповещения населения о чрезвычайной ситуации;
— организация пикетов, забастовок, митингов и т.д.;
— массовые увольнения;
— увеличение количества жалоб в органы государственной власти или органы местного самоуправления;
— появление негативных публикаций в общедоступных источниках;
— создание предпосылок к внутриполитическому кризису;
— доступ к персональным данным сотрудников органов государственной власти и т.д.;
— доступ к системам и сетям с целью незаконного использования вычислительных мощностей;
— использование веб-ресурсов государственных органов для распространения и управления вредоносным программным обеспечением;
— утечка информации ограниченного доступа;
— непредоставление государственных услуг.
Сценарии возникновения недопустимых событий
Именно этот блок похож на гадание по кофейной гуще. Сценариев того, как можно использовать ИИ для нанесения ущерба, огромное количество. Порой это похоже на идеи фантастов о далеком будущем. Мы попробуем подойти к этой задаче концептуально.
Три варианта использования ИИ злоумышленниками
Для начала давайте разберемся, как ИИ могут использовать для атак на организации? Здесь можно выделить три основных сценария.
Первый и самый опасный, но пока нереализуемый — это создание автономного ИИ, который сам анализирует ИТ-инфраструктуру, собирает данные (в том числе о сотрудниках), ищет уязвимости, проводит атаку и заражение, а затем шифрует данные и крадет конфиденциальную информацию.
Второй — использование ИИ как вспомогательного инструмента и делегирование ему конкретных задач. Например, создание дипфейков и имитация голоса, проведение анализа периметра и поиск уязвимостей, сбор данных о событиях в организации и данных о первых лицах.
И третий сценарий — это воздействие на ИИ в компаниях с целью вызвать у них ошибку, спровоцировать на некорректное действие.
Подмена видео, голоса и биометрии
Давайте рассмотрим второй сценарий на примере подмены видео, голоса для атак с помощью социальной инженерии.
Истории про дипфейки слышали уже почти все — видео, где подставлялось лицо нужного человека, повторялась его мимика, а отличить такую подделку довольно сложно. Про подделку голоса хочу сказать отдельно. Несколько лет назад, чтобы подделать ваш голос, требовалось предоставить ИИ один-два часа записи вашей речи. Года два назад этот показатель снизился до нескольких минут. Ну, а в 2023 году компания Microsoft представила ИИ, которому достаточно уже трех секунд для подделки. А сейчас появляются инструменты, с помощью которых можно менять голос даже в онлайн режиме.
И если в 2018 году все это было скорее развлечением, то с 2021 стало активным инструментом для хакеров. Например, в январе 2021 года злоумышленники с помощью дипфейка сделали видеоролик, где основатель Dbrain приглашал всех на мастер-класс и предлагал перейти по ссылке, не относящейся к его компании. Цель мошенников состояла в завлечении новых клиентов на блокчейн-платформу.
Еще интересный кейс случился в марте того же 2021 года. Злоумышленники обманули государственную систему Китая, которая принимала и обрабатывала подтвержденные биометрией налоговые документы. Там ИИ использовался хитрее. Приложение запускало камеру на телефоне и записывало видео для подтверждения личности. Мошенники в свою очередь находили фото потенциальных жертв и с помощью ИИ превращали их в видео. И подходили они к этой задаче комплексно. Злоумышленники знали, у каких смартфонов есть необходимые аппаратные уязвимости, то есть, где можно запустить подготовленное видео без включения фронтальной камеры. В итоге ущерб составил 76,2 млн долларов США. После этого инцидента в Китае задумались о защите персональных данных и представили проект закона, в котором предлагается ввести штрафы за такие нарушения и утечку персональных данных в размере до 8 млн долларов США или 5% от годового дохода компании.
Еще пример из ОАЭ. Хакеры подделали голос директора компании и заставили сотрудника банка перевести деньги на мошеннические счета, убедив его, что это новые счета фирмы.
Бесплатный фрагмент закончился.
Купите книгу, чтобы продолжить чтение.